技术领域
本发明涉及一种视频信号的编码压缩方法,尤其是涉及一种深度视频编码方法。
背景技术
进入本世纪以来,随着数字2D(二维)视频技术日趋成熟,以及计算机、通信及网络技术的快速发展,引发了人们对新一代视频系统的强烈需求。现行的二维视频系统在表现自然场景时,难以满足用户的立体感和视点交互等的需求。三维视频系统由于能够提供立体感、视点交互性的全新视觉体验而越来越受到人们的欢迎,因此在无线视频通信、影视娱乐、数字动漫、虚拟战场、旅游观光、远程教学等领域有着广泛的应用前景。与单通道视频相比,三维视频由于包含了深度视频信息,其数据量要远远大于传统二维视频的数据量,因此在不影响三维视频主观质量的前提下,尽可能地降低三维视频的数据量以提高编码效率是一个亟需解决的问题。
然而,直接采用彩色视频编码方法对深度视频编码,会存在如下的问题:1)深度视频编码会对后续的虚拟视点绘制产生影响,其不同区域具有不同的深度敏感保真度(depth sensitivity fidelity),而传统的视频编码器并没有考虑这个因素;2)根据深度视频的数据特性,其纹理较为简单,包含较多的平坦区域,这样不同的区域根据其重要性应当分配不同的计算负载,而传统的视频编码器给所有的区域分配相同的计算负载。因此,如何更好地利用深度视频图像的深度敏感保真度,以保证获得最优编码效率、计算复杂度和绘制质量,是一个亟需解决的问题。
发明内容
本发明所要解决的技术问题是提供一种能够充分地消除深度视频的视觉冗余信息,并能够有效地降低深度视频编码复杂度的深度视频编码方法。
本发明解决上述技术问题所采用的技术方案为:一种深度视频编码方法,其特征在于包括以下步骤:
①将三维视频中t时刻的原始彩色视频图像和t时刻的原始深度视频图像对应记为{It,i(x,y)}和{Dt(x,y)},其中,i=1,2,3分别表示YUV颜色空间的三个分量,YUV颜色空间的第1个分量为亮度分量并记为Y、第2个分量为第一色度分量并记为U及第3个分量为第二色度分量并记为V,(x,y)表示{It,i(x,y)}和{Dt(x,y)}中的像素点的坐标位置,1≤x≤W,1≤y≤H,W表示{It,i(x,y)}和{Dt(x,y)}的宽度,H表示{It,i(x,y)}和{Dt(x,y)}的高度,It,i(x,y)表示{It,i(x,y)}中坐标位置为(x,y)的像素点的第i个分量的值,Dt(x,y)表示{Dt(x,y)}中坐标位置为(x,y)的像素点的深度值;
②根据{It,i(x,y)}中的每个像素点的第1个分量的值,获取{Dt(x,y)}中的每个像素点的左方向最大可容忍失真值和右方向最大可容忍失真值;然后根据{Dt(x,y)}中的每个像素点的左方向最大可容忍失真值和右方向最大可容忍失真值,提取出{Dt(x,y)}的最大可容忍失真分布图像,记为{St(x,y)},其中,St(x,y)表示{St(x,y)}中坐标位置为(x,y)的像素点的最大可容忍失真值;
③对{Dt(x,y)}和{St(x,y)}分别进行分子块处理,然后根据{St(x,y)}中的所有像素点的最大可容忍失真值的均值及{St(x,y)}中的每个子块中的所有像素点的最大可容忍失真值的均值,获取对{Dt(x,y)}中的每个子块进行编码的编码量化参数和宏块模式选择的率失真代价函数;
④采用HBP编码预测结构,并根据已确立的编码量化参数和宏块模式选择的率失真代价函数,对{Dt(x,y)}中的每个子块进行编码,完成{Dt(x,y)}的编码过程。
所述的步骤②的具体过程为:
②-1、将{Dt(x,y)}中当前待处理的像素点定义为当前像素点;
