技术领域
本发明涉及一种视频信号的编码压缩方法,尤其是涉及一种深度图像编码方法。
背景技术
进入本世纪以来,随着数字2D(二维)视频技术日趋成熟,以及计算机、通信及网络技术的快速发展,引发了人们对新一代视频系统的强烈需求。现行的二维视频系统在表现自然场景时,难以满足用户的立体感和视点交互等的需求。三维视频系统由于能够提供立体感、视点交互性的全新视觉体验而越来越受到人们的欢迎,因此在无线视频通信、影视娱乐、数字动漫、虚拟战场、旅游观光、远程教学等领域有着广泛的应用前景。与单通道视频相比,三维视频要处理至少翻一倍的数据量,因此在不影响三维视频主观质量的前提下,尽可能地降低三维视频的编码码率是一个亟需解决的问题。
然而,与彩色图像相比,深度图像的纹理简单,其包括较多的平坦区域,但由于深度图像获取算法的局限性,因此深度图像普遍存在时间连续性差、深度不连续等问题。目前已提出了一些针对深度图像的编码方法,然而这些编码方法考虑更多的是如何提升编码的性能,因此,如何更好地表征深度图像的局部分布特性(深度图像不同区域对绘制的影响是不一致的),如何更好地利用视点之间的冗余特性(相邻视点的深度图像存在视觉冗余信息),都是在对深度图像进行编码时需要解决的问题。
发明内容
本发明所要解决的技术问题是提供一种能够充分地消除深度图像的视觉冗余信息,并能够有效地提高虚拟视点图像质量和编码效率的深度图像编码方法。
本发明解决上述技术问题所采用的技术方案为:一种深度图像编码方法,其特征在于它具体包括以下步骤:
①将外部立体视频捕获工具捕获得到的未经处理的且颜色空间为YUV的彩色立体视频及其对应的深度立体视频定义为原始三维立体视频,该原始三维立体视频由原始左视点彩色图像、原始右视点彩色图像、原始左视点深度图像和原始右视点深度图像组成, 将t时刻的原始左视点彩色图像记为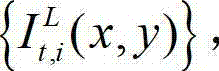 将t时刻的原始右视点彩色图像记为
将t时刻的原始右视点彩色图像记为 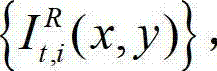 将t时刻的原始左视点深度图像记为
将t时刻的原始左视点深度图像记为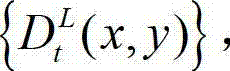 将t时刻的原始右视点深度图像记为
将t时刻的原始右视点深度图像记为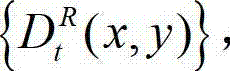 其中,i=1,2,3分别表示YUV颜色空间的三个分量,YUV颜色空间的第1个分量为亮度分量并记为Y、第2个分量为第一色度分量并记为U及第3个分量为第二色度分量并记为V,(x,y)表示彩色图像和深度图像中的像素点的坐标位置,1≤x≤W,1≤y≤H,W表示彩色图像和深度图像的宽度,H表示彩色图像和深度图像的高度,
其中,i=1,2,3分别表示YUV颜色空间的三个分量,YUV颜色空间的第1个分量为亮度分量并记为Y、第2个分量为第一色度分量并记为U及第3个分量为第二色度分量并记为V,(x,y)表示彩色图像和深度图像中的像素点的坐标位置,1≤x≤W,1≤y≤H,W表示彩色图像和深度图像的宽度,H表示彩色图像和深度图像的高度,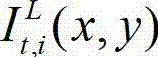 表示t时刻的原始左视点彩色图像
表示t时刻的原始左视点彩色图像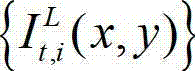 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,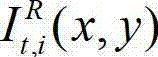 表示t时刻的原始右视点彩色图像
表示t时刻的原始右视点彩色图像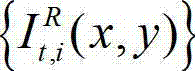 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,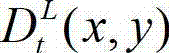 表示t时刻的原始左视点深度图像
表示t时刻的原始左视点深度图像 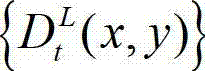 中坐标位置为(x,y)的像素点的深度值,
中坐标位置为(x,y)的像素点的深度值,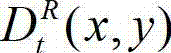 表示t时刻的原始右视点深度图像
表示t时刻的原始右视点深度图像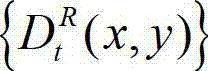 中坐标位置为(x,y)的像素点的深度值;
中坐标位置为(x,y)的像素点的深度值;
②利用人类视觉对背景光照和纹理的视觉掩蔽效应,提取出t时刻的原始左视点彩色图像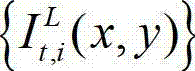 的最小可察觉变化步长图像,记为
的最小可察觉变化步长图像,记为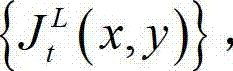 其中,
其中,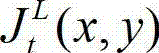 表示
表示 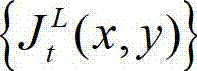 中坐标位置为(x,y)的像素点的最小可察觉变化步长值;
中坐标位置为(x,y)的像素点的最小可察觉变化步长值;
③根据t时刻的原始左视点彩色图像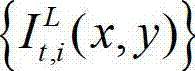 的最小可察觉变化步长图像
的最小可察觉变化步长图像 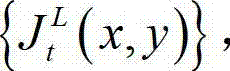 提取出t时刻的原始左视点深度图像
提取出t时刻的原始左视点深度图像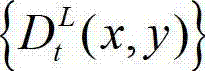 的最大可容忍失真分布图像,记为
的最大可容忍失真分布图像,记为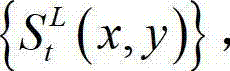 其中,
其中,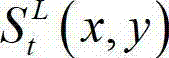 表示
表示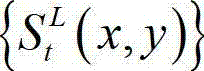 中坐标位置为(x,y)的像素点的最大可容忍失真值;
中坐标位置为(x,y)的像素点的最大可容忍失真值;
④采用基于深度图像绘制的方法,将t时刻的原始左视点深度图像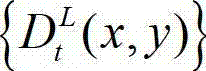 从左视点投影到右视点,得到t时刻的原始右视点深度图像的绘制图像,记为
从左视点投影到右视点,得到t时刻的原始右视点深度图像的绘制图像,记为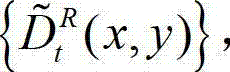 其中,
其中, 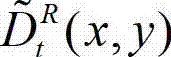 表示t时刻的原始右视点深度图像的绘制图像
表示t时刻的原始右视点深度图像的绘制图像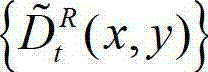 中坐标位置为(x,y)的像素点的深度值;
中坐标位置为(x,y)的像素点的深度值;
⑤计算t时刻的原始右视点深度图像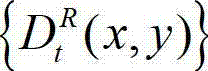 与t时刻的原始右视点深度图像的绘 制图像
与t时刻的原始右视点深度图像的绘 制图像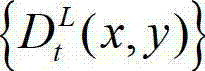 的残差图像,记为
的残差图像,记为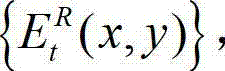 将
将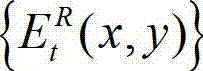 中坐标位置为(x,y)的像素点的像素值记为
中坐标位置为(x,y)的像素点的像素值记为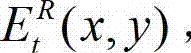
⑥根据t时刻的原始左视点深度图像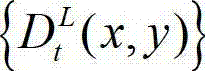 的最大可容忍失真分布图像
的最大可容忍失真分布图像 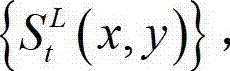 并根据设定的编码预测结构对t时刻的原始左视点深度图像进行编码,再将编码后的t时刻的左视点深度图像经网络传输给解码端;在解码端对编码后的t时刻的左视点深度图像进行解码,获得解码后的t时刻的左视点深度图像,记为
