技术领域
本发明涉及一种多视点视频系统技术,尤其是涉及一种交互式三维视频系统中的信号处理方法。
背景技术
进入本世纪以来,随着数字2D(二维)视频技术日趋成熟,以及计算机、通信及网络技术的快速发展,引发了人们对新一代视频系统的强烈需求。现行的二维视频系统在表现自然场景时,难以满足用户的立体感和视点交互等的需求。交互式三维视频系统由于能够提供立体感、视点交互性的全新视觉体验,因此越来越受到人们的欢迎,其在无线视频通信、影视娱乐、数字动漫、虚拟战场、旅游观光、远程教学等领域有着广泛的应用前景。
对于三维视频编码的性能评价,通常有多个技术指标,如率失真性能、时间可分级、视点可分级、随机接入性能、编码复杂度、解码复杂度、存储需求等等,这些技术指标在一定程度上本身就存在着相互制约,因此根据不同的应用环境,需要侧重不同的技术指标来进行性能评价,并且对某些技术指标做适当的修正。面向用户端的交互式三维视频系统的目的是为了满足用户最大限度的自主性,因此,实现用户端与服务端之间的高效交互操作以满足用户的选择需求是面向用户端的交互式三维视频系统最基本也是最主要的任务。基于面向用户端的交互式三维视频系统考虑,实现高效的交互操作应满足:1)合理的带宽代价,以适应网络传输的要求;2)较低的解码复杂度以及虚拟视点绘制复杂度,能够实时解码及绘制虚拟视点,以降低对用户端系统资源的要求。
发明内容
本发明所要解决的技术问题是提供一种交互式三维视频系统中的信号处理方法,其能够有效地降低交互式三维视频系统对网络带宽和用户端资源的要求,能够满足用户最大限度的自主性。
本发明解决上述技术问题所采用的技术方案为:一种交互式三维视频系统中的信号处理方法,该交互式三维视频系统主要由服务端的三维视频编码模块以及用户端的视点解码模块、任意视点绘制模块和视频显示模块构成,其特征在于该设计方法包括以下步骤:
①获取t时刻的K个参考视点的K幅颜色空间为YUV的彩色图像及其对应的K幅深度图像,将t时刻的第k个参考视点的彩色图像记为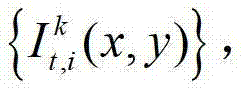 将t时刻的第k个参考视点的深度图像记为
将t时刻的第k个参考视点的深度图像记为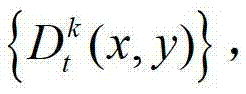 其中,K≥2,1≤k≤K,k的初始值为1,i=1,2,3分别表示YUV颜色空间的三个分量,YUV颜色空间的第1个分量为亮度分量并记为Y、第2个分量为第一色度分量并记为U及第3个分量为第二色度分量并记为V,(x,y)表示彩色图像和深度图像中的像素点的坐标位置,1≤x≤W,1≤y≤H,W表示彩色图像和深度图像的宽度,H表示彩色图像和深度图像的高度,
其中,K≥2,1≤k≤K,k的初始值为1,i=1,2,3分别表示YUV颜色空间的三个分量,YUV颜色空间的第1个分量为亮度分量并记为Y、第2个分量为第一色度分量并记为U及第3个分量为第二色度分量并记为V,(x,y)表示彩色图像和深度图像中的像素点的坐标位置,1≤x≤W,1≤y≤H,W表示彩色图像和深度图像的宽度,H表示彩色图像和深度图像的高度,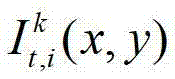 表示t时刻的第k个参考视点的彩色图像
表示t时刻的第k个参考视点的彩色图像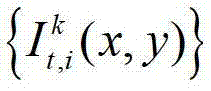 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,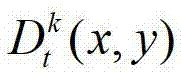 表示t时刻的第k个参考视点的深度图像
表示t时刻的第k个参考视点的深度图像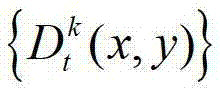 中坐标位置为(x,y)的像素点的深度值;
中坐标位置为(x,y)的像素点的深度值;
②将t时刻的K个参考视点中每相邻的两个参考视点作为一对关联参考视点,将每对关联参考视点之间的N个虚拟视点均作为辅助视点,然后采用基于深度图像绘制的方法,获取t时刻的(K-1)×N个辅助视点各自的残差图像,将t时刻的第l个辅助视点的残差图像记为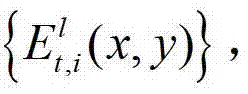 其中,N>1,1≤l≤(K-1)×N,l的初始值为1,
其中,N>1,1≤l≤(K-1)×N,l的初始值为1,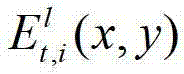 表示t时刻的第l个辅助视点的残差图像
表示t时刻的第l个辅助视点的残差图像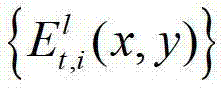 中坐标位置为(x,y)的像素点的第i个分量的值;
中坐标位置为(x,y)的像素点的第i个分量的值;
③服务端的三维视频编码模块根据设定的编码预测结构,对t时刻的K个参考视点的K幅彩色图像及其对应的K幅深度图像、t时刻的(K-1)×N个辅助视点各自的残差图像进行编码,再将编码后的t时刻的K个参考视点的K幅彩色图像及其对应的K幅深度图像、t时刻的(K-1)×N个辅助视点各自的残差图像传输给用户端;
④用户端的视点解码模块对编码后的t时刻的K个参考视点的K幅彩色图像及其对应的K幅深度图像、t时刻的(K-1)×N个辅助视点各自的残差图像进行解码,得到解码后的t时刻的K个参考视点的K幅彩色图像及其对应的K幅深度图像、t时刻的(K-1)×N个辅助视点各自的残差图像,将解码后的t时刻的第k个参考视点的彩色图像记为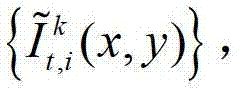 将解码后的t时刻的第k个参考视点的深度图像记为
将解码后的t时刻的第k个参考视点的深度图像记为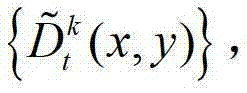 将解码后的t时刻的第l个辅助视点的残差图像记为
将解码后的t时刻的第l个辅助视点的残差图像记为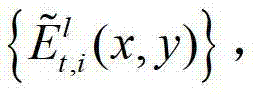 其中,
其中,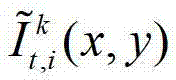 表示解码后的t时刻的第k个参考视点的彩色图像
表示解码后的t时刻的第k个参考视点的彩色图像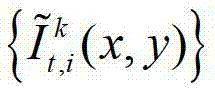 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,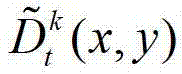 表示解码后的t时刻的第k个参考视点的深度图像
表示解码后的t时刻的第k个参考视点的深度图像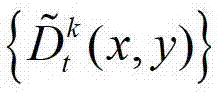 中坐标位置为(x,y)的像素点的深度值,
中坐标位置为(x,y)的像素点的深度值,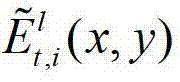 表示解码后的t时刻的第l个辅助视点的残差图像
表示解码后的t时刻的第l个辅助视点的残差图像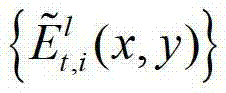 中坐标位置为(x,y)的像素点的第i个分量的值;
中坐标位置为(x,y)的像素点的第i个分量的值;
⑤根据用户所选择的视点,用户端的任意视点绘制模块根据解码后的t时刻的K个参考视点的K幅彩色图像和t时刻的(K-1)×N个辅助视点各自的残差图像,快速生成相应的参考视点信号和辅助视点信号,再将生成的参考视点信号和辅助视点信号传输给用户端的视频显示模块进行显示。
所述的步骤②的具体过程为:
②-1、将t时刻的K个参考视点中每相邻的两个参考视点作为一对关联参考视点,共存在(K-1)对关联参考视点,将每对关联参考视点之间的距离归一化表示为1,将每对关联参考视点之间的N个虚拟视点均作为辅助视点,共存在(K-1)×N个辅助视点,其中,N>1;
②-2、将t时刻的(K-1)×N个辅助视点中当前正在处理的辅助视点定义为当前辅助视点;
②-3、假设当前辅助视点为t时刻的第k′个参考视点与t时刻的第k′+1个参考视点构成的一对关联参考视点之间的虚拟视点,并假设当前辅助视点为t时刻的(K-1)×N个辅助视点中的第l′个辅助视点,则将当前辅助视点与t时刻的第k′个参考视点之间的距离表示为α,将当前辅助视点与t时刻的第k′+1个参考视点之间的距离表示为1-α,其中,1≤k′≤K-1,k′的初始值为1,(k′-1)×N+1≤l′≤(k′-1)×N+N,0<α<1;
②-4、将t时刻的第k′个参考视点的彩色图像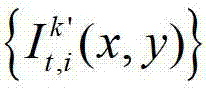 中的每个像素点从第k′个参考视点投影到当前辅助视点,得到t时刻的第k′个参考视点的绘制图像,记为
中的每个像素点从第k′个参考视点投影到当前辅助视点,得到t时刻的第k′个参考视点的绘制图像,记为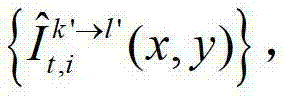 将t时刻的第k′个参考视点的绘制图像
将t时刻的第k′个参考视点的绘制图像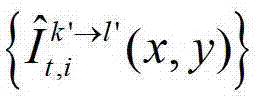 中坐标位置为(x3,y3)的像素点的第i个分量的值记为
中坐标位置为(x3,y3)的像素点的第i个分量的值记为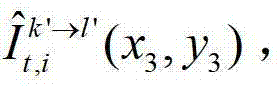 假设t时刻的第k′个参考视点的绘制图像
假设t时刻的第k′个参考视点的绘制图像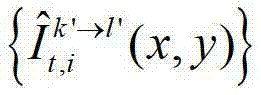 中坐标位置为(x3,y3)的像素点为t时刻的第k′个参考视点的彩色图像
中坐标位置为(x3,y3)的像素点为t时刻的第k′个参考视点的彩色图像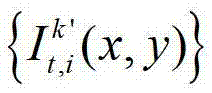 中坐标位置为(x1,y1)的像素点从第k′个参考视点投影到当前辅助视点中的,则令
中坐标位置为(x1,y1)的像素点从第k′个参考视点投影到当前辅助视点中的,则令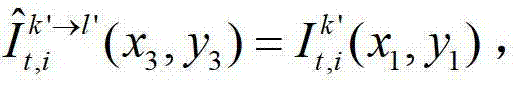 其中,
其中,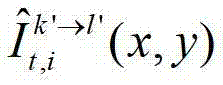 表示t时刻的第k′个参考视点的绘制图像
