技术领域
本发明涉及一种图像处理方法,尤其是涉及一种深度图像的后处理方法。
背景技术
三维视频(Three-Dimensional Video,3DV)是一种先进的视觉模式,它使人们在屏幕上观看图像时富有立体感和沉浸感,可以满足人们从不同角度观看三维(3D)场景的需求。典型的三维视频系统如图1所示,其主要包括视频捕获、视频编码、传输解码、虚拟视点绘制和交互显示等模块。视频加深度(video plus depth,V+D)是常用的3D场景信息表示方式,其在彩色视频基础上增加了对应视点的深度信息,可以通过基于深度图像的绘制来快速生成虚拟视点图像。
现有的深度图像预处理方法更多的是考虑如何对深度图像进行平滑,以提升编码和绘制性能,而经过压缩后的深度图像,深度结构信息会发生严重的退化,如果直接用退化的深度图像进行虚拟视点绘制,则在绘制图像中会出现严重的几何失真,因此如何通过对深度图像进行后处理操作,从退化的深度图像中恢复出深度结构信息,以提高虚拟视点绘制性能是一个亟需解决的问题。
发明内容
本发明所要解决的技术问题是提供一种深度图像的后处理方法,其能够充分地恢复出失真深度图像的深度结构信息,能够有效地提高虚拟视点图像的绘制性能。
本发明解决上述技术问题所采用的技术方案为:一种深度图像的后处理方法,其特征在于它的处理过程为:首先,在解码端获取解码得到的彩色图像和对应的深度图像;然后,利用基于置信区间的交点规则确定解码得到的深度图像中的每个像素点的邻域窗口;接着,通过最小化逼近多项式的均方误差估计解码得到的深度图像中的每个像素点的深度值,得到深度估计图像;最后,采用加权模式滤波器对深度估计图像中的每个像素点进行滤波处理,得到深度滤波图像,该深度滤波图像用于虚拟视点图像的绘制。
本发明的深度图像的后处理方法,它具体包括以下步骤:
①在解码端,将解码得到的t时刻的彩色图像记为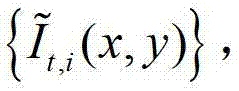 将解码得到的t时刻的深度图像记为
将解码得到的t时刻的深度图像记为 其中,i=1,2,3分别表示YUV颜色空间的三个分量,YUV颜色空间的第1个分量为亮度分量并记为Y、第2个分量为第一色度分量并记为U及第3个分量为第二色度分量并记为V,(x,y)表示彩色图像和深度图像中的像素点的坐标位置,1≤x≤W,1≤y≤H,W表示彩色图像和深度图像的宽度,H表示彩色图像和深度图像的高度,
其中,i=1,2,3分别表示YUV颜色空间的三个分量,YUV颜色空间的第1个分量为亮度分量并记为Y、第2个分量为第一色度分量并记为U及第3个分量为第二色度分量并记为V,(x,y)表示彩色图像和深度图像中的像素点的坐标位置,1≤x≤W,1≤y≤H,W表示彩色图像和深度图像的宽度,H表示彩色图像和深度图像的高度,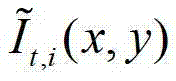 表示
表示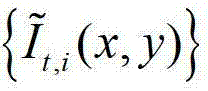 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,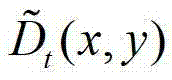 表示
表示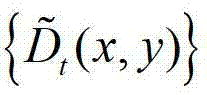 中坐标位置为(x,y)的像素点的深度值;
中坐标位置为(x,y)的像素点的深度值;
②通过采用在不同卷积方向上的多个不同尺度的多项式核函数分别对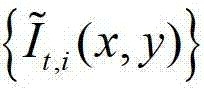 进行卷积操作,获取
进行卷积操作,获取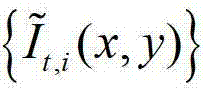 中的每个像素点在不同卷积方向上的多个不同尺度各自的置信区间的交点,然后确定
中的每个像素点在不同卷积方向上的多个不同尺度各自的置信区间的交点,然后确定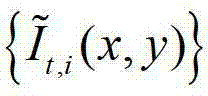 中的每个像素点在不同卷积方向上的最优尺度,再将由
中的每个像素点在不同卷积方向上的最优尺度,再将由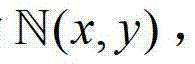 中的每个像素点在不同卷积方向上的最优尺度确立的形状区域作为
中的每个像素点在不同卷积方向上的最优尺度确立的形状区域作为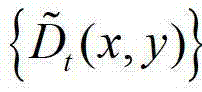 中对应像素点的邻域窗口,将
中对应像素点的邻域窗口,将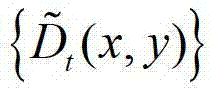 中坐标位置为(x,y)的像素点的邻域窗口记为将
中坐标位置为(x,y)的像素点的邻域窗口记为将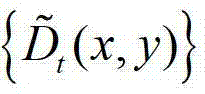 中的所有像素点的邻域窗口的集合记为
中的所有像素点的邻域窗口的集合记为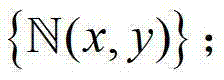
③根据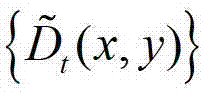 中的每个像素点的邻域窗口,通过最小化逼近多项式的均方误差估计
中的每个像素点的邻域窗口,通过最小化逼近多项式的均方误差估计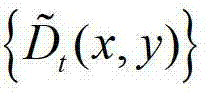 中的每个像素点的深度值,得到深度估计图像,记为
中的每个像素点的深度值,得到深度估计图像,记为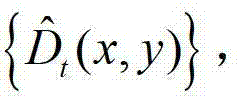 其中,
其中,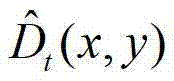 表示
表示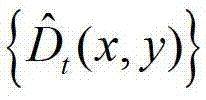 中坐标位置为(x,y)的像素点的深度值;
中坐标位置为(x,y)的像素点的深度值;