并根据设定的编码预测结构对t时刻的原始左视点深度图像进行编码,再将编码后的t时刻的左视点深度图像经网络传输给解码端;在解码端对编码后的t时刻的左视点深度图像进行解码,获得解码后的t时刻的左视点深度图像,记为 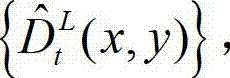 其中,
其中,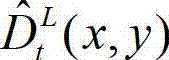 表示解码后的t时刻的左视点深度图像
表示解码后的t时刻的左视点深度图像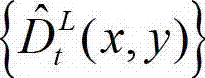 中坐标位置为(x,y)的像素点的深度值;
中坐标位置为(x,y)的像素点的深度值;
⑦根据设定的编码预测结构对t时刻的原始右视点深度图像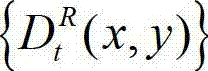 与t时刻的原始右视点深度图像的绘制图像
与t时刻的原始右视点深度图像的绘制图像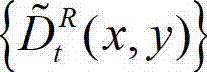 的残差图像
的残差图像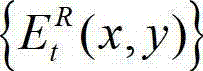 进行编码,再将编码后的t时刻的残差图像经网络传输给解码端;在解码端对编码后的t时刻的残差图像进行解码,获得解码后的t时刻的残差图像,记为
进行编码,再将编码后的t时刻的残差图像经网络传输给解码端;在解码端对编码后的t时刻的残差图像进行解码,获得解码后的t时刻的残差图像,记为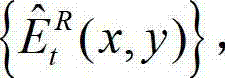 其中,
其中,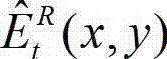 表示解码后的t时刻的残差图像
表示解码后的t时刻的残差图像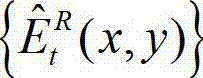 中坐标位置为(x,y)的像素点的像素值;
中坐标位置为(x,y)的像素点的像素值;
⑧采用与步骤④相同的操作,将解码后的t时刻的左视点深度图像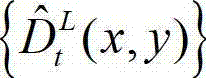 从左视点投影到右视点,得到解码后的t时刻的右视点深度图像的绘制图像,记为
从左视点投影到右视点,得到解码后的t时刻的右视点深度图像的绘制图像,记为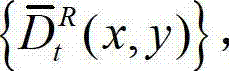 其中,
其中,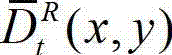 表示解码后的t时刻的右视点深度图像的绘制图像
表示解码后的t时刻的右视点深度图像的绘制图像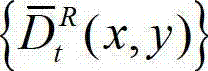 中坐标位置为(x,y)的像素点的深度值;
中坐标位置为(x,y)的像素点的深度值;
⑨根据解码后的t时刻的右视点深度图像的绘制图像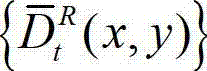 和解码后的t时刻的残差图像
和解码后的t时刻的残差图像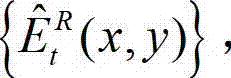 得到解码后的t时刻的右视点深度图像的重构图像,记为
得到解码后的t时刻的右视点深度图像的重构图像,记为 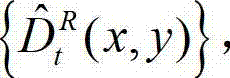 其中,
其中,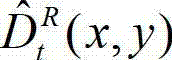 表示解码后的t时刻的右视点深度图像的重构图像
表示解码后的t时刻的右视点深度图像的重构图像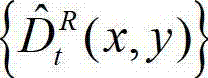 中坐标位置为(x,y)的像素点的深度值。
中坐标位置为(x,y)的像素点的深度值。
所述的步骤②的具体过程为:
②-1、计算t时刻的原始左视点彩色图像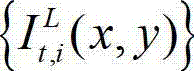 的背景光照的视觉掩蔽效应的可 视化阈值集合,记为{Tl(x,y)},
的背景光照的视觉掩蔽效应的可 视化阈值集合,记为{Tl(x,y)},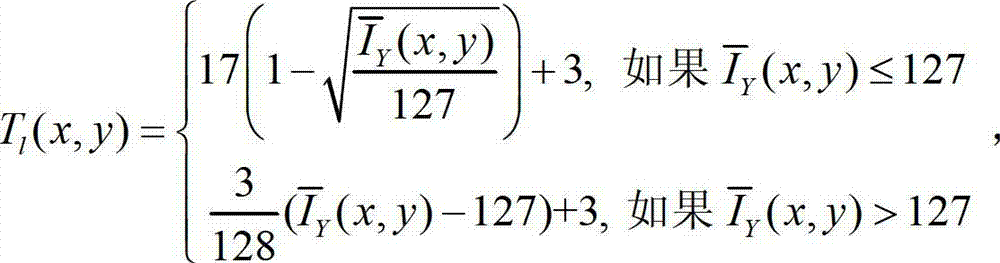 其中,Tl(x,y)表示t时刻的原始左视点彩色图像
其中,Tl(x,y)表示t时刻的原始左视点彩色图像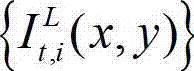 中坐标位置为(x,y)的像素点的背景光照的视觉掩蔽效应的可视化阈值,
中坐标位置为(x,y)的像素点的背景光照的视觉掩蔽效应的可视化阈值,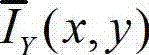 表示t时刻的原始左视点彩色图像
表示t时刻的原始左视点彩色图像 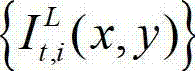 中以坐标位置为(x,y)的像素点为中心的N×N邻域窗口内的所有像素点的亮度平均值;
中以坐标位置为(x,y)的像素点为中心的N×N邻域窗口内的所有像素点的亮度平均值;
②-2、计算t时刻的原始左视点彩色图像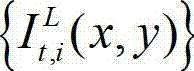 的纹理的视觉掩蔽效应的可视化阈值集合,记为{Tt(x,y)},Tt(x,y)=η×G(x,y)×We(x,y),其中,Tt(x,y)表示t时刻的原始左视点彩色图像
的纹理的视觉掩蔽效应的可视化阈值集合,记为{Tt(x,y)},Tt(x,y)=η×G(x,y)×We(x,y),其中,Tt(x,y)表示t时刻的原始左视点彩色图像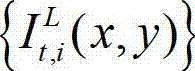 中坐标位置为(x,y)的像素点的纹理的视觉掩蔽效应的可视化阈值,η为大于0的控制因子,G(x,y)表示对t时刻的原始左视点彩色图像
中坐标位置为(x,y)的像素点的纹理的视觉掩蔽效应的可视化阈值,η为大于0的控制因子,G(x,y)表示对t时刻的原始左视点彩色图像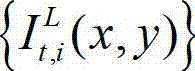 中坐标位置为(x,y)的像素点进行定向高通滤波得到的最大加权平均值,We(x,y)表示对t时刻的原始左视点彩色图像
中坐标位置为(x,y)的像素点进行定向高通滤波得到的最大加权平均值,We(x,y)表示对t时刻的原始左视点彩色图像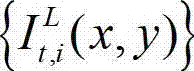 的边缘图像中坐标位置为(x,y)的像素点进行高斯低通滤波得到的边缘加权值;
的边缘图像中坐标位置为(x,y)的像素点进行高斯低通滤波得到的边缘加权值;
②-3、对t时刻的原始左视点彩色图像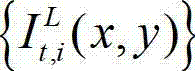 的背景光照的视觉掩蔽效应的可视化阈值集合{Tl(x,y)}和纹理的视觉掩蔽效应的可视化阈值集合{Tt(x,y)}进行融合,得到t时刻的原始左视点彩色图像
的背景光照的视觉掩蔽效应的可视化阈值集合{Tl(x,y)}和纹理的视觉掩蔽效应的可视化阈值集合{Tt(x,y)}进行融合,得到t时刻的原始左视点彩色图像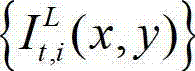 的最小可察觉变化步长图像,记为
的最小可察觉变化步长图像,记为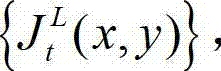 将
将 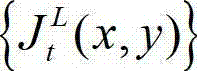 中坐标位置为(x,y)的像素点的最小可察觉变化步长值记为
中坐标位置为(x,y)的像素点的最小可察觉变化步长值记为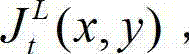 其中,Cl,t表示控制背景光照和纹理的视觉掩蔽效应重叠影响的参数,0<Cl,t<1,min{}为取最小值函数。
其中,Cl,t表示控制背景光照和纹理的视觉掩蔽效应重叠影响的参数,0<Cl,t<1,min{}为取最小值函数。
所述的步骤②-1中取N的值为5;所述的步骤②-2中取η=0.05;所述的步骤②-3中取Cl,t=0.5。
所述的步骤③的具体过程为:
③-1、定义t时刻的原始左视点深度图像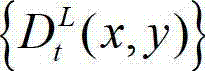 中当前正在处理的像素点为当前像素点;