②-2、将当前像素点的坐标位置记为(x1,y1),如果1≤x1≤W且y1=1,则直接将当前像素点的横坐标作为当前像素点的左方向最大可容忍失真值,记为δl(x1,y1),如果1≤x1≤W且1<y1≤H,则在{It,i(x,y)}中位于坐标位置为(x1,y1)的像素点的水平左侧的所有像素点中,找出第1个分量的值与坐标位置为(x1,y1)的像素点的第1个分量的值相等的所有像素点,再计算找出的每个像素点的横坐标与坐标位置为(x1,y1)的像素点的横坐标x1的横坐标差值,最后将所有横坐标差值中值最小的横坐标差值作为当前像素点的左方向最大可容忍失真值,记为δl(x1,y1);同样,如果1≤x1≤W且y1=H,则直接将当前像素点的横坐标作为当前像素点的右方向最大可容忍失真值,记为δr(x1,y1),如果1≤x1≤W且1≤y1<H,则在{It,i(x,y)}中位于坐标位置为(x1,y1)的像素点的水平右侧的所有像素点中,找出第1个分量的值与坐标位置为(x1,y1)的像素点的第1个分量的值相等的所有像素点,再计算找出的每个像素点的横坐标与坐标位置为(x1,y1)的像素点的横坐标x1的横坐标差值,最后将所有横坐标差值中值最大的横坐标差值作为当前像素点的右方向最大可容忍失真值,记为δr(x1,y1);其中,1≤x1≤W,1≤y1≤H;
②-3、根据δl(x1,y1)和δr(x1,y1),确定当前像素点的最大可容忍失真值,记为St(x1,y1),St(x1,y1)=min(|δl(x1,y1)|,|δr(x1,y1)|),其中,min()为取最小值函数,符号“||”为取绝对值符号;
②-4、将{Dt(x,y)}中下一个待处理的像素点作为当前像素点,然后返回步骤②-2继续执行,直至{Dt(x,y)}中的所有像素点处理完毕,得到{Dt(x,y)}的最大可容忍失真分布图像,记为{St(x,y)},其中,St(x,y)表示{St(x,y)}中坐标位置为(x,y)的像素点的最大可容忍失真值。
所述的步骤③的具体过程为:
③-1、计算{St(x,y)}中的所有像素点的最大可容忍失真值的均值,记为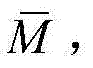 然后将{Dt(x,y)}和{St(x,y)}分别划分成
然后将{Dt(x,y)}和{St(x,y)}分别划分成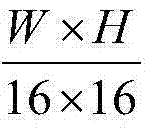 个互不重叠的尺寸大小为16×16的子块,将{Dt(x,y)}中当前待处理的第k个子块定义为当前第一子块,记为{ftD(x2,y2)},将{St(x,y)}中当前待处理的第k个子块定义为当前第二子块,记为{ftS(x2,y2)},其中,
个互不重叠的尺寸大小为16×16的子块,将{Dt(x,y)}中当前待处理的第k个子块定义为当前第一子块,记为{ftD(x2,y2)},将{St(x,y)}中当前待处理的第k个子块定义为当前第二子块,记为{ftS(x2,y2)},其中,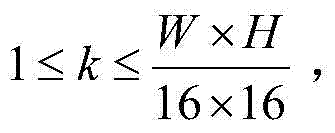 (x2,y2)表示{ftD(x2,y2)}和{ftS(x2,y2)}中的像素点的坐标位置,1≤x2≤16,1≤y2≤16,ftD(x2,y2)表示当前第一子块{ftD(x2,y2)}中坐标位置为(x2,y2)的像素点的深度值,ftS(x2,y2)表示当前第二子块{ftS(x2,y2)}中坐标位置为(x2,y2)的像素点的最大可容忍失真值;