表示t时刻的第k′个参考视点的绘制图像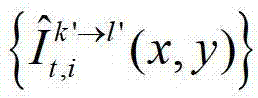 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,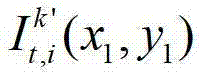 表示t时刻的第k′个参考视点的彩色图像
表示t时刻的第k′个参考视点的彩色图像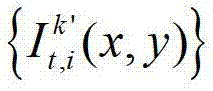 中坐标位置为(x1,y1)的像素点的第i个分量的值,x1∈[1,W],y1∈[1,H],x3∈[1,W],y3∈[1,H],x3=x′/z′,y3=y′/z′,(x′,y′,z′)T=A2R2-1(u,v,w)T-A2R2-1T2,(x′,y′,z′)T为(x′,y′,z′)的转置矩阵,A2为当前辅助视点的内参矩阵,R2-1为R2的逆矩阵,R2为当前辅助视点的旋转矩阵,
中坐标位置为(x1,y1)的像素点的第i个分量的值,x1∈[1,W],y1∈[1,H],x3∈[1,W],y3∈[1,H],x3=x′/z′,y3=y′/z′,(x′,y′,z′)T=A2R2-1(u,v,w)T-A2R2-1T2,(x′,y′,z′)T为(x′,y′,z′)的转置矩阵,A2为当前辅助视点的内参矩阵,R2-1为R2的逆矩阵,R2为当前辅助视点的旋转矩阵,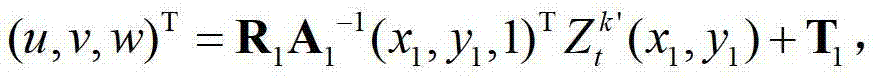 (u,v,w)T为(u,v,w)的转置矩阵,R1为t时刻的第k′个参考视点的旋转矩阵,A1-1为A1的逆矩阵,A1为t时刻的第k′个参考视点的内参矩阵,(x1,y1,1)T为(x1,y1,1)的转置矩阵,T1为t时刻的第k′个参考视点的平移矩阵,T2为当前辅助视点的平移矩阵,
(u,v,w)T为(u,v,w)的转置矩阵,R1为t时刻的第k′个参考视点的旋转矩阵,A1-1为A1的逆矩阵,A1为t时刻的第k′个参考视点的内参矩阵,(x1,y1,1)T为(x1,y1,1)的转置矩阵,T1为t时刻的第k′个参考视点的平移矩阵,T2为当前辅助视点的平移矩阵,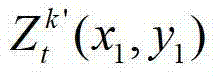 表示t时刻的第k′个参考视点的深度图像
表示t时刻的第k′个参考视点的深度图像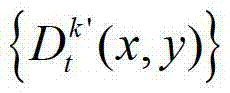 中坐标位置为(x1,y1)的像素点的场景深度,
中坐标位置为(x1,y1)的像素点的场景深度,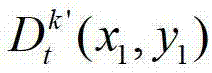 表示t时刻的第k′个参考视点的深度图像
表示t时刻的第k′个参考视点的深度图像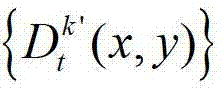 中坐标位置为(x1,y1)的像素点的深度值,Znear表示深度图像中最小的场景深度值,Zfar表示深度图像中最大的场景深度值;
中坐标位置为(x1,y1)的像素点的深度值,Znear表示深度图像中最小的场景深度值,Zfar表示深度图像中最大的场景深度值;
②-5、将t时刻的第k′+1个参考视点的彩色图像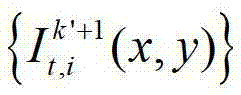 中的每个像素点从第k′+1个参考视点投影到当前辅助视点,得到t时刻的第k′+1个参考视点的绘制图像,记为
中的每个像素点从第k′+1个参考视点投影到当前辅助视点,得到t时刻的第k′+1个参考视点的绘制图像,记为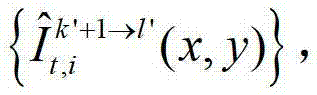 将t时刻的第k′+1个参考视点的绘制图像
将t时刻的第k′+1个参考视点的绘制图像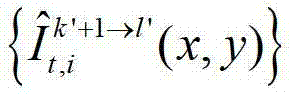 中坐标位置为(x4,y4)的像素点的第i个分量的值记为
中坐标位置为(x4,y4)的像素点的第i个分量的值记为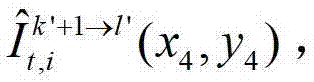 假设t时刻的第k′+1个参考视点的绘制图像
假设t时刻的第k′+1个参考视点的绘制图像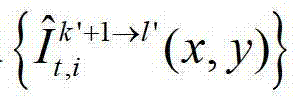 中坐标位置为(x4,y4)的像素点为t时刻的第k′+1个参考视点的彩色图像
中坐标位置为(x4,y4)的像素点为t时刻的第k′+1个参考视点的彩色图像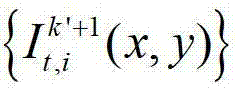 中坐标位置为(x2,y2)的像素点从第k′+1个参考视点投影到当前辅助视点中的,则令
中坐标位置为(x2,y2)的像素点从第k′+1个参考视点投影到当前辅助视点中的,则令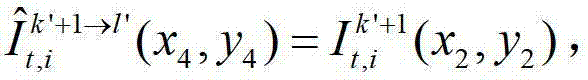 其中,
其中,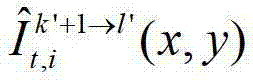 表示t时刻的第k′+1个参考视点的绘制图像
表示t时刻的第k′+1个参考视点的绘制图像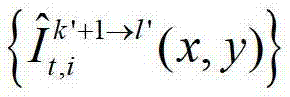 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,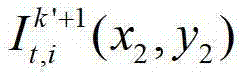 表示t时刻的第k′+1个参考视点的彩色图像
表示t时刻的第k′+1个参考视点的彩色图像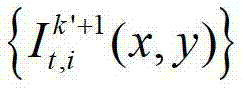 中坐标位置为(x2,y2)的像素点的第i个分量的值,x2∈[1,W],y2∈[1,H],x4∈[1,W],y4∈[1,H],x4=x″/z″,y4=y″/z″,(x″,y″,z″)T=A2R2-1(u′,v′,w′)T-A2R2-1T2,(x″,y″,z″)T为(x″,y″,z″)的转置矩阵,(u′,v′,w′)T为(u′,v′,w′)的转置矩阵,R3为t时刻的第k′+1个参考视点的旋转矩阵,A3-1为A3的逆矩阵,A3为t时刻的第k′+1个参考视点的内参矩阵,(x2,y2,1)T为(x2,y2,1)的转置矩阵,T3为t时刻的第k′+1个参考视点的平移矩阵,
中坐标位置为(x2,y2)的像素点的第i个分量的值,x2∈[1,W],y2∈[1,H],x4∈[1,W],y4∈[1,H],x4=x″/z″,y4=y″/z″,(x″,y″,z″)T=A2R2-1(u′,v′,w′)T-A2R2-1T2,(x″,y″,z″)T为(x″,y″,z″)的转置矩阵,(u′,v′,w′)T为(u′,v′,w′)的转置矩阵,R3为t时刻的第k′+1个参考视点的旋转矩阵,A3-1为A3的逆矩阵,A3为t时刻的第k′+1个参考视点的内参矩阵,(x2,y2,1)T为(x2,y2,1)的转置矩阵,T3为t时刻的第k′+1个参考视点的平移矩阵,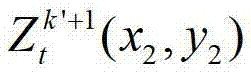 表示t时刻的第k′+1个参考视点的深度图像
表示t时刻的第k′+1个参考视点的深度图像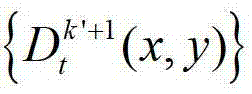 中坐标位置为(x2,y2)的像素点的场景深度,
中坐标位置为(x2,y2)的像素点的场景深度,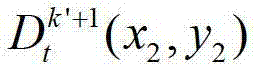 表示t时刻的第k′+1个参考视点的深度图像
表示t时刻的第k′+1个参考视点的深度图像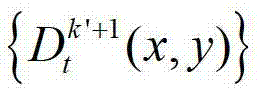 中坐标位置为(x2,y2)的像素点的深度值;
中坐标位置为(x2,y2)的像素点的深度值;
②-6、根据t时刻的第k′个参考视点的绘制图像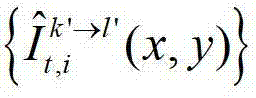 和t时刻的第k′+1个参考视点的绘制图像
和t时刻的第k′+1个参考视点的绘制图像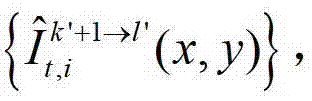 计算当前辅助视点的残差图像,记为
计算当前辅助视点的残差图像,记为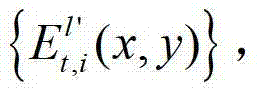 将
将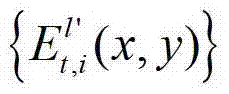 中坐标位置为(x,y)的像素点的第i个分量的值记为
中坐标位置为(x,y)的像素点的第i个分量的值记为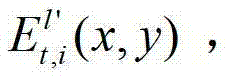
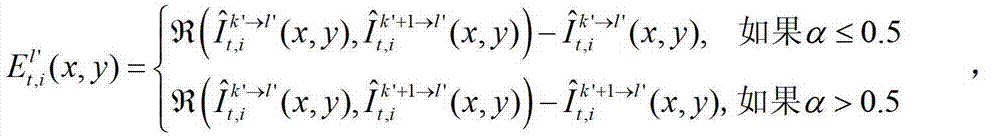 其中,
其中,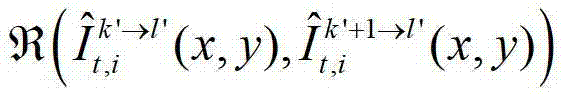 表示对t时刻的第k′个参考视点的绘制图像
表示对t时刻的第k′个参考视点的绘制图像 中坐标位置为(x,y)的像素点和t时刻的第k′+1个参考视点的绘制图像
中坐标位置为(x,y)的像素点和t时刻的第k′+1个参考视点的绘制图像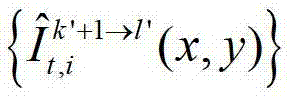 中坐标位置为(x,y)的像素点进行视点融合的操作;
中坐标位置为(x,y)的像素点进行视点融合的操作;
②-7、将t时刻的(K-1)×N个辅助视点中下一个待处理的辅助视点作为当前辅助视点,然后返回步骤②-3继续执行,直至t时刻的(K-1)×N个辅助视点均处理完毕,得到t时刻的(K-1)×N个辅助视点各自的残差图像,将t时刻的第l个辅助视点的残差图像记为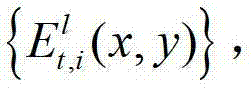 其中,1≤l≤(K-1)×N,l的初始值为1,
其中,1≤l≤(K-1)×N,l的初始值为1,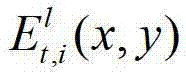 表示t时刻的第l个辅助视点的残差图像
表示t时刻的第l个辅助视点的残差图像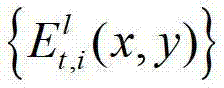 中坐标位置为(x,y)的像素点的第i个分量的值。
中坐标位置为(x,y)的像素点的第i个分量的值。
所述的步骤③中设定的编码预测结构为HBP编码预测结构。
所述的步骤⑤的具体过程为:
⑤-1、假设用户所选择的视点为实际存在的t时刻的第p个参考视点,则用户端的任意视点绘制模块将解码后的t时刻的第p个参考视点的彩色图像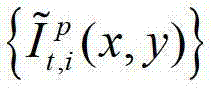 中的每个像素点从t时刻的第p个参考视点投影到t时刻的第l″个辅助视点中,得到t时刻的第p个参考视点的绘制图像,记为