中当前正在处理的像素点为当前像素点;
③-2、将当前像素点的坐标位置记为(x1,y1),将与当前像素点水平相邻的像素点的坐标位置记为(x1+Δx,y1),计算当前像素点和与其水平相邻的像素点之间的颜色距离,记为Ψ(x1+Δx,y1),计算当前像素点和与其水平相邻的像素点之间的深度距离,记为Φ(x1+Δx,y1), 其中,x1∈[1,W],y1∈[1,H],Δx表示水平偏移量,-W'≤Δx<0或0<Δx≤W',W'表示最大水平偏移量,“||”为取绝对值符号, 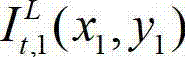 表示t时刻原始左视点彩色图像
表示t时刻原始左视点彩色图像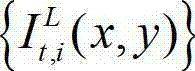 中坐标位置为(x1,y1)的像素点的Y分量的值,
中坐标位置为(x1,y1)的像素点的Y分量的值,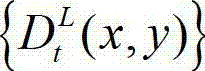 表示t时刻原始左视点彩色图像
表示t时刻原始左视点彩色图像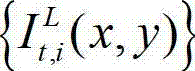 中坐标位置为(x1+Δx,y1)的像素点的Y分量的值,
中坐标位置为(x1+Δx,y1)的像素点的Y分量的值,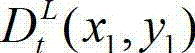 表示t时刻的原始左视点深度图像
表示t时刻的原始左视点深度图像 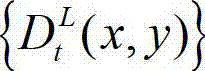 中坐标位置为(x1,y1)的像素点的深度值,
中坐标位置为(x1,y1)的像素点的深度值,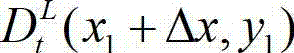 表示t时刻的原始左视点深度图像中坐标位置为(x1+Δx,y1)的像素点的深度值;
表示t时刻的原始左视点深度图像中坐标位置为(x1+Δx,y1)的像素点的深度值;
③-3、从当前像素点的左方向水平偏移量集合{ΔxL|-W'≤ΔxL≤-1}中任取一个ΔxL,如果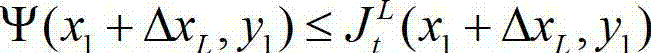 且Φ(x1+ΔxL,y1)≤T同时成立,则认为ΔxL为当前像素点的一个左方向可容忍失真值;采用相同的方法计算当前像素点的左方向水平偏移量集合中的所有左方向可容忍失真值,再从所有左方向可容忍失真值中找出绝对值最大的左方向可容忍失真值,将绝对值最大的左方向可容忍失真值作为当前像素点的左方向最大可容忍失真值,记为ΔL(x1,y1),其中,Ψ(x1+ΔxL,y1)表示当前像素点和坐标位置为(x1+ΔxL,y1)的像素点之间的颜色距离,
且Φ(x1+ΔxL,y1)≤T同时成立,则认为ΔxL为当前像素点的一个左方向可容忍失真值;采用相同的方法计算当前像素点的左方向水平偏移量集合中的所有左方向可容忍失真值,再从所有左方向可容忍失真值中找出绝对值最大的左方向可容忍失真值,将绝对值最大的左方向可容忍失真值作为当前像素点的左方向最大可容忍失真值,记为ΔL(x1,y1),其中,Ψ(x1+ΔxL,y1)表示当前像素点和坐标位置为(x1+ΔxL,y1)的像素点之间的颜色距离,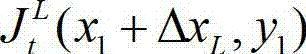 表示
表示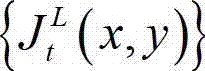 中坐标位置为(x1+ΔxL,y1)的像素点的最小可察觉变化步长值,Φ(x1+ΔxL,y1)表示当前像素点和坐标位置为(x1+ΔxL,y1)的像素点之间的深度距离,T为深度敏感性阈值;
中坐标位置为(x1+ΔxL,y1)的像素点的最小可察觉变化步长值,Φ(x1+ΔxL,y1)表示当前像素点和坐标位置为(x1+ΔxL,y1)的像素点之间的深度距离,T为深度敏感性阈值;
③-4、从当前像素点的右方向水平偏移量集合{ΔxR|1≤ΔxR≤W'}中任取一个ΔxR, 如果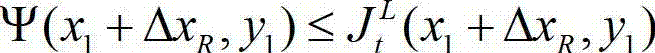 且Φ(x1+ΔxR,y1)≤T同时成立,则认为ΔxR为当前像素点的一个右方向可容忍失真值;采用相同的方法计算当前像素点的右方向水平偏移量集合中的所有右方向可容忍失真值,再从所有右方向可容忍失真值中找出绝对值最大的右方向可容忍失真值,将绝对值最大的右方向可容忍失真值作为当前像素点的右方向最大可容忍失真值,记为ΔR(x1,y1),其中,Ψ(x1+ΔxR,y1)表示当前像素点和坐标位置为(x1+ΔxR,y1)的像素点之间的颜色距离,
且Φ(x1+ΔxR,y1)≤T同时成立,则认为ΔxR为当前像素点的一个右方向可容忍失真值;采用相同的方法计算当前像素点的右方向水平偏移量集合中的所有右方向可容忍失真值,再从所有右方向可容忍失真值中找出绝对值最大的右方向可容忍失真值,将绝对值最大的右方向可容忍失真值作为当前像素点的右方向最大可容忍失真值,记为ΔR(x1,y1),其中,Ψ(x1+ΔxR,y1)表示当前像素点和坐标位置为(x1+ΔxR,y1)的像素点之间的颜色距离,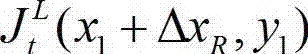 表示
表示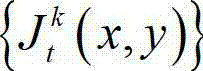 中坐标位置为(x1+ΔxR,y1)的像素点的最小可察觉变化步长值,Φ(x1+ΔxR,y1)表示当前像素点和坐标位置为(x1+ΔxR,y1)的像素点之间的深度距离;
中坐标位置为(x1+ΔxR,y1)的像素点的最小可察觉变化步长值,Φ(x1+ΔxR,y1)表示当前像素点和坐标位置为(x1+ΔxR,y1)的像素点之间的深度距离;
③-5、找出当前像素点的左方向最大可容忍失真值ΔL(x1,y1)和右方向最大可容忍失真值ΔR(x1,y1)中绝对值最小的可容忍失真值,作为当前像素点的最大可容忍失真值,记为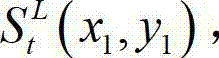 min{}为取最小值函数,“||”为取绝对值符号;
min{}为取最小值函数,“||”为取绝对值符号;
③-6、将t时刻的原始左视点深度图像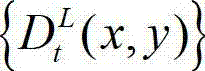 中下一个待处理的像素点作为当前像素点,然后返回步骤③-2继续执行,直至t时刻的原始左视点深度图像
中下一个待处理的像素点作为当前像素点,然后返回步骤③-2继续执行,直至t时刻的原始左视点深度图像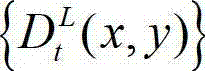 中的所有像素点处理完毕,得到t时刻的原始左视点深度图像
中的所有像素点处理完毕,得到t时刻的原始左视点深度图像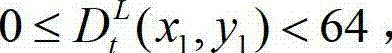 的最大可容忍失真分布图像,记为
的最大可容忍失真分布图像,记为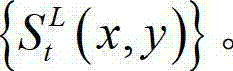
所述的深度敏感性阈值T的值由t时刻的原始左视点深度图像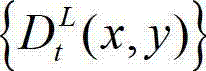 中坐标位置为(x1,y1)的像素点的深度值
中坐标位置为(x1,y1)的像素点的深度值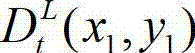 决定,如果则取T=21;如果则取T=19;如果则取T=18;如果 则取T=20。
决定,如果则取T=21;如果则取T=19;如果则取T=18;如果 则取T=20。
所述的步骤④的具体过程为:
④-1、定义t时刻的原始左视点深度图像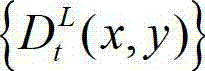 中当前正在处理的像素点为当前像素点;
中当前正在处理的像素点为当前像素点;
④-2、将当前像素点的坐标位置记为(x1,y1),将当前像素点的坐标位置(x1,y1)从二 维图像平面投影到三维场景平面,得到当前像素点的坐标位置(x1,y1)的投影坐标位置,记为(u,v,w),其中,x1∈[1,W],y1∈[1,H],(u,v,w)T为(u,v,w)的转置矩阵,R1为左视点相机的旋转矩阵,A1为左视点相机的内参矩阵,A1-1为A1的逆矩阵,(x1,y1,1)T为(x1,y1,1)的转置矩阵,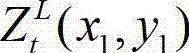 表示t时刻的原始左视点深度图像