④采用加权模式滤波器对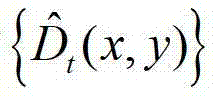 中的每个像素点进行滤波处理,得到深度滤波图像,记为
中的每个像素点进行滤波处理,得到深度滤波图像,记为 将
将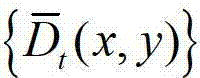 作为最终后处理得到的用于绘制虚拟视点图像的深度图像,其中,
作为最终后处理得到的用于绘制虚拟视点图像的深度图像,其中,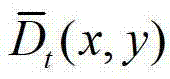 表示
表示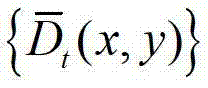 中坐标位置为(x,y)的像素点的深度值。
中坐标位置为(x,y)的像素点的深度值。
所述的步骤②的具体过程为:
②-1、将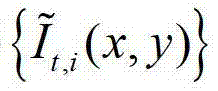 中当前待处理的像素点定义为当前像素点;
中当前待处理的像素点定义为当前像素点;
②-2、假设当前像素点的坐标位置为(x1,y1),其中,1≤x1≤W,1≤y1≤H;
②-3、采用在不同卷积方向上的多个不同尺度的多项式核函数分别对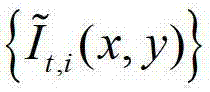 进行卷积操作,得到当前像素点在不同卷积方向上的多个不同尺度各自对应的定向估计值,将当前像素点在第k个卷积方向θk上的第j个尺度hj对应的定向估计值记为其中,1≤k≤K,K表示设定的卷积方向的个数,1≤j≤J,J表示设定的尺度的个数,
进行卷积操作,得到当前像素点在不同卷积方向上的多个不同尺度各自对应的定向估计值,将当前像素点在第k个卷积方向θk上的第j个尺度hj对应的定向估计值记为其中,1≤k≤K,K表示设定的卷积方向的个数,1≤j≤J,J表示设定的尺度的个数,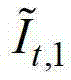 表示
表示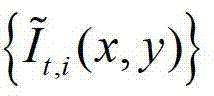 的第1个分量的函数表示形式,符号“*”为卷积操作符号,
的第1个分量的函数表示形式,符号“*”为卷积操作符号,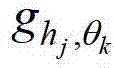 表示当前像素点在第k个卷积方向θk上的第j个尺度hj的多项式核函数,
表示当前像素点在第k个卷积方向θk上的第j个尺度hj的多项式核函数,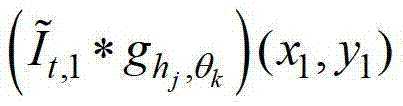 表示采用
表示采用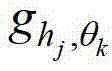 对
对 中坐标位置为(x1,y1)的像素点的第1个分量进行卷积操作,px-=x1-hjcos(θk),px+=x1+hjcos(θk),py-=y1-hjsin(θk),py+=y1+hjsin(θk),
中坐标位置为(x1,y1)的像素点的第1个分量进行卷积操作,px-=x1-hjcos(θk),px+=x1+hjcos(θk),py-=y1-hjsin(θk),py+=y1+hjsin(θk),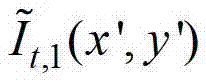 表示
表示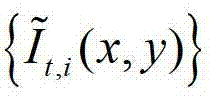 中坐标位置为(x′,y′)的像素点的第1个分量的值,
中坐标位置为(x′,y′)的像素点的第1个分量的值,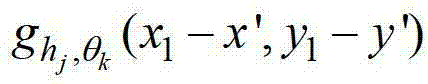 表示
表示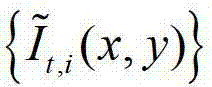 中坐标位置为(x1-x′,y1-y′)的像素点在第k个卷积方向θk上的第j个尺度hj的多项式核函数值,为的转置矩阵,
中坐标位置为(x1-x′,y1-y′)的像素点在第k个卷积方向θk上的第j个尺度hj的多项式核函数值,为的转置矩阵,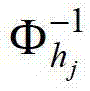 为
为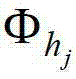 的逆矩阵;
的逆矩阵;
②-4、计算当前像素点在不同卷积方向上的多个不同尺度各自对应的置信区间的交点,将当前像素点在第k个卷积方向θk上的第j个尺度hj对应的置信区间的交点记为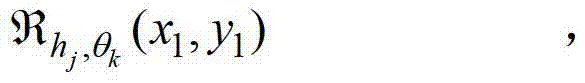
 其中,符号“∩”为求交集操作符号,1≤l≤j,
其中,符号“∩”为求交集操作符号,1≤l≤j,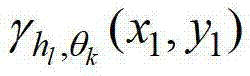 表示当前像素点在第k个卷积方向θk上的第l个尺度hl对应的定向估计值,
表示当前像素点在第k个卷积方向θk上的第l个尺度hl对应的定向估计值,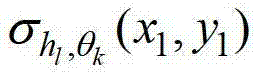 为
为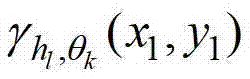 的标准差,Γ为控制置信区间范围的参数,此处符号“[]”为区间表示符号。
的标准差,Γ为控制置信区间范围的参数,此处符号“[]”为区间表示符号。
②-5、根据当前像素点在不同卷积方向上的多个不同尺度各自对应的置信区间的交点,获取当前像素点在不同卷积方向上的最优尺度,对于第k个卷积方向θk,从当前像素点在第k个卷积方向θk上的多个不同尺度各自对应的置信区间的交点中找出非空的最大值,将该最大值对应的尺度作为当前像素点在第k个卷积方向θk上的最优尺度。
②-6、将由当前像素点在不同卷积方向上的最优尺度确立的形状区域作为当前像素点的邻域窗口,记为
②-7、将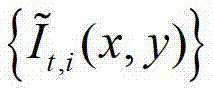 中下一个待处理的像素点作为当前像素点,然后返回步骤②-2继续执行,直至