(x2,y2)表示{ftD(x2,y2)}和{ftS(x2,y2)}中的像素点的坐标位置,1≤x2≤16,1≤y2≤16,ftD(x2,y2)表示当前第一子块{ftD(x2,y2)}中坐标位置为(x2,y2)的像素点的深度值,ftS(x2,y2)表示当前第二子块{ftS(x2,y2)}中坐标位置为(x2,y2)的像素点的最大可容忍失真值;
③-2、计算当前第二子块{ftS(x2,y2)}中的所有像素点的最大可容忍失真值的均值,记为Mt;
③-3、获取对当前第一子块ftD(x2,y2)进行编码的编码量化参数,记为QPt,其中,round()为四舍五入函数,QPbase为对{Dt(x,y)}进行编码的基本量化步长,exp()表示以自然基数e为底的指数函数,a、b和c为控制参数;
③-4、获取对当前第一子块ftD(x2,y2)进行编码的宏块模式选择的率失真代价函数,记为Jk,Jk=Dd+λV,k×DV+λR,k×Rd,其中,Dd表示以QPt对当前第一子块ftD(x2,y2)进行编码的编码失真,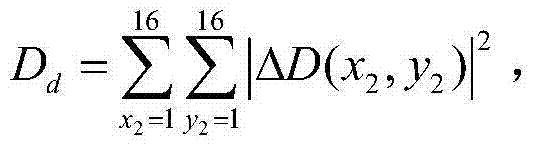 ΔD(x2,y2)表示以QPt对当前第一子块ftD(x2,y2)进行编码时当前第一子块ftD(x2,y2)中坐标位置为(x2,y2)的像素点的编码失真,Dv表示对以QPt对当前第一子块ftD(x2,y2)进行编码得到的解码第一子块进行虚拟视点图像绘制的绘制失真,
ΔD(x2,y2)表示以QPt对当前第一子块ftD(x2,y2)进行编码时当前第一子块ftD(x2,y2)中坐标位置为(x2,y2)的像素点的编码失真,Dv表示对以QPt对当前第一子块ftD(x2,y2)进行编码得到的解码第一子块进行虚拟视点图像绘制的绘制失真,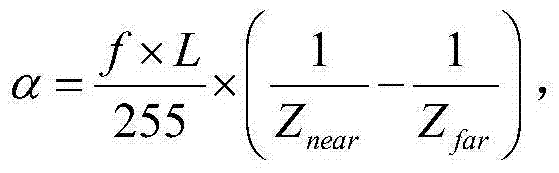 f表示水平相机阵列中各相机的水平焦距,L表示{It,i(x,y)}所在的视点与虚拟视点之间的基线距离,Znear表示最小的场景深度值,Zfar表示最大的场景深度值,
f表示水平相机阵列中各相机的水平焦距,L表示{It,i(x,y)}所在的视点与虚拟视点之间的基线距离,Znear表示最小的场景深度值,Zfar表示最大的场景深度值,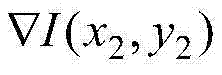 表示当前第一子块ftD(x2,y2)中坐标位置为(x2,y2)的像素点的梯度值,Rd表示以QPt对当前第一子块ftD(x2,y2)进行编码的码率,符号“||”为取绝对值符号,λV,k和λR,k为拉格朗日参数,
表示当前第一子块ftD(x2,y2)中坐标位置为(x2,y2)的像素点的梯度值,Rd表示以QPt对当前第一子块ftD(x2,y2)进行编码的码率,符号“||”为取绝对值符号,λV,k和λR,k为拉格朗日参数,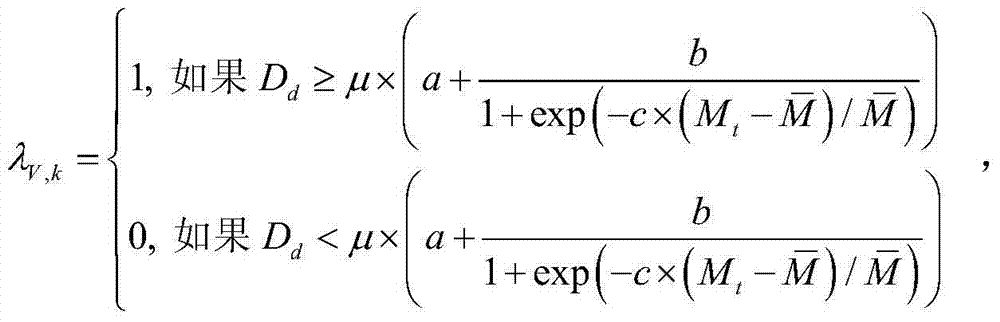 μ为调节参数,λR,k=(1+λV,k×α2×β)×λmode,β表示当前第一子块ftD(x2,y2)中的所有像素点的梯度的平方之和,,λmode表示拉格朗日参数,
μ为调节参数,λR,k=(1+λV,k×α2×β)×λmode,β表示当前第一子块ftD(x2,y2)中的所有像素点的梯度的平方之和,,λmode表示拉格朗日参数,
③-5、令k'=k+1,k=k',将{Dt(x,y)}中的下一个待处理的子块作为当前第一子块,将{St(x,y)}中的下一个待处理的子块作为当前第二子块,然后返回步骤③-2继续执行,直至{Dt(x,y)}和{St(x,y)}中的所有子块均处理完毕,其中,k'的初始值为0,k'=k+1和k=k'中的“=”为赋值符号。