表示t时刻的原始左视点深度图像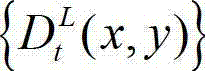 中坐标位置为(x1,y1)的像素点的场景深度,
中坐标位置为(x1,y1)的像素点的场景深度, 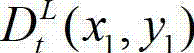 表示t时刻的原始左视点深度图像
表示t时刻的原始左视点深度图像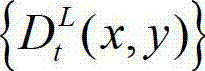 中坐标位置为(x1,y1)的像素点的深度值,Znear表示深度图像中最小的场景深度值,Zfar表示深度图像中最大的场景深度值,T1为左视点相机的平移矩阵;
中坐标位置为(x1,y1)的像素点的深度值,Znear表示深度图像中最小的场景深度值,Zfar表示深度图像中最大的场景深度值,T1为左视点相机的平移矩阵;
④-3、将当前像素点的坐标位置(x1,y1)的投影坐标位置(u,v,w)从三维场景平面投影到二维图像平面,得到当前像素点的坐标位置(x1,y1)的投影坐标位置(u,v,w)在t时刻的原始右视点深度图像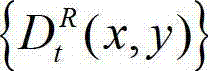 中的坐标位置,记为(x2,y2),x2=x'/z,y2=y′/z,(x',y',z)T=A2R2-1(u,v,w)T-A2R2-1T2,其中,x2∈[1,W],y2∈[1,H],(x',y',z)T为(x',y',z)的转置矩阵,A2为右视点相机的内参矩阵,R2为右视点相机的旋转矩阵,R2-1为R2的逆矩阵,t2为右视点相机的平移矩阵;
中的坐标位置,记为(x2,y2),x2=x'/z,y2=y′/z,(x',y',z)T=A2R2-1(u,v,w)T-A2R2-1T2,其中,x2∈[1,W],y2∈[1,H],(x',y',z)T为(x',y',z)的转置矩阵,A2为右视点相机的内参矩阵,R2为右视点相机的旋转矩阵,R2-1为R2的逆矩阵,t2为右视点相机的平移矩阵;
④-4、利用当前像素点的坐标位置(x1,y1)与t时刻的原始右视点深度图像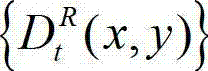 中的坐标位置(x2,y2)的映射关系,将t时刻的原始左视点深度图像
中的坐标位置(x2,y2)的映射关系,将t时刻的原始左视点深度图像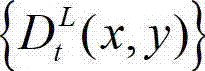 中坐标位置为(x1,y1)的像素点的深度值映射到t时刻的原始右视点深度图像
中坐标位置为(x1,y1)的像素点的深度值映射到t时刻的原始右视点深度图像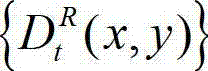 中,对应作为t时刻的原始右视点深度图像的绘制图像中坐标位置为(x2,y2)的像素点的深度值,将t时刻的原始右视点深度图像的绘制图像中坐标位置为(x2,y2)的像素点的深度值记为
中,对应作为t时刻的原始右视点深度图像的绘制图像中坐标位置为(x2,y2)的像素点的深度值,将t时刻的原始右视点深度图像的绘制图像中坐标位置为(x2,y2)的像素点的深度值记为
④-5、将t时刻的原始左视点深度图像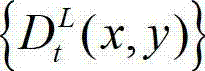 中下一个待处理的像素点作为当前 像素点,然后返回步骤④-2继续执行,直至t时刻的原始左视点深度图像
中下一个待处理的像素点作为当前 像素点,然后返回步骤④-2继续执行,直至t时刻的原始左视点深度图像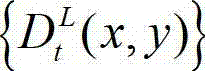 中的所有像素点处理完毕,得到t时刻的原始右视点深度图像的绘制图像,记为
中的所有像素点处理完毕,得到t时刻的原始右视点深度图像的绘制图像,记为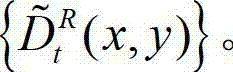
所述的步骤⑥中对t时刻的原始左视点深度图像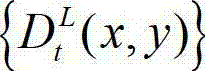 进行编码的具体过程为:
进行编码的具体过程为:
⑥-1、任取一个编码量化参数作为t时刻的原始左视点深度图像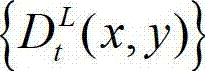 的基本编码量化参数,并记为QP1,其中,QP1的值为[22,50]区间内的一个正整数;
的基本编码量化参数,并记为QP1,其中,QP1的值为[22,50]区间内的一个正整数;
⑥-2、将t时刻的原始左视点深度图像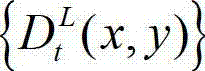 及t时刻的原始左视点深度图像
及t时刻的原始左视点深度图像 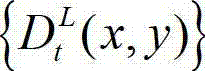 的最大可容忍失真分布图像
的最大可容忍失真分布图像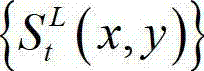 分别分割成
分别分割成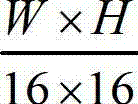 个互不重叠的尺寸大小为16×16的子块,将
个互不重叠的尺寸大小为16×16的子块,将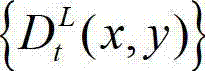 中当前正在处理的第k个子块定义为当前第一子块,记为{ftD(i',j′)},将
中当前正在处理的第k个子块定义为当前第一子块,记为{ftD(i',j′)},将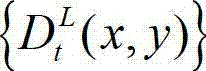 的最大可容忍失真分布图像
的最大可容忍失真分布图像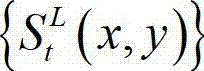 中当前正在处理的第k个子块定义为当前第二子块,记为{ftS(i',j')},其中,
中当前正在处理的第k个子块定义为当前第二子块,记为{ftS(i',j')},其中,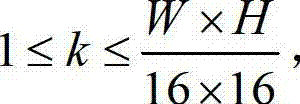 (i′,j')表示当前第一子块{ftD(i',j')}与当前第二子块{ftS(i',j')}中的像素点的坐标位置,1≤i'≤16,1≤j'≤16,ftD(i',j')表示当前第一子块{ftD(i',j')}中坐标位置为(i',j')的像素点的深度值,ftS(i',j')表示当前第二子块{ftS(i',j')}中坐标位置为(i',j')的像素点的最大可容忍失真值;
(i′,j')表示当前第一子块{ftD(i',j')}与当前第二子块{ftS(i',j')}中的像素点的坐标位置,1≤i'≤16,1≤j'≤16,ftD(i',j')表示当前第一子块{ftD(i',j')}中坐标位置为(i',j')的像素点的深度值,ftS(i',j')表示当前第二子块{ftS(i',j')}中坐标位置为(i',j')的像素点的最大可容忍失真值;
⑥-3、计算当前第二子块{ftS(i',j')}的均值和标准差,分别记为μ1和σ1,然后判断μ1>T1′且σ1<T2'是否成立,如果成立,则根据QP1并采用设定的编码预测结构,利用编码量化参数QP1+ΔQP1对当前第一子块{ftD(i',j')}进行编码,其中,ΔQP1∈[0,10],再执行步骤⑥-7,否则,执行步骤⑥-4;
⑥-4、判断μ1>T1′且σ1>T2'是否成立,如果成立,则根据QP1并采用设定的编码预测结构,利用编码量化参数QP1+ΔQP2对当前第一子块{ftD(i',j')}进行编码,ΔQP2∈[0,10],然后执行步骤⑥-7,否则,执行步骤⑥-5;
⑥-5、判断μ1<T1′且σ1<T2'是否成立,如果成立,则根据QP1并采用设定的编码 预测结构,利用编码量化参数QP1+ΔQP3对当前第一子块{ftD(i',j')}进行编码,ΔQP3∈[0,10],然后执行步骤⑥-7,否则,执行步骤⑥-6;
⑥-6、根据QP1并采用设定的编码预测结构,利用编码量化参数QP1对当前第一子块{ftD(i',j')}进行编码;
⑥-7、令k″=k+1,k=k″,将t时刻的原始左视点深度图像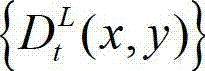 中的下一个待处理的子块作为当前第一子块,将t时刻的原始左视点深度图像
中的下一个待处理的子块作为当前第一子块,将t时刻的原始左视点深度图像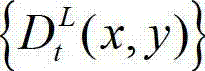 的最大可容忍失真分布图像
