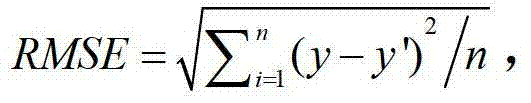 其中y′为预测值,y为真实值,n为预 测样本的组数。
其中y′为预测值,y为真实值,n为预 测样本的组数。 
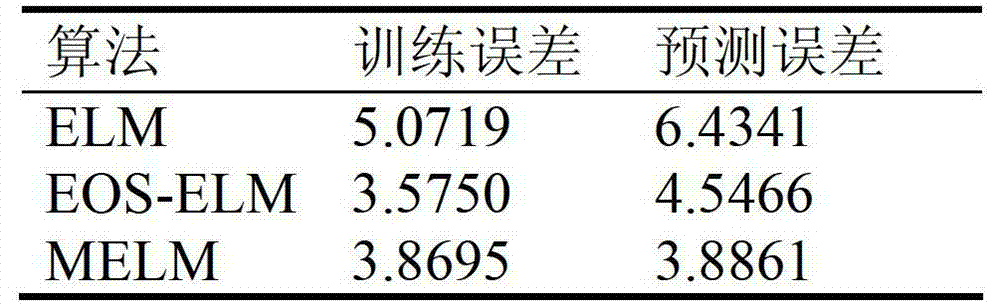


融合最小二乘向量机回归学习思想的改进极限学习机 出售状态:未出售 |
|||
|---|---|---|---|
| 提示:购买之前,请仔细核对自己的需求或询问客服! | |||
| 专利号 | 2012101415686 | 专利类型 | 发明专利 |
| 专利分类 | 教育教学 | 专利状态 | 已下证 |
| 出售价格 | ¥ 咨询客服 | 浏览 0 次 | |
服务承诺: 极速办理 安全有保障 办理不成功全额退款
手机查看购买
一种减少粉笔灰飞扬的黑板擦 |
|
|---|---|
| 专利号:201910183831X | 类型:发明专利 |
| 状态:已下证 | 分类:教育教学 |
| 入驻日期:2020/09/25 | 查看详情 |
一种人性化的自动翻书装置 |
|
|---|---|
| 专利号:2016103039290 | 类型:发明专利 |
| 状态:已下证 | 分类:教育教学 |
| 入驻日期:2020/09/23 | 查看详情 |
制图投影学习仪 |
|
|---|---|
| 专利号:2014101847852 | 类型:发明专利 |
| 状态:已下证 | 分类:教育教学 |
| 入驻日期:2020/06/05 | 查看详情 |
一种用于教学的多功能扩音装置 |
|
|---|---|
| 专利号:2018107883102 | 类型:发明专利 |
| 状态:授权未下证 | 分类:教育教学 |
| 入驻日期:2020/06/04 | 查看详情 |
可调节尺寸的绝缘子更换卡具 |
|
|---|---|
| 专利号:2016104555179 | 类型:发明专利 |
| 状态:已下证 | 分类:教育教学 |
| 入驻日期:2020/08/28 | 查看详情 |
一种数学教育用概率计算用演示设备 |
|
|---|---|
| 专利号:2017108798831 | 类型:发明专利 |
| 状态:已下证 | 分类:教育教学 |
| 入驻日期:2020/06/05 | 查看详情 |
一种宣传单用宣传板 |
|
|---|---|
| 专利号:2018105968996 | 类型:发明专利 |
| 状态:已下证 | 分类:教育教学 |
| 入驻日期:2020/09/25 | 查看详情 |
一种带隔板的圆形立柱椅 |
|
|---|---|
| 专利号:2016102460456 | 类型:发明专利 |
| 状态:已下证 | 分类:教育教学 |
| 入驻日期:2020/08/28 | 查看详情 |
一种教育学习用户外学习板 |
|
|---|---|
| 专利号:2018109930381 | 类型:发明专利 |
| 状态:授权未下证 | 分类:教育教学 |
| 入驻日期:2020/06/04 | 查看详情 |
一种提高体验感的教学机器人 |
|
|---|---|
| 专利号:201910317164X | 类型:发明专利 |
| 状态:已下证 | 分类:教育教学 |
| 入驻日期:2020/08/28 | 查看详情 |
英语阅读填空学习机 |
|
|---|---|
| 专利号:2015103200038 | 类型:发明专利 |
| 状态:已下证 | 分类:教育教学 |
| 入驻日期:2020/06/05 | 查看详情 |
一种教学智能机器人 |
|
|---|---|
| 专利号:2019110622032 | 类型:发明专利 |
| 状态:授权未下证 | 分类:教育教学 |
| 入驻日期:2020/06/04 | 查看详情 |
| 专利名: | 融合最小二乘向量机回归学习思想的改进极限学习机 | 出售状态: | 未出售 | ||
|---|---|---|---|---|---|
| 专利号: | 2012101415686 | 专利类型: | 发明专利 | 专利分类: | 教育教学 |
| 专利权人: | 联系人 | 出售价格: | 面议 | ||
其中y′为预测值,y为真实值,n为预 测样本的组数。 
答:如果在网站没有找到须要的专利,可联系客服提交自己的需求,工作人员会在十分钟内检索全网专利库,给满意的答复。
答:赋翼网所出售专利均经专利权人本人核实,专利真实有效,请放心购买。
答:在赋翼网购买专利,均为一次性收费(办理期间客户另提其他要求除外)。
答:跟赋翼网签订合作合同后,工作人员会立刻办理进行手续办理,买专利最快7天下证(根据办理速度不同,具体下证时间以国家知识产权局实际为准)。
答:如遇到付款后未能按照合同约定变更专利权人(含合同约定任何一项没有做到),经核实后赋翼网将在2个工作日内全额退款。
 京公网安备11011302007134
京公网安备11011302007134
 手机二维码
手机二维码