与现有技术相比,本发明的优点在于:
1)本发明方法根据原始深度视频图像的最大可容忍失真分布图像,获取对深度视频图像中的每个子块进行编码的编码量化参数(对最大可容忍失真值较小的子块采用较小的量化步长进行编码,对最大可容忍失真值较大的子块采用较大的量化步长进行编码),这样在保证虚拟视点图像绘制性能的基础上,充分地消除了深度视频的视觉冗余信息,大大提高了深度视频图像的编码效率。
2)本发明方法根据原始深度视频图像的最大可容忍失真分布图像修改原始深度视频图像进行宏块层编码的率失真代价函数,对最大可容忍失真值较小的区域,在率失真代价函数中增加绘制失真这一项,而最大可容忍失真值较大的区域,则在率失真代价函数中去掉绘制失真这一项,这样在保证虚拟视点图像绘制性能的基础上,大大降低了深度视频的编码复杂度。
附图说明
图1为本发明方法的流程框图。
具体实施方式
以下结合附图实施例对本发明作进一步详细描述。
本发明提出的一种深度视频编码方法,其流程框图如图1所示,其包括以下步骤:
①将三维视频中t时刻的原始彩色视频图像和t时刻的原始深度视频图像对应记为{It,i(x,y)}和{Dt(x,y)},其中,i=1,2,3分别表示YUV颜色空间的三个分量,YUV颜色空间的第1个分量为亮度分量并记为Y、第2个分量为第一色度分量并记为U及第3个分量为第二色度分量并记为V,(x,y)表示{It,i(x,y)}和{Dt(x,y)}中的像素点的坐标位置,1≤x≤W,1≤y≤H,W表示{It,i(x,y)}和{Dt(x,y)}的宽度,H表示{It,i(x,y)}和{Dt(x,y)}的高度,It,i(x,y)表示{It,i(x,y)}中坐标位置为(x,y)的像素点的第i个分量的值,Dt(x,y)表示{Dt(x,y)}中坐标位置为(x,y)的像素点的深度值。
②根据{It,i(x,y)}中的每个像素点的第1个分量的值,获取{Dt(x,y)}中的每个像素点的左方向最大可容忍失真值和右方向最大可容忍失真值;然后根据{Dt(x,y)}中的每个像素点的左方向最大可容忍失真值和右方向最大可容忍失真值,提取出{Dt(x,y)}的最大可容忍失真分布图像,记为{St(x,y)},其中,St(x,y)表示{St(x,y)}中坐标位置为(x,y)的像素点的最大可容忍失真值。
在此具体实施例中,步骤②的具体过程为:
②-1、将{Dt(x,y)}中当前待处理的像素点定义为当前像素点。
②-2、将当前像素点的坐标位置记为(x1,y1),如果1≤x1≤W且y1=1,则直接将当前像素点的横坐标作为当前像素点的左方向最大可容忍失真值,记为δl(x1,y1),如果1≤x1≤W且1<y1≤H,则在{It,i(x,y)}中位于坐标位置为(x1,y1)的像素点的水平左侧的所有像素点中,找出第1个分量的值与坐标位置为(x1,y1)的像素点的第1个分量的值相等的所有像素点,再计算找出的每个像素点的横坐标与坐标位置为(x1,y1)的像素点的横坐标x1的横坐标差值,最后将所有横坐标差值中值最小的横坐标差值作为当前像素点的左方向最大可容忍失真值,记为δl(x1,y1);同样,如果1≤x1≤W且y1=H,则直接将当前像素点的横坐标作为当前像素点的右方向最大可容忍失真值,记为δr(x1,y1),如果1≤x1≤W且1≤y1<H,则在{It,i(x,y)}中位于坐标位置为(x1,y1)的像素点的水平右侧的所有像素点中,找出第1个分量的值与坐标位置为(x1,y1)的像素点的第1个分量的值相等的所有像素点,再计算找出的每个像素点的横坐标与坐标位置为(x1,y1)的像素点的横坐标x1的横坐标差值,最后将所有横坐标差值中值最大的横坐标差值作为当前像素点的右方向最大可容忍失真值,记为δr(x1,y1);其中,1≤x1≤W,1≤y1≤H。