的最大可容忍失真分布图像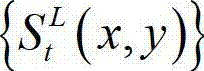 中的下一个待处理的子块作为当前第二子块,然后返回步骤⑥-3继续执行,直至t时刻的原始左视点深度图像
中的下一个待处理的子块作为当前第二子块,然后返回步骤⑥-3继续执行,直至t时刻的原始左视点深度图像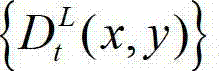 及t时刻的原始左视点深度图像
及t时刻的原始左视点深度图像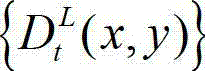 的最大可容忍失真分布图像
的最大可容忍失真分布图像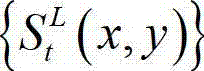 中的所有子块均处理完毕,完成t时刻的原始左视点深度图像
中的所有子块均处理完毕,完成t时刻的原始左视点深度图像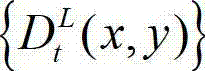 的编码,其中,k″的初始值为0,k″=k+1和k=k″中的“=”为赋值符号。
的编码,其中,k″的初始值为0,k″=k+1和k=k″中的“=”为赋值符号。
所述的步骤⑥-3至所述的步骤⑥-5中取T1'=13,取T2'=768;所述的设定的编码预测结构为HBP编码预测结构。
所述的步骤⑨的具体过程为:
⑨-1、根据解码后的t时刻右视点深度图像的绘制图像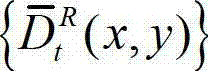 和解码后的t时刻的残差图像
和解码后的t时刻的残差图像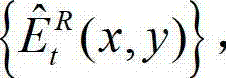 得到解码后的t时刻的右视点深度图像的初始重建图像,记为
得到解码后的t时刻的右视点深度图像的初始重建图像,记为 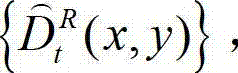 将
将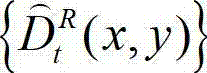 中坐标位置为(x,y)的像素点的深度值记为
中坐标位置为(x,y)的像素点的深度值记为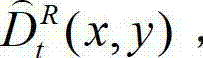
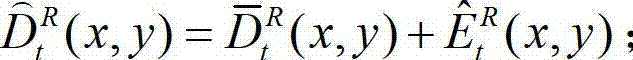
⑨-2、计算解码后的t时刻的右视点深度图像的初始重建图像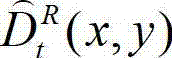 的空洞掩膜图像,记为
的空洞掩膜图像,记为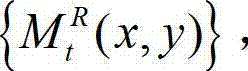 将
将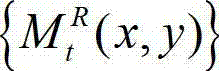 中坐标位置为(x,y)的像素点的像素值记为 如果
中坐标位置为(x,y)的像素点的像素值记为 如果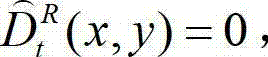 则否则
则否则
⑨-3、将解码后的t时刻的右视点深度图像的初始重建图像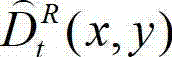 中当前正在处理的像素点定义为当前像素点;
中当前正在处理的像素点定义为当前像素点;
⑨-4、判断空洞掩膜图像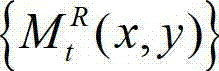 中与当前像素点的坐标位置对应的像素点的像素值是否为0,如果是,则执行步骤⑨-5,否则,执行步骤⑨-6;
中与当前像素点的坐标位置对应的像素点的像素值是否为0,如果是,则执行步骤⑨-5,否则,执行步骤⑨-6;
⑨-5、通过采用图像修复技术得到当前像素点的重建像素值,将当前像素点的重建像素值作为解码后的t时刻的右视点深度图像的重构图像中对应坐标位置的像素点的像素值;
⑨-6、将当前像素点的像素值作为解码后的t时刻的右视点深度图像的重构图像中对应坐标位置的像素点的像素值;
⑨-7、将解码后的t时刻的右视点深度图像的初始重建图像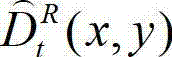 中下一个待处理的像素点作为当前像素点,然后返回步骤⑨-4继续执行,直至解码后的t时刻的右视点深度图像的初始重建图像
中下一个待处理的像素点作为当前像素点,然后返回步骤⑨-4继续执行,直至解码后的t时刻的右视点深度图像的初始重建图像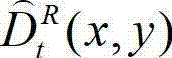 中的所有像素点均处理完毕,得到解码后的t时刻的右视点深度图像的重构图像,记为
中的所有像素点均处理完毕,得到解码后的t时刻的右视点深度图像的重构图像,记为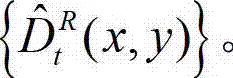
与现有技术相比,本发明的优点在于:
1)本发明方法根据人眼的视觉特性得到原始左视点深度图像的最大可容忍失真分布图像,对最大可容忍失真值较小的区域采用较小的量化步长进行编码,对最大可容忍失真值较大的区域采用较大的量化步长进行编码,这样在保证虚拟视点图像绘制性能的基础上,大大提高了深度图像的编码效率。
2)本发明方法通过基于深度图像绘制的方法,将原始左视点深度图像从左视点投影到右视点,得到原始右视点深度图像与原始右视点深度图像的绘制图像的残差图像,然后对残差图像进行编码,最后根据解码后的右视点深度图像的绘制图像和解码后的残差图像,得到解码后的右视点深度图像的重构图像,这样在保证较高的右视点深度图像的重构质量的前提下,大大提高了深度图像的编码效率。
附图说明
图1为本发明方法的流程框图;
图2a为“Alt Moabit”三维立体视频测试序列的一帧左视点彩色图像;
图2b为“Alt Moabit”三维立体视频测试序列的一帧左视点深度图像;
图3a为“BookArrival”三维立体视频测试序列的一帧左视点彩色图像;
图3b为“BookArrival”三维立体视频测试序列的另一帧左视点深度图像;
图4a为“Dog”三维立体视频测试序列的一帧左视点彩色图像;
图4b为“Dog”三维立体视频测试序列的另一帧左视点深度图像;
图5a为“Pantomime”三维立体视频测试序列的一帧左视点彩色图像;
图5b为“Pantomime”三维立体视频测试序列的另一帧左视点深度图像;
图6为“Alt Moabit”三维立体视频测试序列的原始深度图像采用本发明方法与采用原始编码方法的视点绘制率失真性能曲线比较示意图;
图7为“Book Arrival”三维立体视频测试序列的原始深度图像采用本发明方法与采用原始编码方法的视点绘制率失真性能曲线比较示意图;
图8为“Dog”三维立体视频测试序列的原始深度图像采用本发明方法与采用原始编码方法的视点绘制率失真性能曲线比较示意图;
图9为“Pantomime”三维立体视频测试序列的原始深度图像采用本发明方法与采用原始编码方法的视点绘制率失真性能曲线比较示意图。
具体实施方式
以下结合附图实施例对本发明作进一步详细描述。
本发明提出的一种深度图像编码方法,其流程框图如图1所示,其具体包括以下步骤:
①将外部立体视频捕获工具捕获得到的未经处理的且颜色空间为YUV的彩色立体视频及其对应的深度立体视频定义为原始三维立体视频,该原始三维立体视频由原始左视点彩色图像、原始右视点彩色图像、原始左视点深度图像和原始右视点深度图像组成,将t时刻的原始左视点彩色图像记为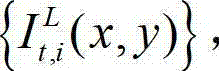 将t时刻的原始右视点彩色图像记为
将t时刻的原始右视点彩色图像记为 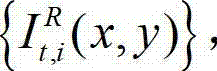 将t时刻的原始左视点深度图像记为
将t时刻的原始左视点深度图像记为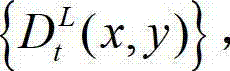 将t时刻的原始右视点深度图像记为
将t时刻的原始右视点深度图像记为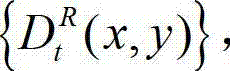 其中,i=1,2,3分别表示YUV颜色空间的三个分量,YUV颜色空间的第1个分量为亮度分量并记为Y、第2个分量为第一色度分量并记为U及第3个分量为第二色度分量并记为V,(x,y)表示彩色图像和深度图像中的像素点的坐标位置,1≤x≤W,1≤y≤H,W表示彩色图像和深度图像的宽度,H表示彩色图像和深度图像的高度,