中的每个像素点从t时刻的第p个参考视点投影到t时刻的第l″个辅助视点中,得到t时刻的第p个参考视点的绘制图像,记为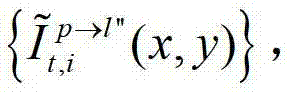 然后根据解码后的t时刻的第p个参考视点的彩色图像
然后根据解码后的t时刻的第p个参考视点的彩色图像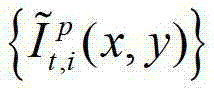 快速生成t时刻的第p个参考视点信号,记为
快速生成t时刻的第p个参考视点信号,记为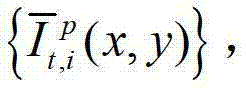 并根据解码后的t时刻的第l″个辅助视点的残差图像
并根据解码后的t时刻的第l″个辅助视点的残差图像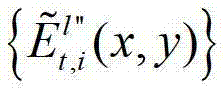 和t时刻的第p个参考视点的绘制图像
和t时刻的第p个参考视点的绘制图像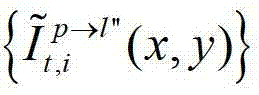 快速生成t时刻的第l″个辅助视点信号,记为
快速生成t时刻的第l″个辅助视点信号,记为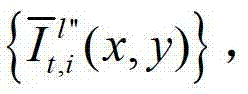 再将生成的t时刻的第p个参考视点信号
再将生成的t时刻的第p个参考视点信号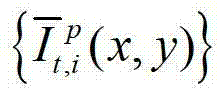 和t时刻的第l″个辅助视点信号
和t时刻的第l″个辅助视点信号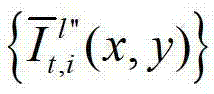 传输给用户端的视频显示模块进行显示,其中,此处1≤p≤K-1,此处l″=(p-1)×N+1,
传输给用户端的视频显示模块进行显示,其中,此处1≤p≤K-1,此处l″=(p-1)×N+1,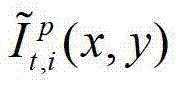 表示解码后的t时刻的第p个参考视点的彩色图像
表示解码后的t时刻的第p个参考视点的彩色图像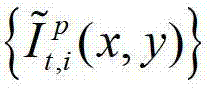 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,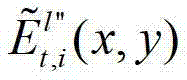 表示解码后的t时刻的第l″个辅助视点的残差图像
表示解码后的t时刻的第l″个辅助视点的残差图像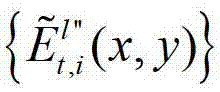 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,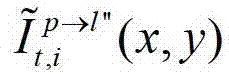 表示t时刻的第p个参考视点的绘制图像
表示t时刻的第p个参考视点的绘制图像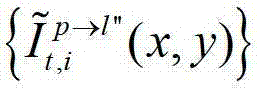 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,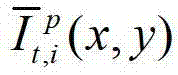 表示生成的t时刻的第p个参考视点信号
表示生成的t时刻的第p个参考视点信号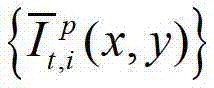 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,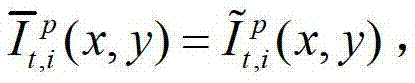
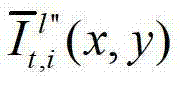 表示生成的t时刻的第l″个辅助视点信号
表示生成的t时刻的第l″个辅助视点信号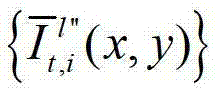 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,
⑤-2、假设用户所选择的视点为实际存在的t时刻的第K个参考视点,则用户端的任意视点绘制模块将解码后的t时刻的第K个参考视点的彩色图像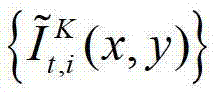 中的每个像素点从t时刻的第K个参考视点投影到t时刻的第l″个辅助视点中,得到t时刻的第K个参考视点的绘制图像,记为
中的每个像素点从t时刻的第K个参考视点投影到t时刻的第l″个辅助视点中,得到t时刻的第K个参考视点的绘制图像,记为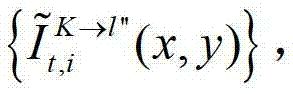 然后根据解码后的t时刻的第K个参考视点的彩色图像
然后根据解码后的t时刻的第K个参考视点的彩色图像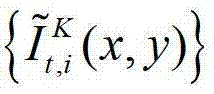 快速生成t时刻的第K个参考视点信号,记为
快速生成t时刻的第K个参考视点信号,记为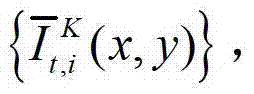 并根据解码后的t时刻的第l″个辅助视点的残差图像
并根据解码后的t时刻的第l″个辅助视点的残差图像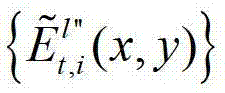 和t时刻的第K个参考视点的绘制图像
和t时刻的第K个参考视点的绘制图像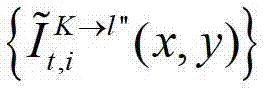 快速生成t时刻的第l″个辅助视点信号,记为
快速生成t时刻的第l″个辅助视点信号,记为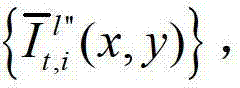 再将生成的t时刻的第K个参考视点信号
再将生成的t时刻的第K个参考视点信号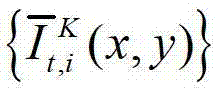 和t时刻的第l″个辅助视点信号
和t时刻的第l″个辅助视点信号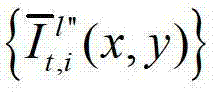 传输给用户端的视频显示模块进行显示,其中,此处l″=(K-1)×N,
传输给用户端的视频显示模块进行显示,其中,此处l″=(K-1)×N,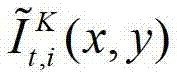 表示解码后的t时刻的第K个参考视点的彩色图像
表示解码后的t时刻的第K个参考视点的彩色图像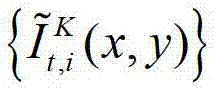 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,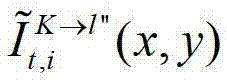 表示t时刻的第K个参考视点的绘制图像
表示t时刻的第K个参考视点的绘制图像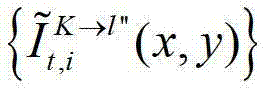 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,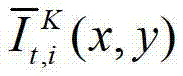 表示生成的t时刻的第K个参考视点信号
表示生成的t时刻的第K个参考视点信号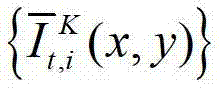 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,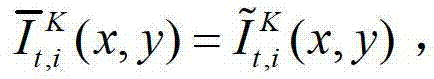
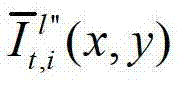 表示生成的t时刻的第l″个辅助视点信号
表示生成的t时刻的第l″个辅助视点信号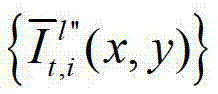 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,
⑤-3-1、假设用户所选择的视点为并不存在的虚拟视点,则选择与该虚拟视点最为邻近的两个辅助视点,假设分别为t时刻的第l″′个辅助视点和t时刻的第l″′+1个辅助视点,并且令与t时刻的第l″′个辅助视点左相邻的参考视点为t时刻的第q1个参考视点,令与t时刻的第l″′+1个辅助视点左相邻的参考视点为t时刻的第q2个参考视点,将t时刻的第l″′个辅助视点与t时刻的第q1个参考视点之间的距离表示为β,将t时刻的第l″′+1个辅助视点与第q2个参考视点之间的距离表示为γ,其中,1≤l″′≤(K-1)×N-1,1≤q1≤K-1,1≤q2≤K-1,0<β<1,0<γ<1;
⑤-3-2、用户端的任意视点绘制模块将解码后的t时刻的第q1个参考视点的彩色图像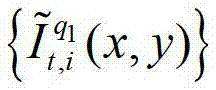 中的每个像素点从t时刻的第q1个参考视点投影到t时刻的第l″′个辅助视点中,得到t时刻的第q1个参考视点的绘制图像,记为
中的每个像素点从t时刻的第q1个参考视点投影到t时刻的第l″′个辅助视点中,得到t时刻的第q1个参考视点的绘制图像,记为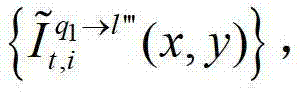 或者将解码后的t时刻的第q1+1个参考视点的彩色图像
或者将解码后的t时刻的第q1+1个参考视点的彩色图像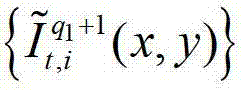 中的每个像素点从t时刻的第q1+1个参考视点投影到t时刻的第l″′个辅助视点中,得到t时刻的第q1+1个参考视点的绘制图像,记为
中的每个像素点从t时刻的第q1+1个参考视点投影到t时刻的第l″′个辅助视点中,得到t时刻的第q1+1个参考视点的绘制图像,记为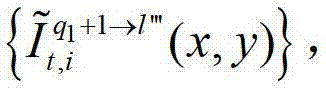 然后根据解码后的t时刻的第l″′个辅助视点的残差图像
然后根据解码后的t时刻的第l″′个辅助视点的残差图像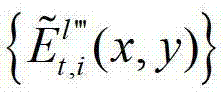 及t时刻的第q1个参考视点的绘制图像
及t时刻的第q1个参考视点的绘制图像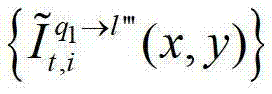 或t时刻的第q1+1个参考视点的绘制图像
或t时刻的第q1+1个参考视点的绘制图像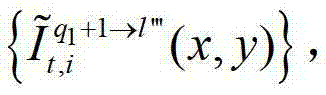 快速生成t时刻的第l″′个辅助视点信号,记为
快速生成t时刻的第l″′个辅助视点信号,记为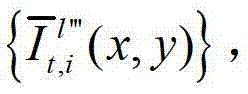 其中,