②-3、根据δl(x1,y1)和δr(x1,y1),确定当前像素点的最大可容忍失真值,记为St(x1,y1),St(x1,y1)=min(|δl(x1,y1)|,|δr(x1,y1)|),其中,min()为取最小值函数,符号“||”为取绝对值符号。
②-4、将{Dt(x,y)}中下一个待处理的像素点作为当前像素点,然后返回步骤②-2继续执行,直至{Dt(x,y)}中的所有像素点处理完毕,得到{Dt(x,y)}的最大可容忍失真分布图像,记为{St(x,y)},其中,St(x,y)表示{St(x,y)}中坐标位置为(x,y)的像素点的最大可容忍失真值。
③对{Dt(x,y)}和{St(x,y)}分别进行分子块处理,然后根据{St(x,y)}中的所有像素点的最大可容忍失真值的均值及{St(x,y)}中的每个子块中的所有像素点的最大可容忍失真值的均值,获取对{Dt(x,y)}中的每个子块进行编码的编码量化参数和宏块模式选择的率失真代价函数。
在此具体实施例中,步骤③的具体过程为:
③-1、计算{St(x,y)}中的所有像素点的最大可容忍失真值的均值,记为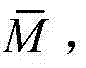 然后将{Dt(x,y)}和{St(x,y)}分别划分成
然后将{Dt(x,y)}和{St(x,y)}分别划分成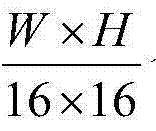 个互不重叠的尺寸大小为16×16的子块,将{Dt(x,y)}中当前待处理的第k个子块定义为当前第一子块,记为{ftD(x2,y2)},将{St(x,y)}中当前待处理的第k个子块定义为当前第二子块,记为{ftS(x2,y2)},其中,
个互不重叠的尺寸大小为16×16的子块,将{Dt(x,y)}中当前待处理的第k个子块定义为当前第一子块,记为{ftD(x2,y2)},将{St(x,y)}中当前待处理的第k个子块定义为当前第二子块,记为{ftS(x2,y2)},其中,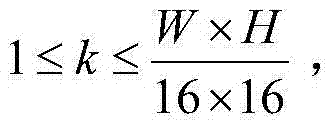 (x2,y2)表示{ftD(x2,y2)}和{ftS(x2,y2)}中的像素点的坐标位置,1≤x2≤16,1≤y2≤16,ftD(x2,y2)表示当前第一子块{ftD(x2,y2)}中坐标位置为(x2,y2)的像素点的深度值,ftS(x2,y2)表示当前第二子块{ftS(x2,y2)}中坐标位置为(x2,y2)的像素点的最大可容忍失真值。
(x2,y2)表示{ftD(x2,y2)}和{ftS(x2,y2)}中的像素点的坐标位置,1≤x2≤16,1≤y2≤16,ftD(x2,y2)表示当前第一子块{ftD(x2,y2)}中坐标位置为(x2,y2)的像素点的深度值,ftS(x2,y2)表示当前第二子块{ftS(x2,y2)}中坐标位置为(x2,y2)的像素点的最大可容忍失真值。
③-2、计算当前第二子块{ftS(x2,y2)}中的所有像素点的最大可容忍失真值的均值,记为Mt。
③-3、获取对当前第一子块ftD(x2,y2)进行编码的编码量化参数,记为QPt,其中,round()为四舍五入函数,QPbase为对{Dt(x,y)}进行编码的基本量化步长,exp()表示以自然基数e为底的指数函数,e=2.71828183,a、b和c为控制参数,在本实施例中取a=0.7、b=0.6和c=4。