其中,i=1,2,3分别表示YUV颜色空间的三个分量,YUV颜色空间的第1个分量为亮度分量并记为Y、第2个分量为第一色度分量并记为U及第3个分量为第二色度分量并记为V,(x,y)表示彩色图像和深度图像中的像素点的坐标位置,1≤x≤W,1≤y≤H,W表示彩色图像和深度图像的宽度,H表示彩色图像和深度图像的高度,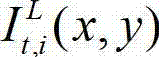 表示t时刻的原始左视点彩色图像
表示t时刻的原始左视点彩色图像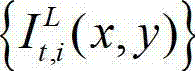 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,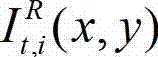 表示t时刻的原始右视点彩色图像
表示t时刻的原始右视点彩色图像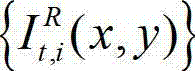 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,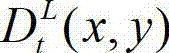 表示t时刻的原始左视点深度图像
表示t时刻的原始左视点深度图像 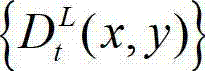 中坐标位置为(x,y)的像素点的深度值,
中坐标位置为(x,y)的像素点的深度值,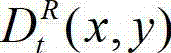 表示t时刻的原始右视点深度图像
表示t时刻的原始右视点深度图像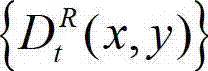 中坐标位置为(x,y)的像素点的深度值。
中坐标位置为(x,y)的像素点的深度值。
在此,截取德国HHI研究所提供的多视点视频序列“Alt Moabit”和“Book Arrival”,日本Nagoya大学提供的多视点视频序列“Dog”和“Pantomime”作为原始三维立体视频,原始三维立体视频中各幅立体图像的分辨率都为1024×768,是ISO/MPEG所推荐的标准测试序列,是在立体视频研究领域广泛采用的实验测试序列,图2a和图2b分别给出了多视点视频序列“Alt Moabit”的左视点原始视频中的一帧左视点彩色图像和一帧左视点深度图像;图3a和图3b分别给出了多视点视频序列“Book Arrival”的左视点原始视频中的一帧左视点彩色图像和一帧左视点深度图像;图4a和图4b分别给出了多视点视频序列“Dog”的左视点原始视频中的一帧左视点彩色图像和一帧左视点深度图像;图5a和图5b给出了多视点视频序列“Pantomime”的左视点原始视频中的一帧左视点彩色图像和一帧左视点深度图像。
②视觉心理学的研究结果表明,人眼视觉感知存在视觉掩蔽效应,通常以最小可察觉变化步长(Just Noticeable Difference,JND)来进行定量描述,而人眼的视觉掩蔽受背景照度、纹理复杂度等因素的影响,背景越亮,纹理越复杂,界限值就越高。因此本发明利用人类视觉对背景光照和纹理的视觉掩蔽效应,提取出t时刻的原始左视点彩色图像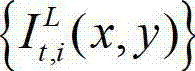 的最小可察觉变化步长图像,记为
的最小可察觉变化步长图像,记为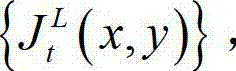 其中,
其中,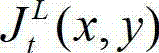 表示
表示 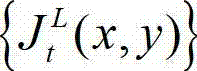 中坐标位置为(x,y)的像素点的最小可察觉变化步长值。
中坐标位置为(x,y)的像素点的最小可察觉变化步长值。
在此具体实施例中,步骤②的具体过程为:
②-1、计算t时刻的原始左视点彩色图像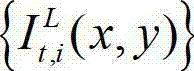 的背景光照的视觉掩蔽效应的可视化阈值集合,记为{Tl(x,y)},
的背景光照的视觉掩蔽效应的可视化阈值集合,记为{Tl(x,y)},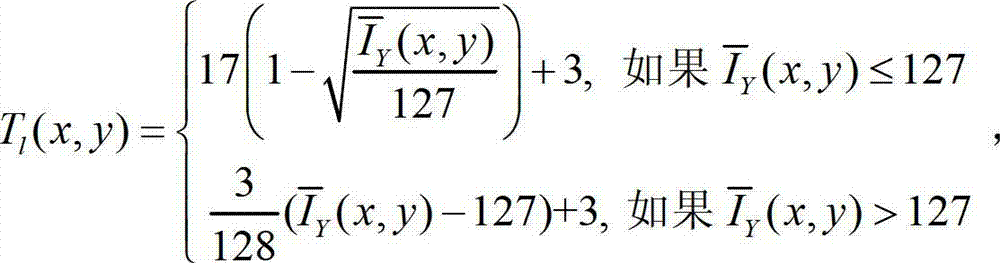 其中,Tl(x,y)表示t时刻的原始左视点彩色图像
其中,Tl(x,y)表示t时刻的原始左视点彩色图像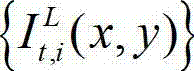 中坐标位置为(x,y)的像素点的背景光照的视觉掩蔽效应的可视化阈值,
中坐标位置为(x,y)的像素点的背景光照的视觉掩蔽效应的可视化阈值,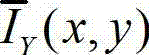 表示t时刻的原始左视点彩色图像
表示t时刻的原始左视点彩色图像 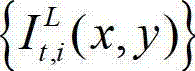 中以坐标位置为(x,y)的像素点为中心的N×N邻域窗口内的所有像素点的亮度平均值,在本实施例中取N的值为5,即N×N为5×5。
中以坐标位置为(x,y)的像素点为中心的N×N邻域窗口内的所有像素点的亮度平均值,在本实施例中取N的值为5,即N×N为5×5。
②-2、计算t时刻的原始左视点彩色图像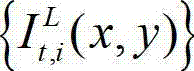 的纹理的视觉掩蔽效应的可视化阈值集合,记为{Tt(x,y)},Tt(x,y)=η×G(x,y)×We(x,y),其中,Tt(x,y)表示t时刻的原始左视点彩色图像
的纹理的视觉掩蔽效应的可视化阈值集合,记为{Tt(x,y)},Tt(x,y)=η×G(x,y)×We(x,y),其中,Tt(x,y)表示t时刻的原始左视点彩色图像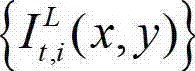 中坐标位置为(x,y)的像素点的纹理的视觉掩蔽效应的可视化阈值,η为大于0的控制因子,在本实施例中取η=0.05,G(x,y)表示对t时刻的原始左视点彩色图像
中坐标位置为(x,y)的像素点的纹理的视觉掩蔽效应的可视化阈值,η为大于0的控制因子,在本实施例中取η=0.05,G(x,y)表示对t时刻的原始左视点彩色图像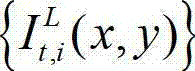 中坐标位置为(x,y)的像素点进行定向高通滤波得到的最大加权平均值,We(x,y)表示对t时刻的原始左视点彩色图像
中坐标位置为(x,y)的像素点进行定向高通滤波得到的最大加权平均值,We(x,y)表示对t时刻的原始左视点彩色图像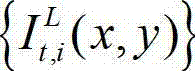 的边缘图像中坐标位置为(x,y)的像素点进行高斯低通滤波得到的边缘加权值。
的边缘图像中坐标位置为(x,y)的像素点进行高斯低通滤波得到的边缘加权值。
②-3、对t时刻的原始左视点彩色图像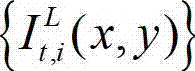 的背景光照的视觉掩蔽效应的可视化阈值集合{Tl(x,y)}和纹理的视觉掩蔽效应的可视化阈值集合{Tt(x,y)}进行融合,得到t时刻的原始左视点彩色图像
的背景光照的视觉掩蔽效应的可视化阈值集合{Tl(x,y)}和纹理的视觉掩蔽效应的可视化阈值集合{Tt(x,y)}进行融合,得到t时刻的原始左视点彩色图像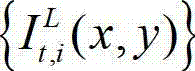 的最小可察觉变化步长图像,记为
的最小可察觉变化步长图像,记为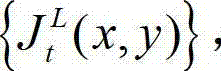 将
将 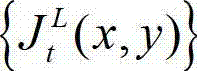 中坐标位置为(x,y)的像素点的最小可察觉变化步长值记为
中坐标位置为(x,y)的像素点的最小可察觉变化步长值记为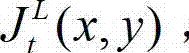 其中,Cl,t表示控制背景光照和纹理的视觉掩蔽效应重叠影响的参数,0<Cl,t<1,在本实施例中取Cl,t=0.5,min{}为取最小值函数。
其中,Cl,t表示控制背景光照和纹理的视觉掩蔽效应重叠影响的参数,0<Cl,t<1,在本实施例中取Cl,t=0.5,min{}为取最小值函数。