中下一个待处理的像素点作为当前像素点,然后返回步骤②-2继续执行,直至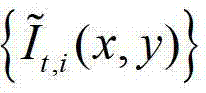 中的所有像素点处理完毕,获得
中的所有像素点处理完毕,获得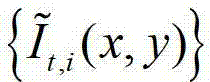 中的每个像素点的邻域窗口,再将
中的每个像素点的邻域窗口,再将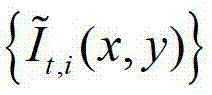 中的每个像素点的邻域窗口作为
中的每个像素点的邻域窗口作为 中对应像素点的邻域窗口,将
中对应像素点的邻域窗口,将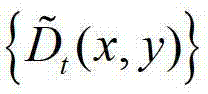 中的所有像素点的邻域窗口的集合记为
中的所有像素点的邻域窗口的集合记为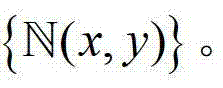
所述的步骤②-3中取K=8,则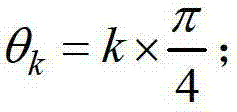 所述的步骤②-3中取J=6,并取h1=1,h2=2,h3=3,h4=5,h5=7,h6=11。
所述的步骤②-3中取J=6,并取h1=1,h2=2,h3=3,h4=5,h5=7,h6=11。
所述的步骤②-4中取Γ=1.05。
所述的步骤③的具体过程为:
③-1、将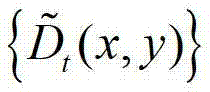 中当前待处理的像素点定义为当前像素点;
中当前待处理的像素点定义为当前像素点;
③-2、假设当前像素点的坐标位置为p,将当前像素点的邻域窗口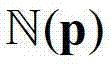 内的各个像素点的深度值分别记为y1,...,yN,其中,N表示
内的各个像素点的深度值分别记为y1,...,yN,其中,N表示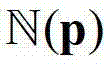 内的像素点的个数,y1表示
内的像素点的个数,y1表示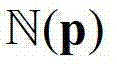 内的第1个像素点的深度值,yN表示
内的第1个像素点的深度值,yN表示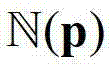 内的第N个像素点的深度值;
内的第N个像素点的深度值;
③-3、令y=[y1,...,yN]T,然后根据y=[y1,...,yN]T和估计当前像素点的深度值,得到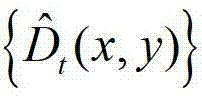 中与当前像素点相对应的像素点的深度值,记为
中与当前像素点相对应的像素点的深度值,记为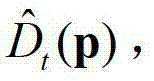
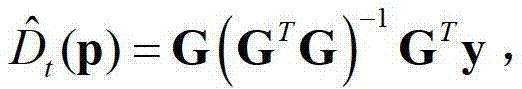 其中,y为N×1维矩阵,G为N×3维矩阵,GT为G的转置矩阵,(GTG)-1为GTG的逆矩阵;
其中,y为N×1维矩阵,G为N×3维矩阵,GT为G的转置矩阵,(GTG)-1为GTG的逆矩阵;
③-4、将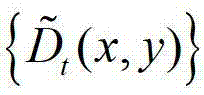 中下一个待处理的像素点作为当前像素点,然后返回步骤③-2继续执行,直至
中下一个待处理的像素点作为当前像素点,然后返回步骤③-2继续执行,直至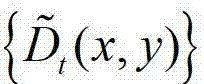 中的所有像素点处理完毕,得到深度估计图像
中的所有像素点处理完毕,得到深度估计图像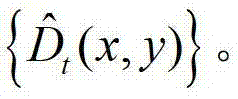
所述的步骤④的具体过程为:
④-1、将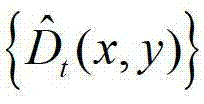 中当前待处理的像素点定义为当前像素点;
中当前待处理的像素点定义为当前像素点;
④-2、假设当前像素点的坐标位置为p,然后构建一个加权模式滤波器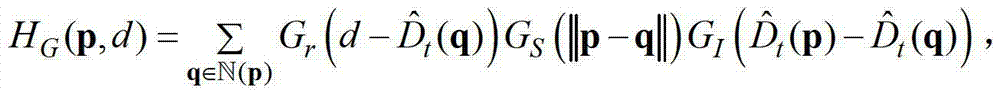 再采用该加权模式滤波器对当前像素点进行滤波处理,得到
再采用该加权模式滤波器对当前像素点进行滤波处理,得到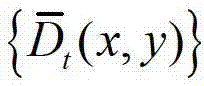 中与当前像素点相对应的像素点的深度值,记为
中与当前像素点相对应的像素点的深度值,记为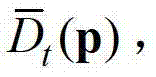 其中,0≤d≤255,表示使得HG(p,d)的值最大的d值,q表示当前像素点的邻域窗口
其中,0≤d≤255,表示使得HG(p,d)的值最大的d值,q表示当前像素点的邻域窗口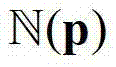 内的像素点的坐标位置,
内的像素点的坐标位置,
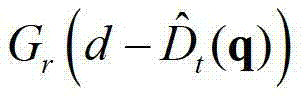 表示标准差为σr的高斯函数,
表示标准差为σr的高斯函数, GS(||p-q||)表示标准差为σS的高斯函数,
GS(||p-q||)表示标准差为σS的高斯函数,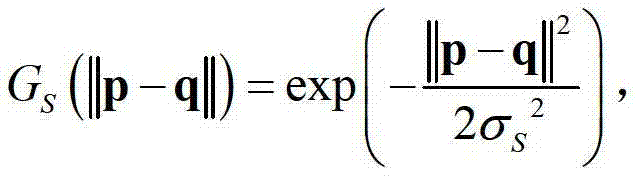 ||p-q||表示坐标位置p和坐标位置q之间的欧氏距离,符号“|| ||”为求欧氏距离符号,
||p-q||表示坐标位置p和坐标位置q之间的欧氏距离,符号“|| ||”为求欧氏距离符号,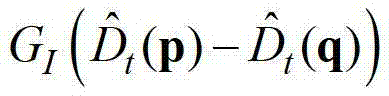 表示标准差为σI的高斯函数,
表示标准差为σI的高斯函数,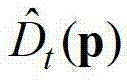 表示中坐标位置为p的像素点的深度值,