③-4、获取对当前第一子块ftD(x2,y2)进行编码的宏块模式选择的率失真代价函数,记为Jk,Jk=Dd+λV,k×DV+λR,k×Rd,其中,Dd表示以QPt对当前第一子块ftD(x2,y2)进行编码的编码失真,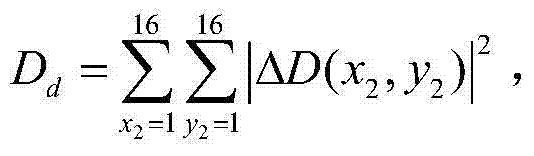 ΔD(x2,y2)表示以QPt对当前第一子块ftD(x2,y2)进行编码时当前第一子块ftD(x2,y2)中坐标位置为(x2,y2)的像素点的编码失真,Dv表示对以QPt对当前第一子块ftD(x2,y2)进行编码得到的解码第一子块进行虚拟视点图像绘制的绘制失真,
ΔD(x2,y2)表示以QPt对当前第一子块ftD(x2,y2)进行编码时当前第一子块ftD(x2,y2)中坐标位置为(x2,y2)的像素点的编码失真,Dv表示对以QPt对当前第一子块ftD(x2,y2)进行编码得到的解码第一子块进行虚拟视点图像绘制的绘制失真,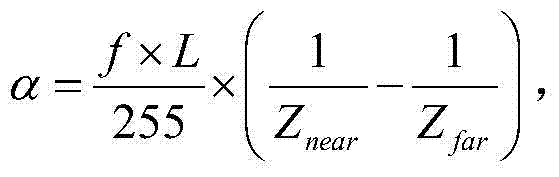 f表示水平相机阵列中各相机的水平焦距,L表示{It,i(x,y)}所在的视点与虚拟视点之间的基线距离,Znear表示最小的场景深度值,Zfar表示最大的场景深度值,f、L、Znear和Zfar的值根据具体的测试序列确定,
f表示水平相机阵列中各相机的水平焦距,L表示{It,i(x,y)}所在的视点与虚拟视点之间的基线距离,Znear表示最小的场景深度值,Zfar表示最大的场景深度值,f、L、Znear和Zfar的值根据具体的测试序列确定,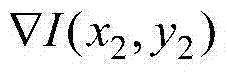 表示当前第一子块ftD(x2,y2)中坐标位置为(x2,y2)的像素点的梯度值,Rd表示以QPt对当前第一子块ftD(x2,y2)进行编码的码率,符号“||”为取绝对值符号,λV,k和λR,k为拉格朗日参数,
表示当前第一子块ftD(x2,y2)中坐标位置为(x2,y2)的像素点的梯度值,Rd表示以QPt对当前第一子块ftD(x2,y2)进行编码的码率,符号“||”为取绝对值符号,λV,k和λR,k为拉格朗日参数,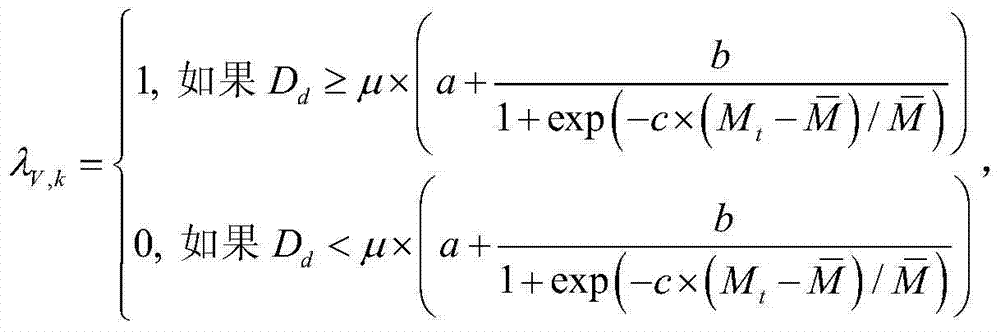 μ为调节参数,在本实施例中取μ=0.5,λR,k=(1+λV,k×α2×β)×λmode,β表示当前第一子块ftD(x2,y2)中的所有像素点的梯度的平方之和,
μ为调节参数,在本实施例中取μ=0.5,λR,k=(1+λV,k×α2×β)×λmode,β表示当前第一子块ftD(x2,y2)中的所有像素点的梯度的平方之和,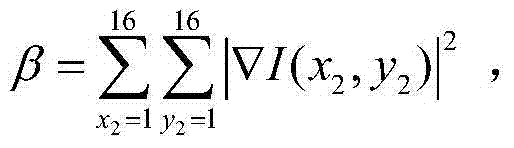 λmode表示拉格朗日参数,
λmode表示拉格朗日参数,
由于Dd会对后续的虚拟视点图像绘制产生影响,因此本发明方法根据Dd和{It,i(x,y)}估计得到Dv,最优宏块模式选择可用方程表示为: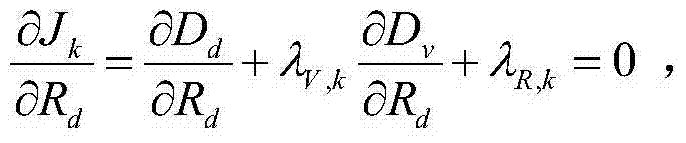 这样参数λR,k的计算公式为:
这样参数λR,k的计算公式为: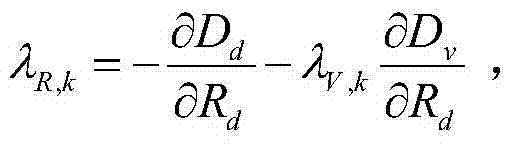
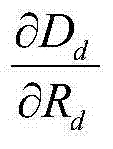 表示对Dd进行求导操作,
表示对Dd进行求导操作,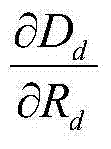 直接表示为:
直接表示为: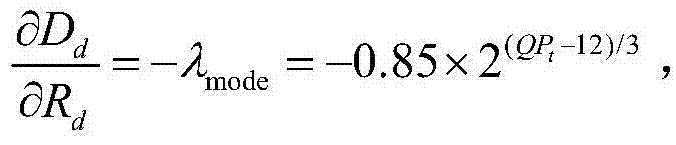