其中,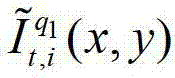 表示解码后的t时刻的第q1个参考视点的彩色图像
表示解码后的t时刻的第q1个参考视点的彩色图像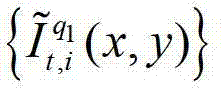 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,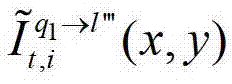 表示t时刻的第q1个参考视点的绘制图像
表示t时刻的第q1个参考视点的绘制图像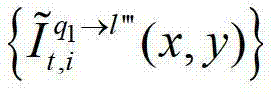 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,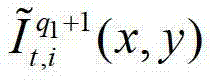 表示解码后的t时刻的第q1+1个参考视点的彩色图像
表示解码后的t时刻的第q1+1个参考视点的彩色图像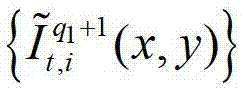 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,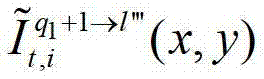 表示t时刻的第q1+1个参考视点的绘制图像
表示t时刻的第q1+1个参考视点的绘制图像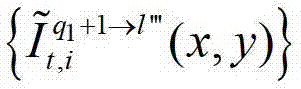 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,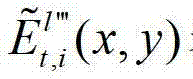 表示解码后的t时刻的第l″′个辅助视点的残差图像
表示解码后的t时刻的第l″′个辅助视点的残差图像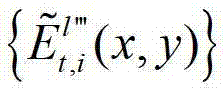 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,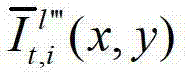 表示生成的t时刻的第l″′个辅助视点信号
表示生成的t时刻的第l″′个辅助视点信号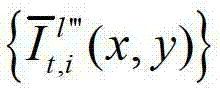 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,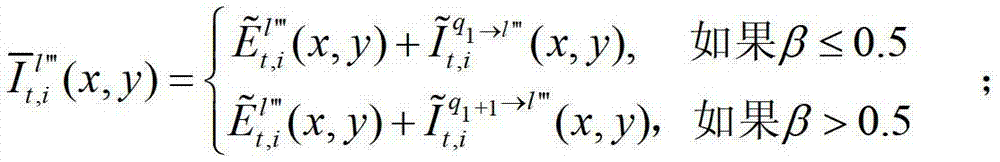
⑤-3-3、用户端的任意视点绘制模块将解码后的t时刻的第q2个参考视点的彩色图像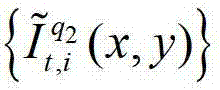 中的每个像素点从t时刻的第q2个参考视点投影到t时刻的第l″′+1个辅助视点中,得到t时刻的第q2个参考视点的绘制图像,记为
中的每个像素点从t时刻的第q2个参考视点投影到t时刻的第l″′+1个辅助视点中,得到t时刻的第q2个参考视点的绘制图像,记为 或者将解码后的t时刻的第q2+1个参考视点的彩色图像
或者将解码后的t时刻的第q2+1个参考视点的彩色图像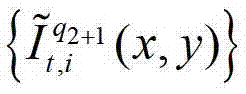 中的每个像素点从t时刻的第q2+1个参考视点投影到t时刻的第l″′+1个辅助视点中,得到t时刻的第q2+1个参考视点的绘制图像,记为
中的每个像素点从t时刻的第q2+1个参考视点投影到t时刻的第l″′+1个辅助视点中,得到t时刻的第q2+1个参考视点的绘制图像,记为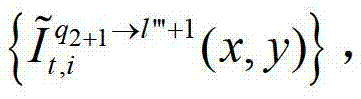 然后根据解码后的t时刻的第l″′+1个辅助视点的残差图像
然后根据解码后的t时刻的第l″′+1个辅助视点的残差图像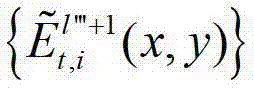 及t时刻的第q2个参考视点的绘制图像
及t时刻的第q2个参考视点的绘制图像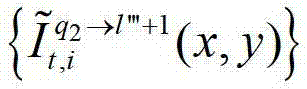 或t时刻的第q2+1个参考视点的绘制图像
或t时刻的第q2+1个参考视点的绘制图像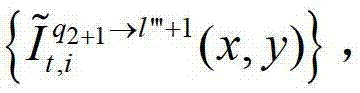 快速生成t时刻的第l″′+1个辅助视点信号,记为
快速生成t时刻的第l″′+1个辅助视点信号,记为 其中,
其中,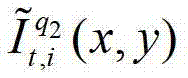 表示解码后的t时刻的第q2个参考视点的彩色图像
表示解码后的t时刻的第q2个参考视点的彩色图像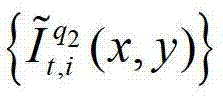 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,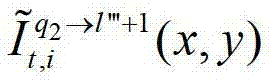 表示t时刻的第q2个参考视点的绘制图像
表示t时刻的第q2个参考视点的绘制图像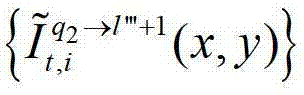 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,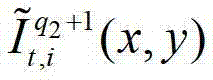 表示解码后的t时刻的第q2+1个参考视点的彩色图像
表示解码后的t时刻的第q2+1个参考视点的彩色图像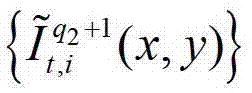 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,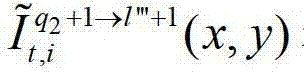 表示t时刻的第q2+1个参考视点的绘制图像
表示t时刻的第q2+1个参考视点的绘制图像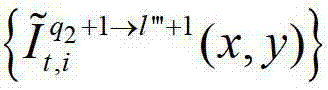 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,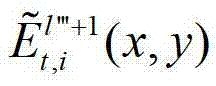 表示解码后的t时刻的第l″′+1个辅助视点的残差图像
表示解码后的t时刻的第l″′+1个辅助视点的残差图像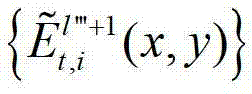 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,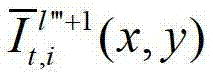 表示生成的t时刻的第l″′+1个辅助视点信号
表示生成的t时刻的第l″′+1个辅助视点信号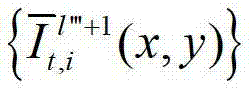 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,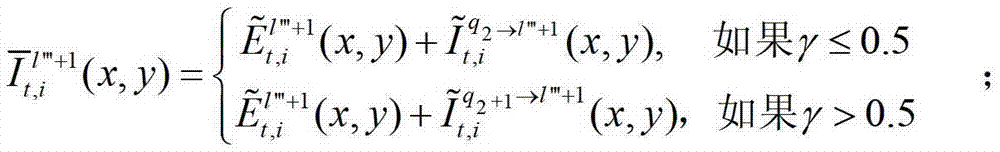
⑤-3-4、用户端的任意视点绘制模块将生成的t时刻的第l″′个辅助视点信号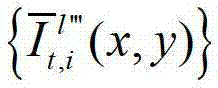 和t时刻的第l″′+1个辅助视点信号
和t时刻的第l″′+1个辅助视点信号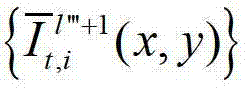 传输给用户端的视频显示模块进行显示。
传输给用户端的视频显示模块进行显示。
与现有技术相比,本发明的优点在于:
1)本发明方法将复杂度较高的虚拟视点绘制操作从用户端转移到服务端,在用户端只需要简单的三维映射和加法操作就能生成虚拟视点信号,这样就可有效地降低对用户端系统资源的要求,从而有效地降低了交互式三维视频系统的复杂度。
2)本发明方法利用基于深度图像绘制来消除三维视频的冗余信息,只需要传输包含较少信息量的残差图像,这样就能够最大程度地降低辅助视点的传输码率,降低交互式三维视频系统对于网络带宽的要求,从而满足了用户最大限度的自主性。
附图说明
图1为交互式三维视频系统的组成框图;
图2a为“Alt Moabit”三维立体视频测试序列的一个参考视点的一帧彩色图像;
图2b为“Alt Moabit”三维立体视频测试序列的一个参考视点的一帧深度图像;
图3a为“Book Arrival”三维立体视频测试序列的一个参考视点的一帧彩色图像;
图3b为“Book Arrival”三维立体视频测试序列的一个参考视点的一帧深度图像;
图4a为“Dog”三维立体视频测试序列的一个参考视点的一帧彩色图像;
图4b为“Dog”三维立体视频测试序列的一个参考视点的一帧深度图像;
图5a为“Pantomime”三维立体视频测试序列的一个参考视点的一帧彩色图像;
图5b为“Pantomime”三维立体视频测试序列的一个参考视点的一帧深度图像;
图6a为“Alt Moabit”三维立体视频测试序列的一个辅助视点的一帧残差图像;
图6b为“Alt Moabit”三维立体视频测试序列的一个辅助视点的一帧残差图像;
图6c为“Alt Moabit”三维立体视频测试序列的一个辅助视点的一帧残差图像;
图7a为“Book Arrival”三维立体视频测试序列的一个辅助视点的一帧残差图像;
图7b为“Book Arrival”三维立体视频测试序列的一个辅助视点的一帧残差图像;
图7c为“Book Arrival”三维立体视频测试序列的一个辅助视点的一帧残差图像;
图8a为“Dog”三维立体视频测试序列的一个辅助视点的一帧残差图像;
图8b为“Dog”三维立体视频测试序列的一个辅助视点的一帧残差图像;
图8c为“Dog”三维立体视频测试序列的一个辅助视点的一帧残差图像;
图9a为“Pantomime”三维立体视频测试序列的一个辅助视点的一帧残差图像;
图9b为“Pantomime”三维立体视频测试序列的一个辅助视点的一帧残差图像;
图9c为“Pantomime”三维立体视频测试序列的一个辅助视点的一帧残差图像。
具体实施方式
以下结合附图实施例对本发明作进一步详细描述。
交互式三维视频系统如图1所示,其主要由服务端的三维视频编码模块以及用户端的视点解码模块、任意视点绘制模块和视频显示模块构成。本发明提出的一种交互式三维视频系统中的信号处理方法,其包括以下步骤:
①获取t时刻的K个参考视点的K幅颜色空间为YUV的彩色图像及其对应的K幅深度图像,将t时刻的第k个参考视点的彩色图像记为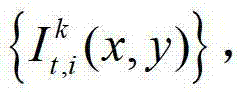 将t时刻的第k个参考视点的深度图像记为
将t时刻的第k个参考视点的深度图像记为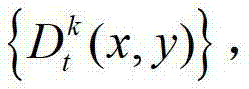 其中,K≥2,1≤k≤K,k的初始值为1,i=1,2,3分别表示YUV颜色空间的三个分量,YUV颜色空间的第1个分量为亮度分量并记为Y、第2个分量为第一色度分量并记为U及第3个分量为第二色度分量并记为V,(x,y)表示彩色图像和深度图像中的像素点的坐标位置,1≤x≤W,1≤y≤H,W表示彩色图像和深度图像的宽度,H表示彩色图像和深度图像的高度,
其中,K≥2,1≤k≤K,k的初始值为1,i=1,2,3分别表示YUV颜色空间的三个分量,YUV颜色空间的第1个分量为亮度分量并记为Y、第2个分量为第一色度分量并记为U及第3个分量为第二色度分量并记为V,(x,y)表示彩色图像和深度图像中的像素点的坐标位置,1≤x≤W,1≤y≤H,W表示彩色图像和深度图像的宽度,H表示彩色图像和深度图像的高度,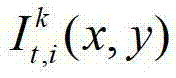 表示t时刻的第k个参考视点的彩色图像
表示t时刻的第k个参考视点的彩色图像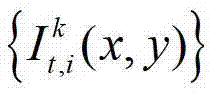 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,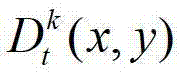 表示t时刻的第k个参考视点的深度图像
表示t时刻的第k个参考视点的深度图像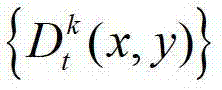 中坐标位置为(x,y)的像素点的深度值。
中坐标位置为(x,y)的像素点的深度值。
在此,截取德国HHI研究所提供的多视点视频序列“Alt Moabit”和“Book Arrival”、日本Nagoya大学提供的多视点视频序列“Dog”和“Pantomime”作为原始三维视频,原始三维视频中各幅立体图像的分辨率都为1024×768,是ISO/MPEG所推荐的标准测试序列,是在三维视频研究领域广泛采用的实验测试序列,图2a和图2b分别给出了三维视频序列“Alt Moabit”的一个参考视点原始视频中的一帧彩色图像和一帧深度图像;图3a和图3b分别给出了三维视频序列“Book Arrival”的一个参考视点原始视频中的一帧彩色图像和一帧深度图像;图4a和图4b分别给出了三维视频序列“Dog”的一个参考视点原始视频中的一帧彩色图像和一帧深度图像;图5a和图5b给出了三维视频序列“Pantomime”的一个参考视点原始视频中的一帧彩色图像和一帧深度图像。
②由于参考视点的数目十分有限,并不直接适合于自由视点交互,必须通过视点绘制技术生成任意虚拟视点位置的视点信息,因此本发明将t时刻的K个参考视点中每相邻的两个参考视点作为一对关联参考视点,将每对关联参考视点之间的N个虚拟视点均作为辅助视点,然后采用基于深度图像绘制的方法,获取t时刻的(K-1)×N个辅助视点各自的残差图像,将t时刻的第l个辅助视点的残差图像记为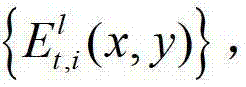 其中,N>1,N的值越大,视点交互的能力就越强,但编码效率会降低,同时编码复杂度会增加,在实际处理过程中可取N=3,1≤l≤(K-1)×N,l的初始值为1,
其中,N>1,N的值越大,视点交互的能力就越强,但编码效率会降低,同时编码复杂度会增加,在实际处理过程中可取N=3,1≤l≤(K-1)×N,l的初始值为1,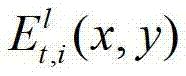 表示t时刻的第l个辅助视点的残差图像
表示t时刻的第l个辅助视点的残差图像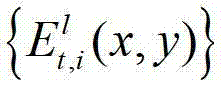 中坐标位置为(x,y)的像素点的第i个分量的值。
中坐标位置为(x,y)的像素点的第i个分量的值。
在此具体实施例中,步骤②的具体过程为:
②-1、将t时刻的K个参考视点中每相邻的两个参考视点作为一对关联参考视点,共存在(K-1)对关联参考视点,将每对关联参考视点之间的距离归一化表示为1,将每对关联参考视点之间的N个虚拟视点均作为辅助视点,共存在(K-1)×N个辅助视点,其中,N>1。
②-2、将t时刻的(K-1)×N个辅助视点中当前正在处理的辅助视点定义为当前辅助视点。
②-3、假设当前辅助视点为t时刻的第k′个参考视点与t时刻的第k′+1个参考视点构成的一对关联参考视点之间的虚拟视点,并假设当前辅助视点为t时刻的(K-1)×N个辅助视点中的第l′个辅助视点,则将当前辅助视点与t时刻的第k′个参考视点之间的距离表示为α,将当前辅助视点与t时刻的第k′+1个参考视点之间的距离表示为1-α,其中,1≤k′≤K-1,k′的初始值为1,(k′-1)×N+1≤l′≤(k′-1)×N+N,0<α<1。
②-4、将t时刻的第k′个参考视点的彩色图像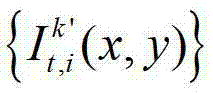 中的每个像素点从第k′个参考视点投影到当前辅助视点,得到t时刻的第k′个参考视点的绘制图像,记为
中的每个像素点从第k′个参考视点投影到当前辅助视点,得到t时刻的第k′个参考视点的绘制图像,记为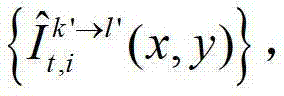 将t时刻的第k′个参考视点的绘制图像
将t时刻的第k′个参考视点的绘制图像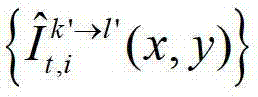 中坐标位置为(x3,y3)的像素点的第i个分量的值记为
中坐标位置为(x3,y3)的像素点的第i个分量的值记为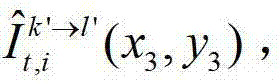 假设t时刻的第k′个参考视点的绘制图像
假设t时刻的第k′个参考视点的绘制图像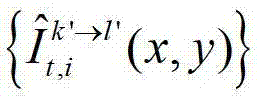 中坐标位置为(x3,y3)的像素点为t时刻的第k′个参考视点的彩色图像
中坐标位置为(x3,y3)的像素点为t时刻的第k′个参考视点的彩色图像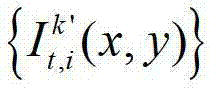 中坐标位置为(x1,y1)的像素点从第k′个参考视点投影到当前辅助视点中的,则令
中坐标位置为(x1,y1)的像素点从第k′个参考视点投影到当前辅助视点中的,则令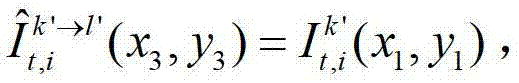 其中,
其中,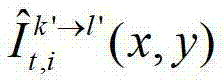 表示t时刻的第k′个参考视点的绘制图像
表示t时刻的第k′个参考视点的绘制图像 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,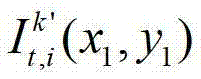 表示t时刻的第k′个参考视点的彩色图像
表示t时刻的第k′个参考视点的彩色图像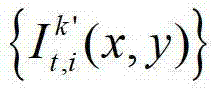 中坐标位置为(x1,y1)的像素点的第i个分量的值,x1∈[1,W],y1∈[1,H],x3∈[1,W],y3∈[1,H],x3=x′/z′,y3=y′/z′,(x′,y′,z′)T=A2R2-1(u,v,w)T-A2R2-1T2,(x′,y′,z′)T为(x′,y′,z′)的转置矩阵,A2为当前辅助视点的内参矩阵,R2-1为R2的逆矩阵,R2为当前辅助视点的旋转矩阵,
中坐标位置为(x1,y1)的像素点的第i个分量的值,x1∈[1,W],y1∈[1,H],x3∈[1,W],y3∈[1,H],x3=x′/z′,y3=y′/z′,(x′,y′,z′)T=A2R2-1(u,v,w)T-A2R2-1T2,(x′,y′,z′)T为(x′,y′,z′)的转置矩阵,A2为当前辅助视点的内参矩阵,R2-1为R2的逆矩阵,R2为当前辅助视点的旋转矩阵,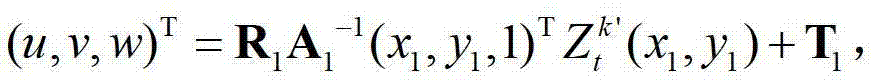 (u,v,w)T为(u,v,w)的转置矩阵,R1为t时刻的第k′个参考视点的旋转矩阵,A1-1为A1的逆矩阵,A1为t时刻的第k′个参考视点的内参矩阵,(x1,y1,1)T为(x1,y1,1)的转置矩阵,T1为t时刻的第k′个参考视点的平移矩阵,T2为当前辅助视点的平移矩阵,
(u,v,w)T为(u,v,w)的转置矩阵,R1为t时刻的第k′个参考视点的旋转矩阵,A1-1为A1的逆矩阵,A1为t时刻的第k′个参考视点的内参矩阵,(x1,y1,1)T为(x1,y1,1)的转置矩阵,T1为t时刻的第k′个参考视点的平移矩阵,T2为当前辅助视点的平移矩阵,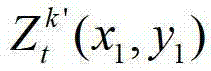 表示t时刻的第k′个参考视点的深度图像
表示t时刻的第k′个参考视点的深度图像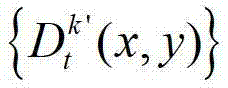 中坐标位置为(x1,y1)的像素点的场景深度,
中坐标位置为(x1,y1)的像素点的场景深度,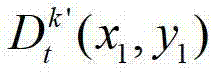 表示t时刻的第k′个参考视点的深度图像
表示t时刻的第k′个参考视点的深度图像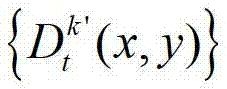 中坐标位置为(x1,y1)的像素点的深度值,Znear表示深度图像中最小的场景深度值,Zfar表示深度图像中最大的场景深度值。
中坐标位置为(x1,y1)的像素点的深度值,Znear表示深度图像中最小的场景深度值,Zfar表示深度图像中最大的场景深度值。
在本实施例中,“Alt Moabit”三维立体视频测试序列的Znear和Zfar分别为11.83775和189.404006,“Book Arrival”三维立体视频测试序列的Znear和Zfar分别为23.175928和54.077165,“Dog”三维立体视频测试序列的Znear和Zfar分别为3907.725727和8221.650623,“Pantomime”三维立体视频测试序列的Znear和Zfar分别为3907.725727和8221.650623。