表示中坐标位置为p的像素点的深度值,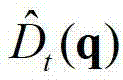 表示
表示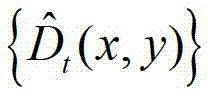 中坐标位置为q的像素点的深度值,exp()表示以e为底的指数函数,e=2.71828183;
中坐标位置为q的像素点的深度值,exp()表示以e为底的指数函数,e=2.71828183;
④-3、将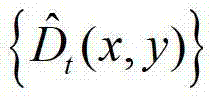 中下一个待处理的像素点作为当前像素点,然后返回步骤④-2继续执行,直至
中下一个待处理的像素点作为当前像素点,然后返回步骤④-2继续执行,直至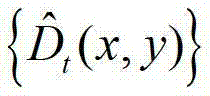 中的所有像素点处理完毕,得到深度滤波图像
中的所有像素点处理完毕,得到深度滤波图像
所述的步骤④-2中取σr=3、σS=15、σI=6。
与现有技术相比,本发明的优点在于:
1)本发明方法采用基于置信区间的交点规则,确定解码得到的彩色图像中的每个像素点在不同卷积方向上的最优尺度,将由不同卷积方向上的最优尺度确立的形状区域作为解码得到的深度图像中相对应的像素点的邻域窗口,这种方式确立的邻域窗口能够很好地反映不同区域的深度结构信息,因此能够大大提高深度估计的精确性。
2)本发明方法通过分别采用深度估计(最小化逼近多项式的均方误差)和深度滤波(加权模式滤波器)两种深度后处理技术,能够从解码得到的失真深度图像中精确地恢复出真实深度信息,这样就能够有效地提高虚拟视点图像的绘制性能。
附图说明
图1为典型的三维视频系统的基本组成框图;
图2a为“Ballet”三维视频测试序列的第4个参考视点的一幅彩色图像;
图2b为图2a所示的彩色图像对应的深度图像;
图3a为“Breakdancers”三维视频测试序列的第4个参考视点的一幅彩色图像;
图3b为图3a所示的彩色图像对应的深度图像;
图4a为“Ballet”三维视频测试序列的第4个参考视点的解码的深度图像;
图4b为“Ballet”三维视频测试序列的第4个参考视点的采用双边滤波方法得到的深度滤波图像;
图4c为“Ballet”三维视频测试序列的第4个参考视点的采用三边滤波方法得到的深度滤波图像;
图4d为“Ballet”三维视频测试序列的第4个参考视点的采用本发明方法得到的深度滤波图像;
图5a为“Breakdancers”三维视频测试序列的第4个参考视点的解码的深度图像;
图5b为“Breakdancers”三维视频测试序列的第4个参考视点的采用双边滤波方法得到的深度滤波图像;
图5c为“Breakdancers”三维视频测试序列的第4个参考视点的采用三边滤波方法得到的深度滤波图像;
图5d为“Breakdancers”三维视频测试序列的第4个参考视点的采用本发明方法得到的深度滤波图像;
图6a为图4a的局部细节放大图;
图6b为图4b的局部细节放大图;
图6c为图4c的局部细节放大图;
图6d为图4d的局部细节放大图;
图7a为图5a的局部细节放大图;
图7b为图5b的局部细节放大图;
图7c为图5c的局部细节放大图;
图7d为图5d的局部细节放大图;
图8a为“Ballet”三维视频测试序列的第3个参考视点的采用解码的深度图像绘制得到的虚拟视点图像;
图8b为“Ballet”三维视频测试序列的第3个参考视点的采用双边滤波方法得到的深度滤波图像绘制得到的虚拟视点图像;
图8c为“Ballet”三维视频测试序列的第3个参考视点的采用三边滤波方法得到的深度滤波图像绘制得到的虚拟视点图像;
图8d为“Ballet”三维视频测试序列的第3个参考视点的采用本发明方法得到的深度滤波图像绘制得到的虚拟视点图像;
图9a为“Breakdancers”三维视频测试序列的第3个参考视点的采用解码的深度图像绘制得到的虚拟视点图像;
图9b为“Breakdancers”三维视频测试序列的第3个参考视点的采用双边滤波方法得到的深度滤波图像绘制得到的虚拟视点图像;
图9c为“Breakdancers”三维视频测试序列的第3个参考视点的采用三边滤波方法得到的深度滤波图像绘制得到的虚拟视点图像;
图9d为“Breakdancers”三维视频测试序列的第3个参考视点的采用本发明方法得到的深度滤波图像绘制得到的虚拟视点图像;
图10a为图8a的局部细节放大图;
图10b为图8b的局部细节放大图;
图10c为图8c的局部细节放大图;
图10d为图8d的局部细节放大图;
图11a为图9a的局部细节放大图;
图11b为图9b的局部细节放大图;
图11c为图9c的局部细节放大图;
图11d为图9d的局部细节放大图;
图12为本发明方法的总体实现框图。
具体实施方式
以下结合附图实施例对本发明作进一步详细描述。
本发明提出的一种深度图像的后处理方法,其总体实现框图如图12所示,其处理过程为:首先,在解码端获取解码得到的彩色图像和对应的深度图像;然后,利用基于置信区间的交点规则确定解码得到的深度图像中的每个像素点的邻域窗口;接着,通过最小化逼近多项式的均方误差估计解码得到的深度图像中的每个像素点的深度值,得到深度估计图像;最后,采用加权模式滤波器对深度估计图像中的每个像素点进行滤波处理,得到深度滤波图像,该深度滤波图像用于虚拟视点图像的绘制。
本发明的深度图像的后处理方法,它具体包括以下步骤:
①在解码端,将解码得到的t时刻的彩色图像记为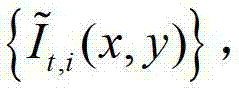 将解码得到的t时刻的深度图像记为
将解码得到的t时刻的深度图像记为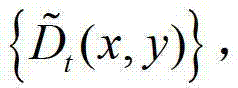 其中,i=1,2,3分别表示YUV颜色空间的三个分量,YUV颜色空间的第1个分量为亮度分量并记为Y、第2个分量为第一色度分量并记为U及第3个分量为第二色度分量并记为V,(x,y)表示彩色图像和深度图像中的像素点的坐标位置,1≤x≤W,1≤y≤H,W表示彩色图像和深度图像的宽度,H表示彩色图像和深度图像的高度,