③由于深度图像的失真并不会对视觉感知产生影响,但会对虚拟视点绘制质量产生影响(几何位置失真),并进而影响三维视觉感知,因此需要测量深度失真与几何失真的关系。因此本发明根据t时刻的原始左视点彩色图像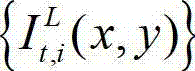 的最小可察觉变化步长图像
的最小可察觉变化步长图像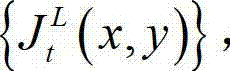 提取出t时刻的原始左视点深度图像
提取出t时刻的原始左视点深度图像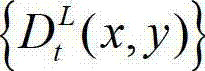 的最大可容忍失真分布图像,记为
的最大可容忍失真分布图像,记为 其中,
其中,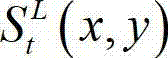 表示
表示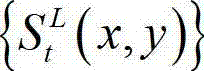 中坐标位置为(x,y)的像素点的最大可容忍失真值。
中坐标位置为(x,y)的像素点的最大可容忍失真值。
在此具体实施例中,步骤③的具体过程为:
③-1、定义t时刻的原始左视点深度图像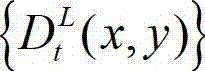 中当前正在处理的像素点为当前像素点。
中当前正在处理的像素点为当前像素点。
③-2、将当前像素点的坐标位置记为(x1,y1),将与当前像素点水平相邻的像素点的 坐标位置记为(x1+Δx,y1),计算当前像素点和与其水平相邻的像素点之间的颜色距离,记为Ψ(x1+Δx,y1),计算当前像素点和与其水平相邻的像素点之间的深度距离,记为Φ(x1+Δx,y1), 其中,x1∈[1,W],y1∈[1,H],Δx表示水平偏移量,-W'≤Δx<0或0<Δx≤W',W'表示最大水平偏移量,在本实施例中取W'=15,“||”为取绝对值符号,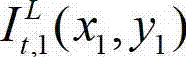 表示t时刻原始左视点彩色图像
表示t时刻原始左视点彩色图像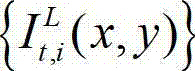 中坐标位置为(x1,y1)的像素点的Y分量的值,
中坐标位置为(x1,y1)的像素点的Y分量的值,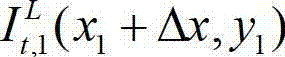 表示t时刻原始左视点彩色图像
表示t时刻原始左视点彩色图像 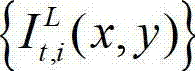 中坐标位置为(x1+Δx,y1)的像素点的Y分量的值,
中坐标位置为(x1+Δx,y1)的像素点的Y分量的值,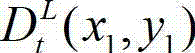 表示t时刻的原始左视点深度图像
表示t时刻的原始左视点深度图像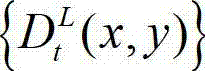 中坐标位置为(x1,y1)的像素点的深度值,
中坐标位置为(x1,y1)的像素点的深度值,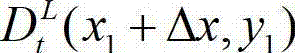 表示t时刻的原始左视点深度图像
表示t时刻的原始左视点深度图像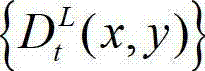 中坐标位置为(x1+Δx,y1)的像素点的深度值。
中坐标位置为(x1+Δx,y1)的像素点的深度值。
③-3、从当前像素点的左方向水平偏移量集合{ΔxL|-W'≤ΔxL≤-1}中任取一个ΔxL,如果且Φ(x1+ΔxL,y1)≤T同时成立,则认为ΔxL为当前像素点的一个左方向可容忍失真值;采用相同的方法计算当前像素点的左方向水平偏移量集合中的所有左方向可容忍失真值,再从所有左方向可容忍失真值中找出绝对值最大的左方向可容忍失真值,将绝对值最大的左方向可容忍失真值作为当前像素点的左方向最大可容忍失真值,记为ΔL(x1,y1),其中,Ψ(x1+ΔxL,y1)表示当前像素点和坐标位置为(x1+ΔxL,y1)的像素点之间的颜色距离,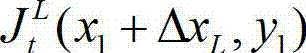 表示
表示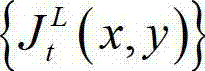 中坐标位置为(x1+ΔxL,y1)的像素点的最小可察觉变化步长值,Φ(x1+ΔxL,y1)表示当前像素点和坐标位置为(x1+ΔxL,y1)的像素点之间的深度距离,T为深度敏感性阈值。
中坐标位置为(x1+ΔxL,y1)的像素点的最小可察觉变化步长值,Φ(x1+ΔxL,y1)表示当前像素点和坐标位置为(x1+ΔxL,y1)的像素点之间的深度距离,T为深度敏感性阈值。
③-4、从当前像素点的右方向水平偏移量集合{ΔxR|1≤ΔxR≤W'}中任取一个ΔxR,如果且Φ(x1+ΔxR,y1)≤T同时成立,则认为ΔxR为当前像素点的一个右方向可容忍失真值;采用相同的方法计算当前像素点的右方向水平偏移量集合中的所有右方向可容忍失真值,再从所有右方向可容忍失真值中找出绝对值最大的右方向可容忍失真值,将绝对值最大的右方向可容忍失真值作为当前像素点的右方向最 大可容忍失真值,记为ΔR(x1,y1),其中,Ψ(x1+ΔxR,y1)表示当前像素点和坐标位置为(x1+ΔxR,y1)的像素点之间的颜色距离,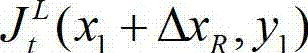 表示
表示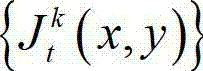 中坐标位置为(x1+ΔxR,y1)的像素点的最小可察觉变化步长值,Φ(x1+ΔxR,y1)表示当前像素点和坐标位置为(x1+ΔxR,y1)的像素点之间的深度距离。
中坐标位置为(x1+ΔxR,y1)的像素点的最小可察觉变化步长值,Φ(x1+ΔxR,y1)表示当前像素点和坐标位置为(x1+ΔxR,y1)的像素点之间的深度距离。
③-5、找出当前像素点的左方向最大可容忍失真值ΔL(x1,y1)和右方向最大可容忍失真值ΔR(x1,y1)中绝对值最小的可容忍失真值,作为当前像素点的最大可容忍失真值,记为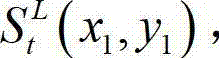 min{}为取最小值函数,“||”为取绝对值符号。
min{}为取最小值函数,“||”为取绝对值符号。
③-6、将t时刻的原始左视点深度图像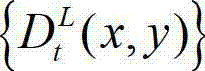 中下一个待处理的像素点作为当前像素点,然后返回步骤③-2继续执行,直至t时刻的原始左视点深度图像
中下一个待处理的像素点作为当前像素点,然后返回步骤③-2继续执行,直至t时刻的原始左视点深度图像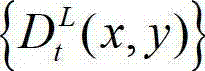 中的所有像素点处理完毕,得到t时刻的原始左视点深度图像
中的所有像素点处理完毕,得到t时刻的原始左视点深度图像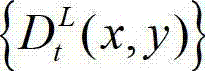 的最大可容忍失真分布图像,记为
的最大可容忍失真分布图像,记为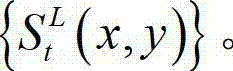
在本实施例中,深度敏感性阈值T的值由t时刻的原始左视点深度图像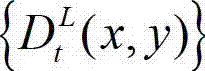 中坐标位置为(x1,y1)的像素点的深度值
中坐标位置为(x1,y1)的像素点的深度值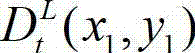 决定,如果
决定,如果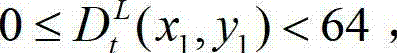 则取T=21;如果则取T=19;如果则取T=18;如果则取T=20。
则取T=21;如果则取T=19;如果则取T=18;如果则取T=20。
④由于深度是用来表征场景几何的负载信息,立体视频左右视点图像的相关性可以通过基于深度图像的绘制来反映,因此本发明采用基于深度图像绘制的方法,将t时刻的原始左视点深度图像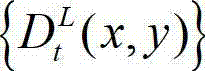 从左视点投影到右视点,得到t时刻的原始右视点深度图像的绘制图像,记为
从左视点投影到右视点,得到t时刻的原始右视点深度图像的绘制图像,记为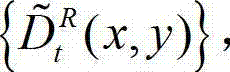 其中,
其中,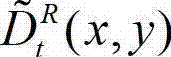 表示t时刻的原始右视点深度图像的绘制图像