②-5、将t时刻的第k′+1个参考视点的彩色图像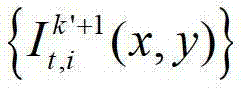 中的每个像素点从第k′+1个参考视点投影到当前辅助视点,得到t时刻的第k′+1个参考视点的绘制图像,记为
中的每个像素点从第k′+1个参考视点投影到当前辅助视点,得到t时刻的第k′+1个参考视点的绘制图像,记为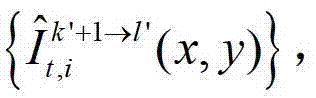 将t时刻的第k′+1个参考视点的绘制图像
将t时刻的第k′+1个参考视点的绘制图像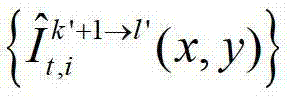 中坐标位置为(x4,y4)的像素点的第i个分量的值记为
中坐标位置为(x4,y4)的像素点的第i个分量的值记为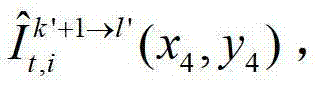 假设t时刻的第k′+1个参考视点的绘制图像
假设t时刻的第k′+1个参考视点的绘制图像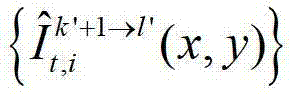 中坐标位置为(x4,y4)的像素点为t时刻的第k′+1个参考视点的彩色图像
中坐标位置为(x4,y4)的像素点为t时刻的第k′+1个参考视点的彩色图像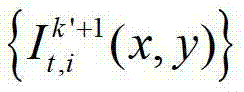 中坐标位置为(x2,y2)的像素点从第k′+1个参考视点投影到当前辅助视点中的,则令
中坐标位置为(x2,y2)的像素点从第k′+1个参考视点投影到当前辅助视点中的,则令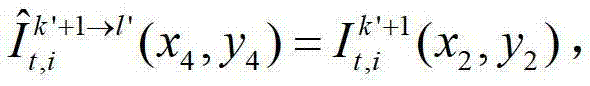 其中,
其中,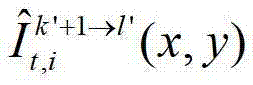 表示t时刻的第k′+1个参考视点的绘制图像
表示t时刻的第k′+1个参考视点的绘制图像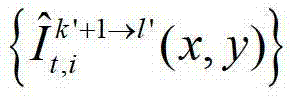 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,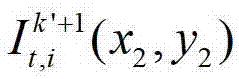 表示t时刻的第k′+1个参考视点的彩色图像
表示t时刻的第k′+1个参考视点的彩色图像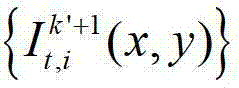 中坐标位置为(x2,y2)的像素点的第i个分量的值,x2∈[1,W],y2∈[1,H],x4∈[1,W],y4∈[1,H],x4=x″/z″,y4=y″/z″,(x″,y″,z″)T=A2R2-1(u′,v′,w′)T-A2R2-1T2,(x″,y″,z″)T为(x″,y″,z″)的转置矩阵,(u′,v′,w′)T为(u′,v′,w′)的转置矩阵,R3为t时刻的第k′+1个参考视点的旋转矩阵,A3-1为A3的逆矩阵,A3为t时刻的第k′+1个参考视点的内参矩阵,(x2,y2,1)T为(x2,y2,1)的转置矩阵,T3为t时刻的第k′+1个参考视点的平移矩阵,
中坐标位置为(x2,y2)的像素点的第i个分量的值,x2∈[1,W],y2∈[1,H],x4∈[1,W],y4∈[1,H],x4=x″/z″,y4=y″/z″,(x″,y″,z″)T=A2R2-1(u′,v′,w′)T-A2R2-1T2,(x″,y″,z″)T为(x″,y″,z″)的转置矩阵,(u′,v′,w′)T为(u′,v′,w′)的转置矩阵,R3为t时刻的第k′+1个参考视点的旋转矩阵,A3-1为A3的逆矩阵,A3为t时刻的第k′+1个参考视点的内参矩阵,(x2,y2,1)T为(x2,y2,1)的转置矩阵,T3为t时刻的第k′+1个参考视点的平移矩阵,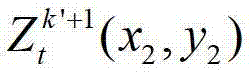 表示t时刻的第k′+1个参考视点的深度图像
表示t时刻的第k′+1个参考视点的深度图像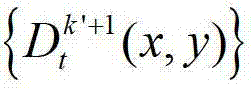 中坐标位置为(x2,y2)的像素点的场景深度,
中坐标位置为(x2,y2)的像素点的场景深度,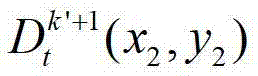 表示t时刻的第k′+1个参考视点的深度图像
表示t时刻的第k′+1个参考视点的深度图像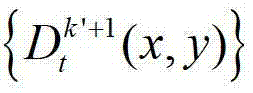 中坐标位置为(x2,y2)的像素点的深度值。
中坐标位置为(x2,y2)的像素点的深度值。
②-6、根据t时刻的第k′个参考视点的绘制图像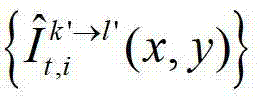 和t时刻的第k′+1个参考视点的绘制图像
和t时刻的第k′+1个参考视点的绘制图像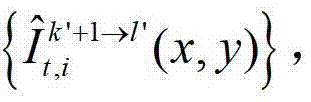 计算当前辅助视点的残差图像,记为
计算当前辅助视点的残差图像,记为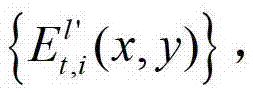 将
将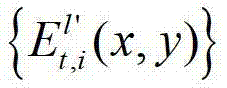 中坐标位置为(x,y)的像素点的第i个分量的值记为
中坐标位置为(x,y)的像素点的第i个分量的值记为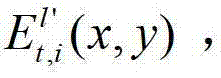
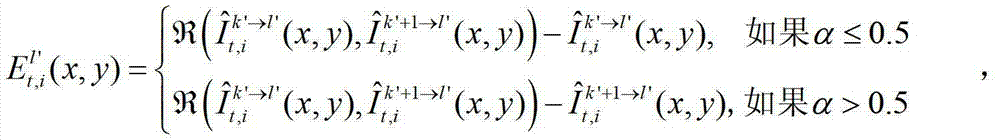 其中,
其中,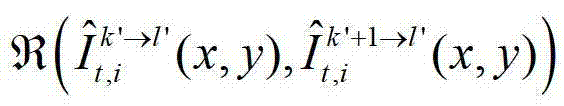 表示对t时刻的第k′个参考视点的绘制图像
表示对t时刻的第k′个参考视点的绘制图像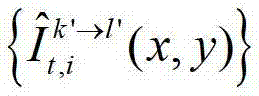 中坐标位置为(x,y)的像素点和t时刻的第k′+1个参考视点的绘制图像
中坐标位置为(x,y)的像素点和t时刻的第k′+1个参考视点的绘制图像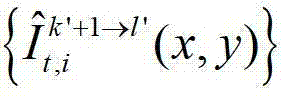 中坐标位置为(x,y)的像素点进行视点融合的操作,在本实施例中,采用与MPEG视点合成参考软件VSRS 3.5相同的视点融合操作。
中坐标位置为(x,y)的像素点进行视点融合的操作,在本实施例中,采用与MPEG视点合成参考软件VSRS 3.5相同的视点融合操作。
②-7、将t时刻的(K-1)×N个辅助视点中下一个待处理的辅助视点作为当前辅助视点,然后返回步骤②-3继续执行,直至t时刻的(K-1)×N个辅助视点均处理完毕,得到t时刻的(K-1)×N个辅助视点各自的残差图像,将t时刻的第l个辅助视点的残差图像记为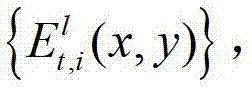 其中,1≤l≤(K-1)×N,l的初始值为1,
其中,1≤l≤(K-1)×N,l的初始值为1,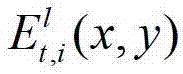 表示t时刻的第l个辅助视点的残差图像
表示t时刻的第l个辅助视点的残差图像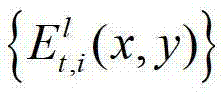 中坐标位置为(x,y)的像素点的第i个分量的值。
中坐标位置为(x,y)的像素点的第i个分量的值。
③服务端的三维视频编码模块根据设定的编码预测结构,对t时刻的K个参考视点的K幅彩色图像及其对应的K幅深度图像、t时刻的(K-1)×N个辅助视点各自的残差图像进行编码,再将编码后的t时刻的K个参考视点的K幅彩色图像及其对应的K幅深度图像、t时刻的(K-1)×N个辅助视点各自的残差图像传输给用户端。
在此,设定的编码预测结构为HBP编码预测结构。
④用户端的视点解码模块对编码后的t时刻的K个参考视点的K幅彩色图像及其对应的K幅深度图像、t时刻的(K-1)×N个辅助视点各自的残差图像进行解码,得到解码后的t时刻的K个参考视点的K幅彩色图像及其对应的K幅深度图像、t时刻的(K-1)×N个辅助视点各自的残差图像,将解码后的t时刻的第k个参考视点的彩色图像记为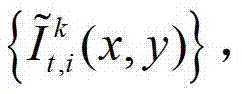 将解码后的t时刻的第k个参考视点的深度图像记为
将解码后的t时刻的第k个参考视点的深度图像记为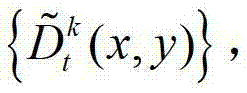 将解码后的t时刻的第l个辅助视点的残差图像记为
将解码后的t时刻的第l个辅助视点的残差图像记为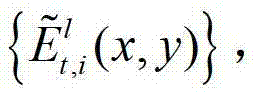 其中,
其中,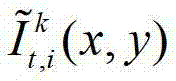 表示解码后的t时刻的第k个参考视点的彩色图像
表示解码后的t时刻的第k个参考视点的彩色图像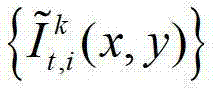 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,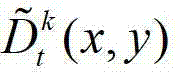 表示解码后的t时刻的第k个参考视点的深度图像
表示解码后的t时刻的第k个参考视点的深度图像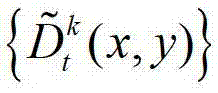 中坐标位置为(x,y)的像素点的深度值,
中坐标位置为(x,y)的像素点的深度值,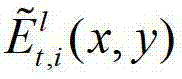 表示解码后的t时刻的第l个辅助视点的残差图像
表示解码后的t时刻的第l个辅助视点的残差图像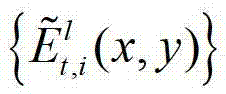 中坐标位置为(x,y)的像素点的第i个分量的值。
中坐标位置为(x,y)的像素点的第i个分量的值。
⑤根据用户所选择的视点,用户端的任意视点绘制模块根据解码后的t时刻的K个参考视点的K幅彩色图像和t时刻的(K-1)×N个辅助视点各自的残差图像,快速生成相应的参考视点信号和辅助视点信号,再将生成的参考视点信号和辅助视点信号传输给用户端的视频显示模块进行显示。
在此具体实施例中,步骤⑤的具体过程为:
⑤-1、假设用户所选择的视点为实际存在的t时刻的第p个参考视点,则用户端的任意视点绘制模块将解码后的t时刻的第p个参考视点的彩色图像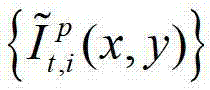 中的每个像素点从t时刻的第p个参考视点投影到t时刻的第l″个辅助视点中,得到t时刻的第p个参考视点的绘制图像,记为