其中,i=1,2,3分别表示YUV颜色空间的三个分量,YUV颜色空间的第1个分量为亮度分量并记为Y、第2个分量为第一色度分量并记为U及第3个分量为第二色度分量并记为V,(x,y)表示彩色图像和深度图像中的像素点的坐标位置,1≤x≤W,1≤y≤H,W表示彩色图像和深度图像的宽度,H表示彩色图像和深度图像的高度,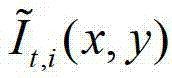 表示
表示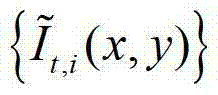 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,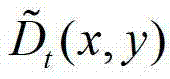 表示
表示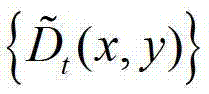 中坐标位置为(x,y)的像素点的深度值。
中坐标位置为(x,y)的像素点的深度值。
在此,截取微软提供的三维视频序列“Ballet”和“Breakdancers”作为原始三维视频。图2a和图2b分别给出了三维视频序列“Ballet”的第4个参考视点的一幅原始彩色图像和对应的原始深度图像;图3a和图3b分别给出了三维视频序列“Breakdancers”的第4个参考视点的一幅原始彩色图像和对应的原始深度图像。
②由于彩色(深度)图像的不同区域的纹理特征是不一致的,如果对所有的区域都采用相同的邻域窗口会导致后续深度估计和深度滤波的不精确,因此本发明方法通过采用在不同卷积方向上的多个不同尺度的多项式核函数分别对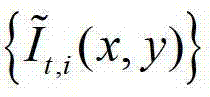 进行卷积操作,获取
进行卷积操作,获取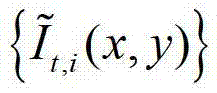 中的每个像素点在不同卷积方向上的多个不同尺度各自的置信区间的交点,然后确定
中的每个像素点在不同卷积方向上的多个不同尺度各自的置信区间的交点,然后确定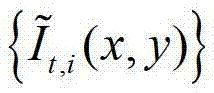 中的每个像素点在不同卷积方向上的最优尺度,再将由
中的每个像素点在不同卷积方向上的最优尺度,再将由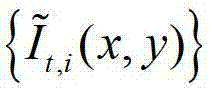 中的每个像素点在不同卷积方向上的最优尺度确立的形状区域作为
中的每个像素点在不同卷积方向上的最优尺度确立的形状区域作为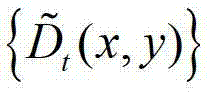 中对应像素点的邻域窗口,将
中对应像素点的邻域窗口,将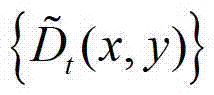 中坐标位置为(x,y)的像素点的邻域窗口记为
中坐标位置为(x,y)的像素点的邻域窗口记为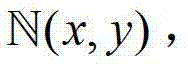 将
将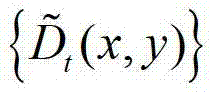 中的所有像素点的邻域窗口的集合记为
中的所有像素点的邻域窗口的集合记为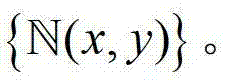
在此具体实施例中,步骤②的具体过程为:
②-1、将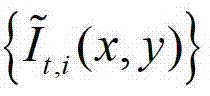 中当前待处理的像素点定义为当前像素点。
中当前待处理的像素点定义为当前像素点。
②-2、假设当前像素点的坐标位置为(x1,y1),其中,1≤x1≤W,1≤y1≤H。
②-3、采用在不同卷积方向上的多个不同尺度的多项式核函数分别对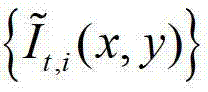 进行卷积操作,得到当前像素点在不同卷积方向上的多个不同尺度各自对应的定向估计值,将当前像素点在第k个卷积方向θk上的第j个尺度hj对应的定向估计值记为其中,1≤k≤K,K表示设定的卷积方向的个数,在本实施例中取K=8,则
进行卷积操作,得到当前像素点在不同卷积方向上的多个不同尺度各自对应的定向估计值,将当前像素点在第k个卷积方向θk上的第j个尺度hj对应的定向估计值记为其中,1≤k≤K,K表示设定的卷积方向的个数,在本实施例中取K=8,则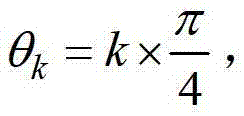 1≤j≤J,J表示设定的尺度的个数,在本实施例中取J=6,j=1时h1=1,j=2时h2=2,j=3时h3=3,j=4时h4=5,j=5时h5=7,j=6时h6=11,
1≤j≤J,J表示设定的尺度的个数,在本实施例中取J=6,j=1时h1=1,j=2时h2=2,j=3时h3=3,j=4时h4=5,j=5时h5=7,j=6时h6=11, 表示
表示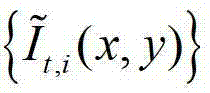 的第1个分量的函数表示形式,符号“*”为卷积操作符号,
的第1个分量的函数表示形式,符号“*”为卷积操作符号,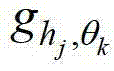 表示当前像素点在第k个卷积方向θk上的第j个尺度hj的多项式核函数,
表示当前像素点在第k个卷积方向θk上的第j个尺度hj的多项式核函数,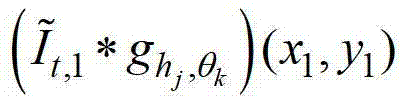 表示采用
表示采用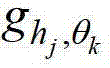 对
对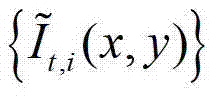 中坐标位置为(x1,y1)的像素点的第1个分量进行卷积操作,px-=x1-hjcos(θk),px+=x1+hjcos(θk),py-=y1-hjsin(θk),py+=y1+hjsin(θk),