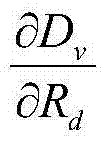 表示对Dd进行求导操作,
表示对Dd进行求导操作,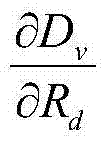 近似表示为:
近似表示为:
而则再根据估计得到的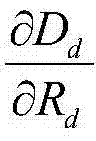 和
和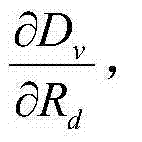 参数λR,k可表示为:λR,k=(1+λV,k×α2×β)×λmode。
参数λR,k可表示为:λR,k=(1+λV,k×α2×β)×λmode。
③-5、令k'=k+1,k=k',将{Dt(x,y)}中的下一个待处理的子块作为当前第一子块,将{St(x,y)}中的下一个待处理的子块作为当前第二子块,然后返回步骤③-2继续执行,直至{Dt(x,y)}和{St(x,y)}中的所有子块均处理完毕,其中,k'的初始值为0,k'=k+1和k=k'中的“=”为赋值符号。
④采用公知的HBP编码预测结构,并根据已确立的编码量化参数和宏块模式选择的率失真代价函数,对{Dt(x,y)}中的每个子块进行编码,完成{Dt(x,y)}的编码过程。
以下就利用本发明方法与现有的深度视频编码方法分别对“Balloons”、“BookArrival”、“GT Fly”、“Kendo”、“Newspaper”、“Poznan Street”和“Undo Dance”三维视频测试序列中的深度视频进行编码的编码复杂度进行比较。
在本实施例中,“Balloons”三维立体视频测试序列的f、Znear和Zfar分别为2241.25607、448.251214和11206.280350、“Book Arrival”三维立体视频测试序列的f、Znear和Zfar分别为1399.466666666666、23.175928和54.077165、“GT Fly”三维立体视频测试序列的f、Znear和Zfar分别为70625、662000和2519.92835,“Kendo”三维立体视频测试序列的f、Znear和Zfar分别为448.251214、11206.280350和2241.25607,“Newspaper”三维立体视频测试序列的f、Znear和Zfar分别为2929.4940521927465、-2715.181648和-9050.605493,“Poznan Street”三维立体视频测试序列的f、Znear和Zfar分别为1732.875727、-34.506386和-2760.510889,“Undo Dance”三维立体视频测试序列的f、Znear和Zfar分别为2302.852541609168、2289和213500。
在现有的深度视频编码方法中,对原始深度视频图像进行宏块层编码的率失真代价函数为Jk=Dd+DV+λmode×Rd,DV通过对每个宏块都进行虚拟视点图像绘制来计算得到,其计算复杂度较高。表1给出了利用本发明方法与现有的深度视频编码方法分别对上述7个三维视频测试序列中的深度视频进行编码的编码复杂度比较,从表1中所列的数据可以看出,采用本发明方法编码的编码复杂度与采用现有的深度视频编码方法编码的编码复杂度相比,最低平均能降低10.98%左右,最高平均能降低26.07%左右,足以说明本发明方法是有效可行的。
表1利用本发明方法与现有的深度视频编码方法进行深度视频编码的编码复杂度比较

 手机二维码
手机二维码 京公网安备11011302007134
京公网安备11011302007134