中的每个像素点从t时刻的第p个参考视点投影到t时刻的第l″个辅助视点中,得到t时刻的第p个参考视点的绘制图像,记为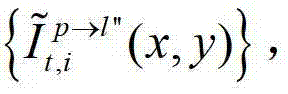 然后根据解码后的t时刻的第p个参考视点的彩色图像
然后根据解码后的t时刻的第p个参考视点的彩色图像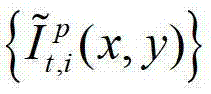 快速生成t时刻的第p个参考视点信号,记为
快速生成t时刻的第p个参考视点信号,记为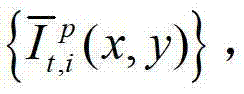 并根据解码后的t时刻的第l″个辅助视点的残差图像
并根据解码后的t时刻的第l″个辅助视点的残差图像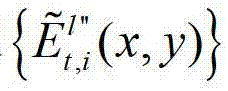 和t时刻的第p个参考视点的绘制图像
和t时刻的第p个参考视点的绘制图像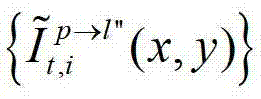 快速生成t时刻的第l″个辅助视点信号,记为
快速生成t时刻的第l″个辅助视点信号,记为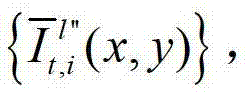 再将生成的t时刻的第p个参考视点信号
再将生成的t时刻的第p个参考视点信号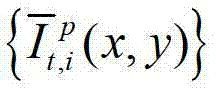 和t时刻的第l″个辅助视点信号
和t时刻的第l″个辅助视点信号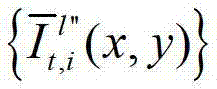 传输给用户端的视频显示模块进行显示,其中,此处1≤p≤K-1,此处l″=(p-1)×N+1,
传输给用户端的视频显示模块进行显示,其中,此处1≤p≤K-1,此处l″=(p-1)×N+1,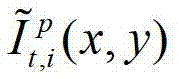 表示解码后的t时刻的第p个参考视点的彩色图像
表示解码后的t时刻的第p个参考视点的彩色图像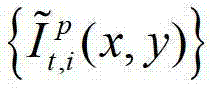 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,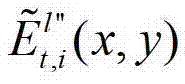 表示解码后的t时刻的第l″个辅助视点的残差图像
表示解码后的t时刻的第l″个辅助视点的残差图像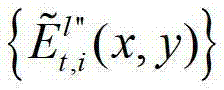 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,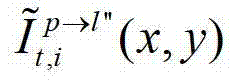 表示t时刻的第p个参考视点的绘制图像
表示t时刻的第p个参考视点的绘制图像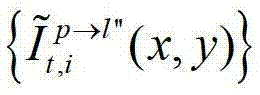 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,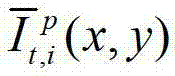 表示生成的t时刻的第p个参考视点信号
表示生成的t时刻的第p个参考视点信号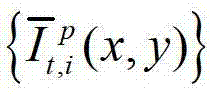 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,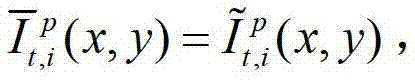
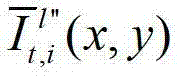 表示生成的t时刻的第l″个辅助视点信号
表示生成的t时刻的第l″个辅助视点信号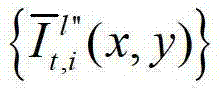 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,
⑤-2、假设用户所选择的视点为实际存在的t时刻的第K个参考视点,则用户端的任意视点绘制模块将解码后的t时刻的第K个参考视点的彩色图像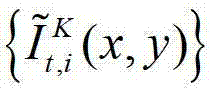 中的每个像素点从t时刻的第K个参考视点投影到t时刻的第l″个辅助视点中,得到t时刻的第K个参考视点的绘制图像,记为
中的每个像素点从t时刻的第K个参考视点投影到t时刻的第l″个辅助视点中,得到t时刻的第K个参考视点的绘制图像,记为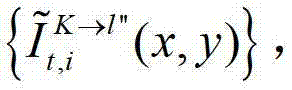 然后根据解码后的t时刻的第K个参考视点的彩色图像
然后根据解码后的t时刻的第K个参考视点的彩色图像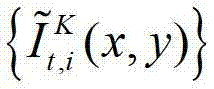 快速生成t时刻的第K个参考视点信号,记为
快速生成t时刻的第K个参考视点信号,记为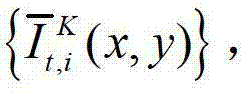 并根据解码后的t时刻的第l″个辅助视点的残差图像
并根据解码后的t时刻的第l″个辅助视点的残差图像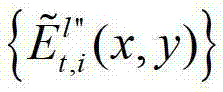 和t时刻的第K个参考视点的绘制图像
和t时刻的第K个参考视点的绘制图像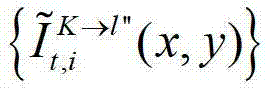 快速生成t时刻的第l″个辅助视点信号,记为
快速生成t时刻的第l″个辅助视点信号,记为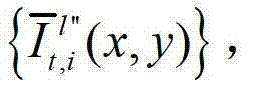 再将生成的t时刻的第K个参考视点信号
再将生成的t时刻的第K个参考视点信号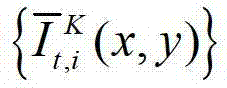 和t时刻的第l″个辅助视点信号
和t时刻的第l″个辅助视点信号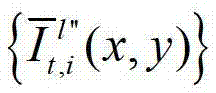 传输给用户端的视频显示模块进行显示,其中,此处l″=(K-1)×N,
传输给用户端的视频显示模块进行显示,其中,此处l″=(K-1)×N,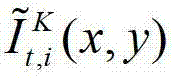 表示解码后的t时刻的第K个参考视点的彩色图像
表示解码后的t时刻的第K个参考视点的彩色图像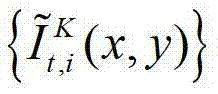 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,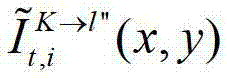 表示t时刻的第K个参考视点的绘制图像
表示t时刻的第K个参考视点的绘制图像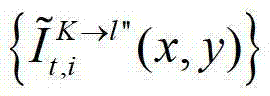 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,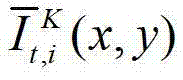 表示生成的t时刻的第K个参考视点信号
表示生成的t时刻的第K个参考视点信号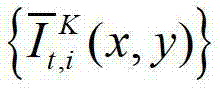 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,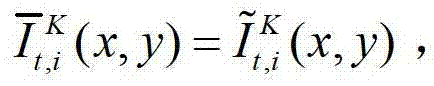
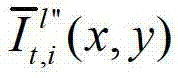 表示生成的t时刻的第l″个辅助视点信号
表示生成的t时刻的第l″个辅助视点信号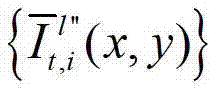 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,
⑤-3-1、假设用户所选择的视点为并不存在的虚拟视点,则选择与该虚拟视点最为邻近的两个辅助视点,假设分别为t时刻的第l″′个辅助视点和t时刻的第l″′+1个辅助视点,并且令与t时刻的第l″′个辅助视点左相邻的参考视点为t时刻的第q1个参考视点,令与t时刻的第l″′+1个辅助视点左相邻的参考视点为t时刻的第q2个参考视点,将t时刻的第l″′个辅助视点与t时刻的第q1个参考视点之间的距离表示为β,将t时刻的第l″′+1个辅助视点与第q2个参考视点之间的距离表示为γ,其中,1≤l″′≤(K-1)×N-1,1≤q1≤K-1,1≤q2≤K-1,0<β<1,0<γ<1。
⑤-3-2、用户端的任意视点绘制模块将解码后的t时刻的第q1个参考视点的彩色图像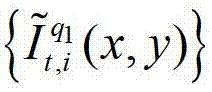 中的每个像素点从t时刻的第q1个参考视点投影到t时刻的第l″′个辅助视点中,得到t时刻的第q1个参考视点的绘制图像,记为
中的每个像素点从t时刻的第q1个参考视点投影到t时刻的第l″′个辅助视点中,得到t时刻的第q1个参考视点的绘制图像,记为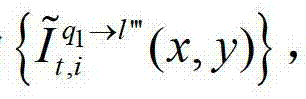 或者将解码后的t时刻的第q1+1个参考视点的彩色图像
或者将解码后的t时刻的第q1+1个参考视点的彩色图像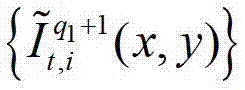 中的每个像素点从t时刻的第q1+1个参考视点投影到t时刻的第l″′个辅助视点中,得到t时刻的第q1+1个参考视点的绘制图像,记为
中的每个像素点从t时刻的第q1+1个参考视点投影到t时刻的第l″′个辅助视点中,得到t时刻的第q1+1个参考视点的绘制图像,记为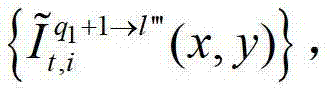 然后根据解码后的t时刻的第l″′个辅助视点的残差图像
然后根据解码后的t时刻的第l″′个辅助视点的残差图像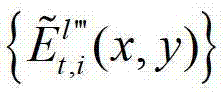 及t时刻的第q1个参考视点的绘制图像
及t时刻的第q1个参考视点的绘制图像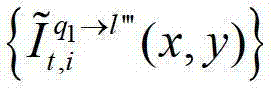 或t时刻的第q1+1个参考视点的绘制图像
或t时刻的第q1+1个参考视点的绘制图像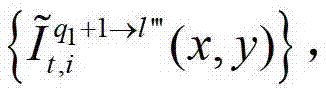 快速生成t时刻的第l″′个辅助视点信号,记为