中坐标位置为(x1,y1)的像素点的第1个分量进行卷积操作,px-=x1-hjcos(θk),px+=x1+hjcos(θk),py-=y1-hjsin(θk),py+=y1+hjsin(θk),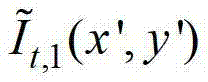 表示
表示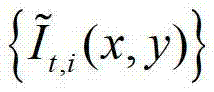 中坐标位置为(x′,y′)的像素点的第1个分量的值,
中坐标位置为(x′,y′)的像素点的第1个分量的值,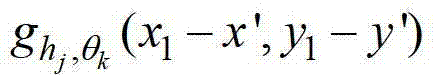 表示
表示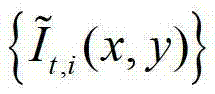 中坐标位置为(x1-x',y1-y')的像素点在第k个卷积方向θk上的第j个尺度hj的多项式核函数值,为的转置矩阵,
中坐标位置为(x1-x',y1-y')的像素点在第k个卷积方向θk上的第j个尺度hj的多项式核函数值,为的转置矩阵,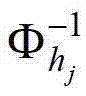 为
为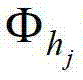 的逆矩阵。
的逆矩阵。
②-4、计算当前像素点在不同卷积方向上的多个不同尺度各自对应的置信区间的交点,将当前像素点在第k个卷积方向θk上的第j个尺度hj对应的置信区间的交点记为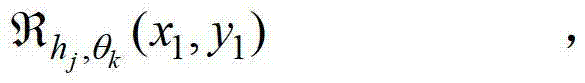
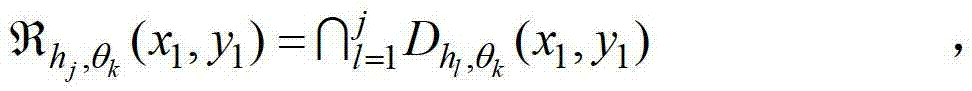 其中,符号“∩”为求交集操作符号,1≤l≤j,
其中,符号“∩”为求交集操作符号,1≤l≤j,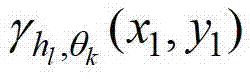 表示当前像素点在第k个卷积方向θk上的第l个尺度hl对应的定向估计值,
表示当前像素点在第k个卷积方向θk上的第l个尺度hl对应的定向估计值,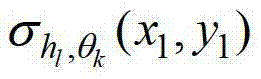 为
为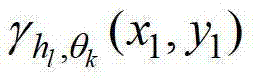 的标准差,p′x-=x1-hlcos(θk),p′x+=x1+hlcos(θk),p′y-=y1-hlsin(θk),p′y+=y1+hlsin(θk),M=(2hlcos(θk+1))(2hlsin(θk)+1),
的标准差,p′x-=x1-hlcos(θk),p′x+=x1+hlcos(θk),p′y-=y1-hlsin(θk),p′y+=y1+hlsin(θk),M=(2hlcos(θk+1))(2hlsin(θk)+1),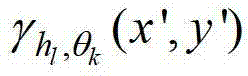 表示
表示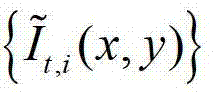 中坐标位置为(x′,y′)的像素点在第k个卷积方向θk上的第l个尺度hl对应的定向估计值,Γ为控制置信区间范围的参数,在本实施例中取Γ=1.05,此处符号“[]”为区间表示符号。
中坐标位置为(x′,y′)的像素点在第k个卷积方向θk上的第l个尺度hl对应的定向估计值,Γ为控制置信区间范围的参数,在本实施例中取Γ=1.05,此处符号“[]”为区间表示符号。
②-5、根据当前像素点在不同卷积方向上的多个不同尺度各自对应的置信区间的交点,获取当前像素点在不同卷积方向上的最优尺度,对于第k个卷积方向θk,从当前像素点在第k个卷积方向θk上的多个不同尺度各自对应的置信区间的交点(即集合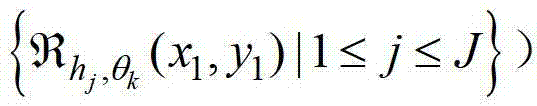 中找出非空的最大值,将该最大值对应的尺度作为当前像素点在第k个卷积方向θk上的最优尺度。
中找出非空的最大值,将该最大值对应的尺度作为当前像素点在第k个卷积方向θk上的最优尺度。
②-6、将由当前像素点在不同卷积方向上的最优尺度确立的形状区域作为当前像素点的邻域窗口,记为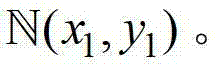
②-7、将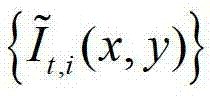 中下一个待处理的像素点作为当前像素点,然后返回步骤②-2继续执行,直至
中下一个待处理的像素点作为当前像素点,然后返回步骤②-2继续执行,直至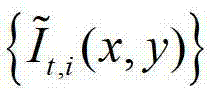 中的所有像素点处理完毕,获得
中的所有像素点处理完毕,获得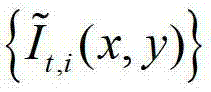 中的每个像素点的邻域窗口,再将
中的每个像素点的邻域窗口,再将 中的每个像素点的邻域窗口作为
中的每个像素点的邻域窗口作为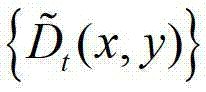 中对应像素点的邻域窗口,将
中对应像素点的邻域窗口,将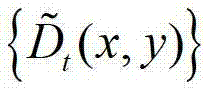 中的所有像素点的邻域窗口的集合记为
中的所有像素点的邻域窗口的集合记为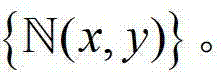
③由于在同一邻域窗口内的深度值分布较为平坦,具有一定的统计规律性,因此本发明方法根据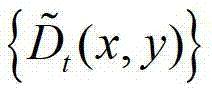 中的每个像素点的邻域窗口,通过最小化逼近多项式的均方误差估计
中的每个像素点的邻域窗口,通过最小化逼近多项式的均方误差估计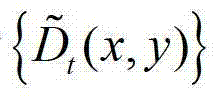 中的每个像素点的深度值,得到深度估计图像,记为
中的每个像素点的深度值,得到深度估计图像,记为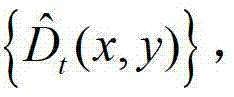 其中,
其中,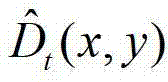 表示
表示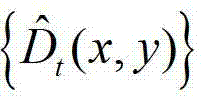 中坐标位置为(x,y)的像素点的深度值。
中坐标位置为(x,y)的像素点的深度值。
在此具体实施例中,步骤③的具体过程为:
③-1、将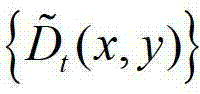 中当前待处理的像素点定义为当前像素点。
中当前待处理的像素点定义为当前像素点。
③-2、假设当前像素点的坐标位置为p,将当前像素点的邻域窗口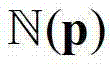 内的各个像素点的深度值分别记为y1,...,yN,其中,N表示
内的各个像素点的深度值分别记为y1,...,yN,其中,N表示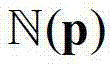 内的像素点的个数,y1表示
内的像素点的个数,y1表示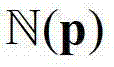 内的第1个像素点的深度值,yN表示
内的第1个像素点的深度值,yN表示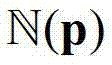 内的第N个像素点的深度值。
内的第N个像素点的深度值。
③-3、令y=[y1,...,yN]T,然后根据y=[y1,...yN]T和估计当前像素点的深度值,即利用最小化逼近多项式的均方误差,得到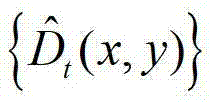 中与当前像素点相对应的像素点的深度值,记为
中与当前像素点相对应的像素点的深度值,记为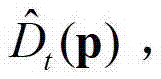
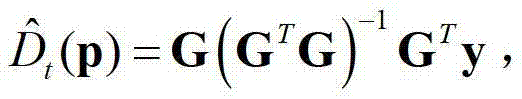 其中,y为N×1维矩阵,G为N×3维矩阵,GT为G的转置矩阵,(GTG)-1为GTG的逆矩阵。
其中,y为N×1维矩阵,G为N×3维矩阵,GT为G的转置矩阵,(GTG)-1为GTG的逆矩阵。
③-4、将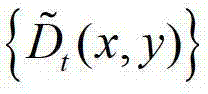 中下一个待处理的像素点作为当前像素点,然后返回步骤③-2继续执行,直至
中下一个待处理的像素点作为当前像素点,然后返回步骤③-2继续执行,直至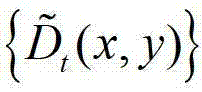 中的所有像素点处理完毕,得到深度估计图像
中的所有像素点处理完毕,得到深度估计图像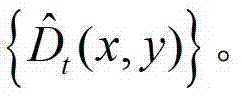
④由于通过最小化逼近多项式的均方误差估计得到的深度值并没有充分考虑深度图像的边缘特性,会在估计得到的深度估计图像的边缘区域出现模糊现象,因此本发明方法采用加权模式滤波器对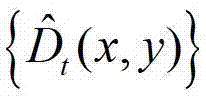 中的每个像素点进行滤波处理,得到深度滤波图像,记为
中的每个像素点进行滤波处理,得到深度滤波图像,记为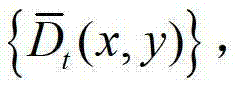 将
将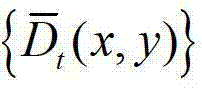 作为最终后处理得到的用于绘制虚拟视点图像的深度图像,即根据
作为最终后处理得到的用于绘制虚拟视点图像的深度图像,即根据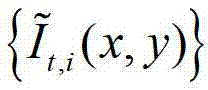 和
和 采用基于深度图像的绘制得到虚拟视点图像,其中,
采用基于深度图像的绘制得到虚拟视点图像,其中,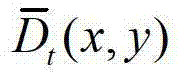 表示
表示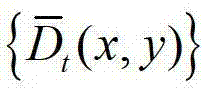 中坐标位置为(x,y)的像素点的深度值。
中坐标位置为(x,y)的像素点的深度值。
在此具体实施例中,步骤④的具体过程为:
④-1、将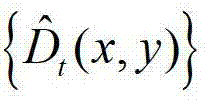 中当前待处理的像素点定义为当前像素点。
中当前待处理的像素点定义为当前像素点。
④-2、假设当前像素点的坐标位置为p,然后构建一个加权模式滤波器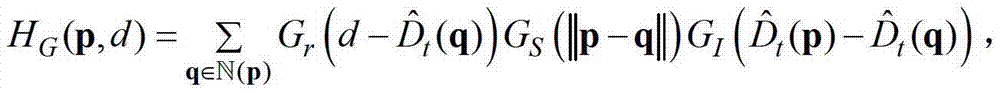 再采用该加权模式滤波器对当前像素点进行滤波处理,得到
再采用该加权模式滤波器对当前像素点进行滤波处理,得到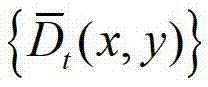 中与当前像素点相对应的像素点的深度值,记为
中与当前像素点相对应的像素点的深度值,记为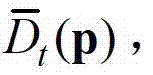 其中,0≤d≤255,表示使得HG(p,d)的值最大的d值,q表示当前像素点的邻域窗口
其中,0≤d≤255,表示使得HG(p,d)的值最大的d值,q表示当前像素点的邻域窗口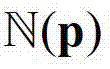 内的像素点的坐标位置,
内的像素点的坐标位置,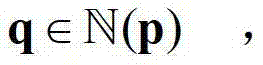
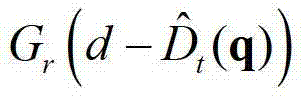 表示标准差为σr的高斯函数,
表示标准差为σr的高斯函数,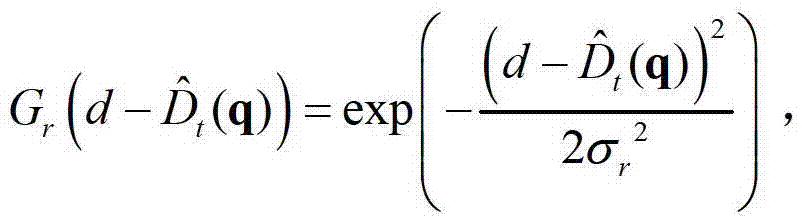 GS(||p-q||)表示标准差为σS的高斯函数,