快速生成t时刻的第l″′个辅助视点信号,记为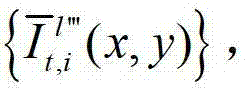 其中,
其中,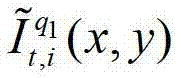 表示解码后的t时刻的第q1个参考视点的彩色图像
表示解码后的t时刻的第q1个参考视点的彩色图像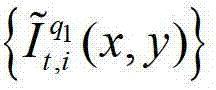 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,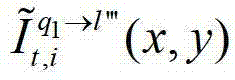 表示t时刻的第q1个参考视点的绘制图像
表示t时刻的第q1个参考视点的绘制图像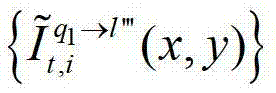 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,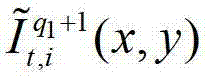 表示解码后的t时刻的第q1+1个参考视点的彩色图像
表示解码后的t时刻的第q1+1个参考视点的彩色图像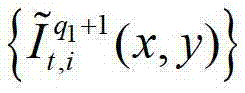 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,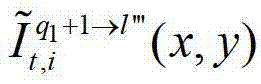 表示t时刻的第q1+1个参考视点的绘制图像
表示t时刻的第q1+1个参考视点的绘制图像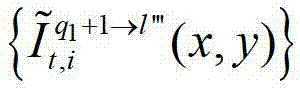 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,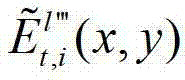 表示解码后的t时刻的第l″′个辅助视点的残差图像
表示解码后的t时刻的第l″′个辅助视点的残差图像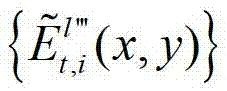 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,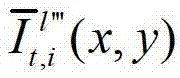 表示生成的t时刻的第l″′个辅助视点信号
表示生成的t时刻的第l″′个辅助视点信号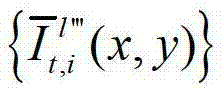 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,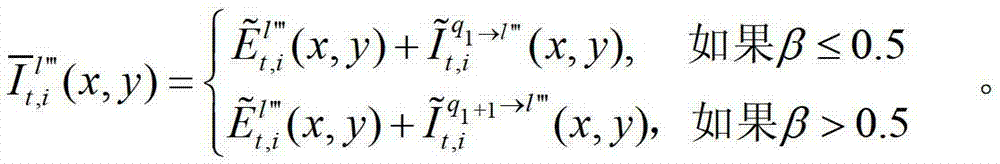
⑤-3-3、用户端的任意视点绘制模块将解码后的t时刻的第q2个参考视点的彩色图像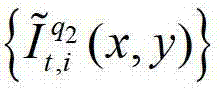 中的每个像素点从t时刻的第q2个参考视点投影到t时刻的第l″′+1个辅助视点中,得到t时刻的第q2个参考视点的绘制图像,记为
中的每个像素点从t时刻的第q2个参考视点投影到t时刻的第l″′+1个辅助视点中,得到t时刻的第q2个参考视点的绘制图像,记为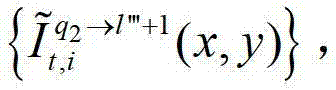 或者将解码后的t时刻的第q2+1个参考视点的彩色图像
或者将解码后的t时刻的第q2+1个参考视点的彩色图像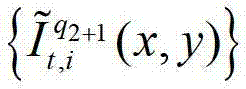 中的每个像素点从t时刻的第q2+1个参考视点投影到t时刻的第l″′+1个辅助视点中,得到t时刻的第q2+1个参考视点的绘制图像,记为
中的每个像素点从t时刻的第q2+1个参考视点投影到t时刻的第l″′+1个辅助视点中,得到t时刻的第q2+1个参考视点的绘制图像,记为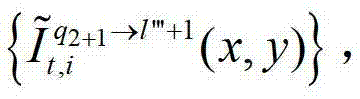 然后根据解码后的t时刻的第l″′+1个辅助视点的残差图像
然后根据解码后的t时刻的第l″′+1个辅助视点的残差图像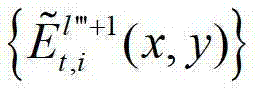 及t时刻的第q2个参考视点的绘制图像
及t时刻的第q2个参考视点的绘制图像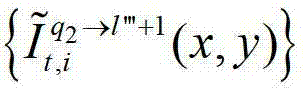 或t时刻的第q2+1个参考视点的绘制图像
或t时刻的第q2+1个参考视点的绘制图像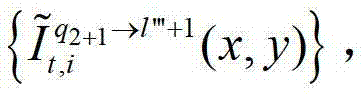 快速生成t时刻的第l″′+1个辅助视点信号,记为
快速生成t时刻的第l″′+1个辅助视点信号,记为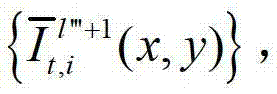 其中,
其中,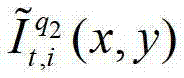 表示解码后的t时刻的第q2个参考视点的彩色图像
表示解码后的t时刻的第q2个参考视点的彩色图像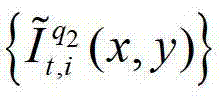 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,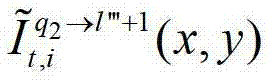 表示t时刻的第q2个参考视点的绘制图像
表示t时刻的第q2个参考视点的绘制图像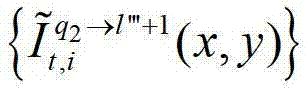 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,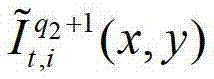 表示解码后的t时刻的第q2+1个参考视点的彩色图像
表示解码后的t时刻的第q2+1个参考视点的彩色图像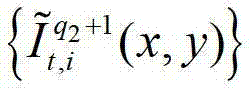 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,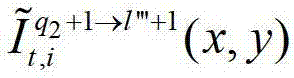 表示t时刻的第q2+1个参考视点的绘制图像
表示t时刻的第q2+1个参考视点的绘制图像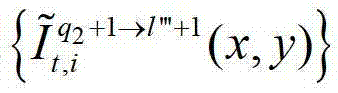 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,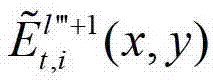 表示解码后的t时刻的第l″′+1个辅助视点的残差图像
表示解码后的t时刻的第l″′+1个辅助视点的残差图像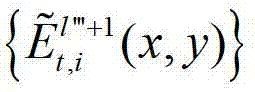 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,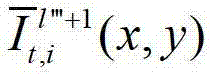 表示生成的t时刻的第l″′+1个辅助视点信号
表示生成的t时刻的第l″′+1个辅助视点信号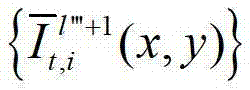 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,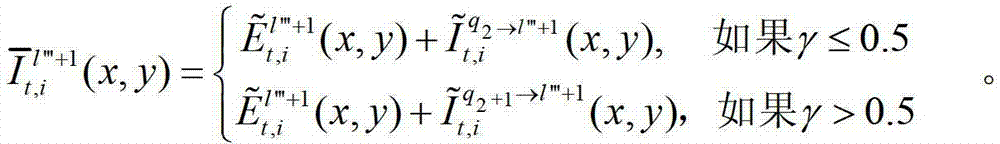
⑤-3-4、用户端的任意视点绘制模块将生成的t时刻的第l″′个辅助视点信号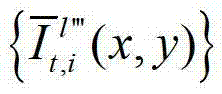 和t时刻的第l″′+1个辅助视点信号
和t时刻的第l″′+1个辅助视点信号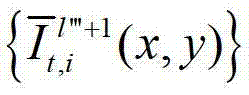 传输给用户端的视频显示模块进行显示。
传输给用户端的视频显示模块进行显示。
以下就利用本发明方法对“Alt Moabit”、“Book Arrival”、“Dog”和“Pantomime”三维视频测试序列进行立体视频编码的编码性能、编码复杂度和视点交互复杂度进行比较。
由于本发明方法只需要传输辅助视点的残差图像,与传统的整幅图像传输的编码方法相比,需要编码传输的数据明显下降。表1给出了利用本发明方法与传统编码方法的编码性能比较,从表1中可以看出,采用本发明方法对各个辅助视点进行编码,其编码码率能够节省88.15%~98.58%,能明显降低对网络带宽的要求,这足以说明本发明方法是有效可行的。
图6a、图6b和图6c分别给出了“Alt Moabit”三维立体视频测试序列的三个辅助视点的一帧残差图像;图7a、图7b和图7c分别给出了“Book Arrival”三维立体视频测试序列的三个辅助视点的一帧残差图像;图8a、图8b和图8c分别给出了“Dog”三维立体视频测试序列的三个辅助视点的一帧残差图像;图9a、图9b和图9c分别给出了“Pantomime”三维立体视频测试序列的三个辅助视点的一帧残差图像,其中,白色区域表示的是非编码宏块。表2给出了利用本发明方法的非编码宏块的比重,从表2中可以看出,非编码宏块占的比重平均达到97%以上,这样大大降低了系统服务端的编码复杂程度,有利于视频的实时性传输。
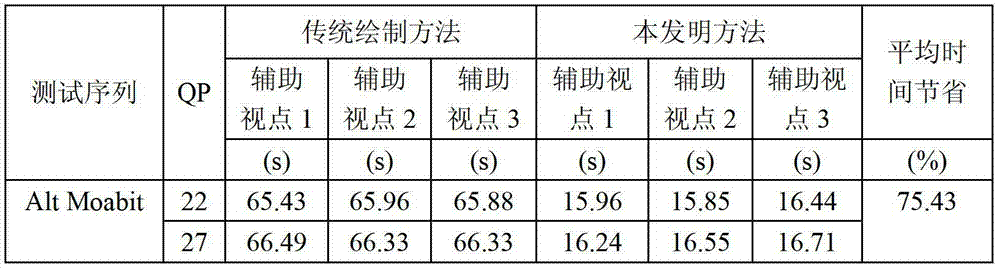
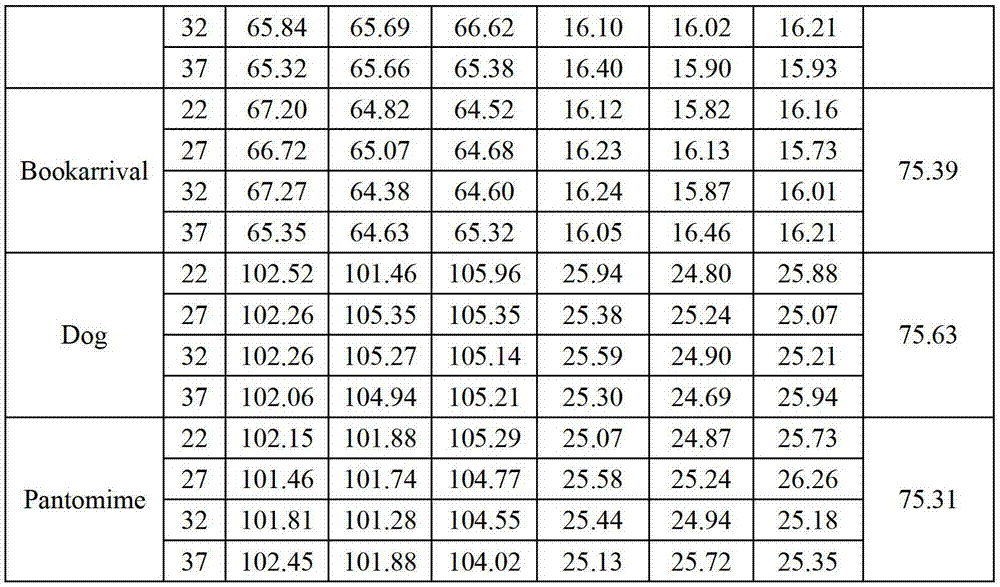
表3给出了利用本发明方法与MPEG视点合成参考软件VSRS 3.5的计算复杂度比较。从表3中可以看出,本发明方法的绘制时间可节省75.31~75.63%,这是因为视点合成参考软件VSRS 3.5需要进行复杂的三维映射和视点融合操作,而本发明方法只需要在用户端进行简单的加法操作就能生成虚拟视点信号,其绘制计算复杂度能够明显下降,这样有效地降低了对用户端系统资源的要求。
表1 利用本发明方法与传统的整幅图像传输的编码方法的编码性能比较
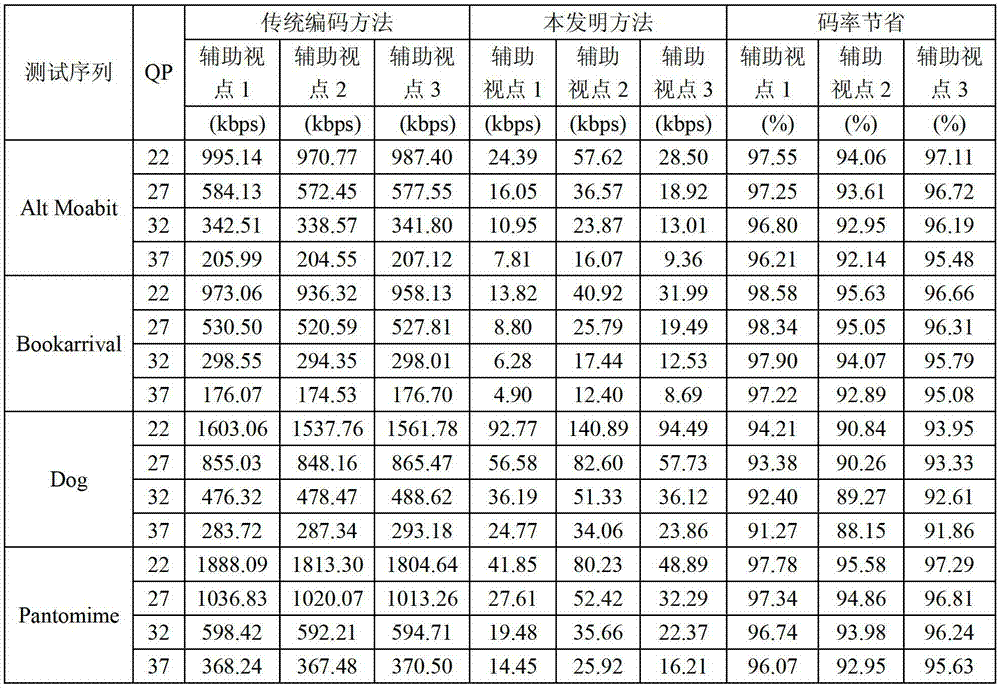
表2 利用本发明方法的非编码宏块的比重
表3 利用本发明方法与MPEG视点合成参考软件VSRS 3.5的绘制复杂度比较

 手机二维码
手机二维码 京公网安备11011302007134
京公网安备11011302007134