GS(||p-q||)表示标准差为σS的高斯函数,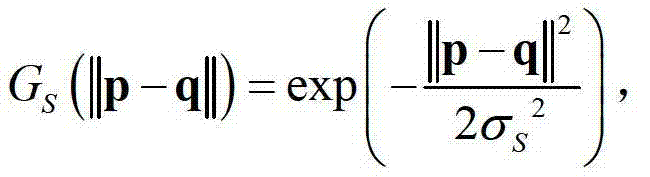 ||p-q||表示坐标位置p和坐标位置q之间的欧氏距离,符号“|| ||”为求欧氏距离符号,
||p-q||表示坐标位置p和坐标位置q之间的欧氏距离,符号“|| ||”为求欧氏距离符号,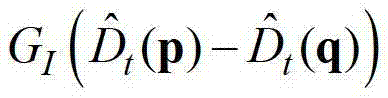 表示标准差为σI的高斯函数,
表示标准差为σI的高斯函数,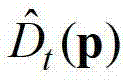 表示中坐标位置为p的像素点的深度值,
表示中坐标位置为p的像素点的深度值,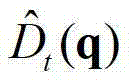 表示
表示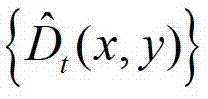 中坐标位置为q的像素点的深度值,exp()表示以e为底的指数函数,e=2.71828183,在本实施例中取σr=3、σS=15、σI=6。
中坐标位置为q的像素点的深度值,exp()表示以e为底的指数函数,e=2.71828183,在本实施例中取σr=3、σS=15、σI=6。
④-3、将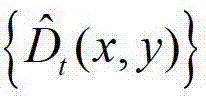 中下一个待处理的像素点作为当前像素点,然后返回步骤④-2继续执行,直至
中下一个待处理的像素点作为当前像素点,然后返回步骤④-2继续执行,直至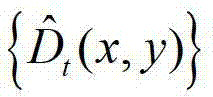 中的所有像素点处理完毕,得到深度滤波图像
中的所有像素点处理完毕,得到深度滤波图像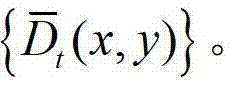
以下就本发明方法对“Ballet”和“Breakdancers”三维视频序列进行深度后处理和虚拟视点图像绘制的主客观性能进行比较。
对“Ballet”和“Breakdancers”三维视频测试序列的解码的深度图像进行滤波后处理实验,图4a给出了“Ballet”三维视频测试序列的第4个参考视点的解码的深度图像,图4b给出了“Ballet”三维视频测试序列的第4个参考视点的采用双边滤波方法得到的深度滤波图像,图4c给出了“Ballet”三维视频测试序列的第4个参考视点的采用三边滤波方法得到的深度滤波图像,图4d给出了“Ballet”三维视频测试序列的第4个参考视点的采用本发明方法得到的深度滤波图像,图5a给出了“Breakdancers”三维视频测试序列的第4个参考视点的解码的深度图像,图5b给出了“Breakdancers”三维视频测试序列的第4个参考视点的采用双边滤波方法得到的深度滤波图像,图5c给出了“Breakdancers”三维视频测试序列的第4个参考视点的采用三边滤波方法得到的深度滤波图像,图5d给出了“Breakdancers”三维视频测试序列的第4个参考视点的采用本发明方法得到的深度滤波图像,图6a、图6b、图6c和图6d分别给出了图4a、图4b、图4c和图4d的局部细节放大图,图7a、图7b、图7c和图7d分别给出了图5a、图5b、图5c和图5d的局部细节放大图。从图4a至图7d中可以看出,采用本发明方法得到的滤波处理后的深度图像即深度滤波图像,保持了深度图像的重要的几何特征,产生了令人满意的锐利的边缘和平滑的轮廓。
将采用本发明方法得到的深度滤波图像绘制得到的虚拟视点图像,与不采用本发明方法得到的深度滤波图像绘制得到的虚拟视点图像进行比较。图8a给出了“Ballet”三维视频测试序列的第3个参考视点的采用解码的深度图像绘制得到的虚拟视点图像,图8b给出了“Ballet”三维视频测试序列的第3个参考视点的采用双边滤波方法得到的深度滤波图像绘制得到的虚拟视点图像,图8c给出了“Ballet”三维视频测试序列的第3个参考视点的采用三边滤波方法得到的深度滤波图像绘制得到的虚拟视点图像,图8d给出了“Ballet”三维视频测试序列的第3个参考视点的采用本发明方法得到的深度滤波图像绘制得到的虚拟视点图像,图9a给出了“Breakdancers”三维视频测试序列的第3个参考视点的采用解码的深度图像绘制得到的虚拟视点图像,图9b给出了“Breakdancers”三维视频测试序列的第3个参考视点的采用双边滤波方法得到的深度滤波图像绘制得到的虚拟视点图像,图9c给出了“Breakdancers”三维视频测试序列的第3个参考视点的采用三边滤波方法得到的深度滤波图像绘制得到的虚拟视点图像,图9d给出了“Breakdancers”三维视频测试序列的第3个参考视点的采用本发明方法得到的深度滤波图像绘制得到的虚拟视点图像,图10a、图10b、图10c和图10d分别给出了图8a、图8b、图8c和图8d的局部细节放大图,图11a、图11b、图11c和图11d分别给出了图9a、图9b、图9c和图9d的局部细节放大图。从图8a至图11d中可以看出,采用本发明方法得到的深度滤波图像绘制得到的虚拟视点图像能够保持更好的对象轮廓信息,从而降低了由于深度图像的失真而引起的映射过程中产生的背景对前景的覆盖,提高了虚拟视点图像的质量。
将采用本发明方法得到的深度滤波图像绘制得到的虚拟视点图像与不采用本发明方法得到的深度滤波图像绘制得到的虚拟视点图像的峰值信噪比(PSNR)进行比较,比较结果如表1所列,从表1所列的数据中可以看出,采用本发明方法得到的深度滤波图像绘制得到的虚拟视点图像的质量要明显好于不采用本发明方法得到的深度滤波图像绘制得到的虚拟视点图像的质量,充分说明了本发明方法是有效可行的。
表1采用本发明方法得到的深度滤波图像绘制得到的虚拟视点图像与不采用本发明方法得到的深度滤波图像绘制得到的虚拟视点图像的峰值信噪比(PSNR)比较

 手机二维码
手机二维码 京公网安备11011302007134
京公网安备11011302007134