表示t时刻的原始右视点深度图像的绘制图像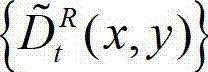 中坐标位置为(x,y)的像素点的深度值。
中坐标位置为(x,y)的像素点的深度值。
在此具体实施例中,步骤④的具体过程为:
④-1、定义t时刻的原始左视点深度图像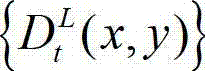 中当前正在处理的像素点为当前 像素点。
中当前正在处理的像素点为当前 像素点。
④-2、将当前像素点的坐标位置记为(x1,y1),将当前像素点的坐标位置(x1,y1)从二维图像平面投影到三维场景平面,得到当前像素点的坐标位置(x1,y1)的投影坐标位置,记为(u,v,w),其中,x1∈[1,W],y1∈[1,H],(u,v,w)T为(u,v,w)的转置矩阵,R1为左视点相机的旋转矩阵,A1为左视点相机的内参矩阵,A1-1为A1的逆矩阵,(x1,y1,1)T为(x1,y1,1)的转置矩阵,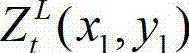 表示t时刻的原始左视点深度图像
表示t时刻的原始左视点深度图像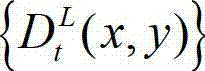 中坐标位置为(x1,y1)的像素点的场景深度,
中坐标位置为(x1,y1)的像素点的场景深度, 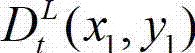 表示t时刻的原始左视点深度图像
表示t时刻的原始左视点深度图像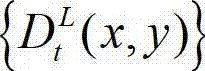 中坐标位置为(x1,y1)的像素点的深度值,Znear表示深度图像中最小的场景深度值,Zfar表示深度图像中最大的场景深度值,T1为左视点相机的平移矩阵。
中坐标位置为(x1,y1)的像素点的深度值,Znear表示深度图像中最小的场景深度值,Zfar表示深度图像中最大的场景深度值,T1为左视点相机的平移矩阵。
在本实施例中,“Alt Moabit”三维立体视频测试序列的Znear和Zfar分别为11.83775和189.404006,“Book Arrival”三维立体视频测试序列的Znear和Zfar分别为23.175928和54.077165,“Dog”三维立体视频测试序列的Znear和Zfar分别为3907.725727和8221.650623,“Pantomime”三维立体视频测试序列的Znear和Zfar分别为3907.725727和8221.650623。
④-3、将当前像素点的坐标位置(x1,y1)的投影坐标位置(u,v,w)从三维场景平面投影到二维图像平面,得到当前像素点的坐标位置(x1,y1)的投影坐标位置(u,v,w)在t时刻的原始右视点深度图像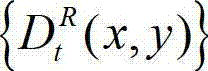 中的坐标位置,记为(x2,y2),x2=x'/z,y2=y′/z,(x',y',z)T=A2R2-1(u,v,w)T-A2R2-1T2,其中,x2∈[1,W],y2∈[1,H],(x',y',z)T为(x',y',z)的转置矩阵,A2为右视点相机的内参矩阵,R2为右视点相机的旋转矩阵,R2-1为R2的逆矩阵,T2为右视点相机的平移矩阵。
中的坐标位置,记为(x2,y2),x2=x'/z,y2=y′/z,(x',y',z)T=A2R2-1(u,v,w)T-A2R2-1T2,其中,x2∈[1,W],y2∈[1,H],(x',y',z)T为(x',y',z)的转置矩阵,A2为右视点相机的内参矩阵,R2为右视点相机的旋转矩阵,R2-1为R2的逆矩阵,T2为右视点相机的平移矩阵。
④-4、利用当前像素点的坐标位置(x1,y1)与t时刻的原始右视点深度图像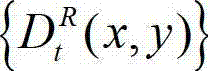 中的坐标位置(x2,y2)的映射关系,将t时刻的原始左视点深度图像
中的坐标位置(x2,y2)的映射关系,将t时刻的原始左视点深度图像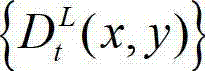 中坐标位置为(x1,y1)的像素点的深度值映射到t时刻的原始右视点深度图像
中坐标位置为(x1,y1)的像素点的深度值映射到t时刻的原始右视点深度图像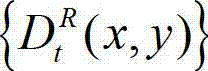 中,对应作为t时刻的原始右视点深度图像的绘制图像中坐标位置为(x2,y2)的像素点的深度值,将t时刻的原始右视点深度图像的绘制图像中坐标位置为(x2,y2)的像素点的深度值记为
中,对应作为t时刻的原始右视点深度图像的绘制图像中坐标位置为(x2,y2)的像素点的深度值,将t时刻的原始右视点深度图像的绘制图像中坐标位置为(x2,y2)的像素点的深度值记为
④-5、将t时刻的原始左视点深度图像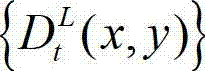 中下一个待处理的像素点作为当前像素点,然后返回步骤④-2继续执行,直至t时刻的原始左视点深度图像
中下一个待处理的像素点作为当前像素点,然后返回步骤④-2继续执行,直至t时刻的原始左视点深度图像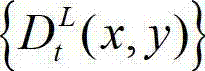 中的所有像素点处理完毕,得到t时刻的原始右视点深度图像的绘制图像,记为
中的所有像素点处理完毕,得到t时刻的原始右视点深度图像的绘制图像,记为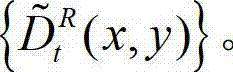
⑤由于受到空洞、遮挡及深度不一致等因素的影响,通过绘制得到的右视点彩色图像与原始右视点彩色图像之间存在一定的差异,为此本发明计算t时刻的原始右视点深度图像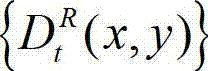 与t时刻的原始右视点深度图像的绘制图像
与t时刻的原始右视点深度图像的绘制图像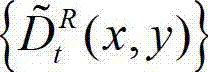 的残差图像,记为
的残差图像,记为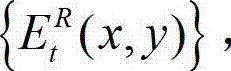 将
将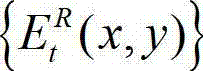 中坐标位置为(x,y)的像素点的像素值记为
中坐标位置为(x,y)的像素点的像素值记为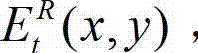
⑥根据t时刻的原始左视点深度图像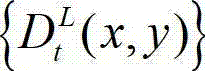 的最大可容忍失真分布图像
的最大可容忍失真分布图像 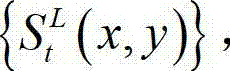 并根据设定的编码预测结构对t时刻的原始左视点深度图像
并根据设定的编码预测结构对t时刻的原始左视点深度图像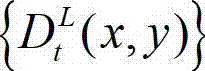 进行编码,再将编码后的t时刻的左视点深度图像经网络传输给解码端;在解码端对编码后的t时刻的左视点深度图像进行解码,获得解码后的t时刻的左视点深度图像,记为
进行编码,再将编码后的t时刻的左视点深度图像经网络传输给解码端;在解码端对编码后的t时刻的左视点深度图像进行解码,获得解码后的t时刻的左视点深度图像,记为 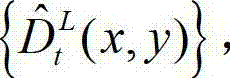 其中,
其中,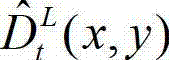 表示解码后的t时刻的左视点深度图像
表示解码后的t时刻的左视点深度图像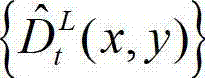 中坐标位置为(x,y)的像素点的深度值。
中坐标位置为(x,y)的像素点的深度值。
在此具体实施例中,步骤⑥中对t时刻的原始左视点深度图像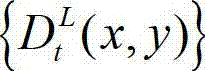 进行编码的具体过程为:
进行编码的具体过程为:
⑥-1、任取一个编码量化参数作为t时刻的原始左视点深度图像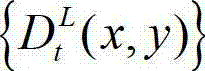 的基本编码量化参数,并记为QP1,其中,QP1的值可为[22,50]区间内的一个正整数。
的基本编码量化参数,并记为QP1,其中,QP1的值可为[22,50]区间内的一个正整数。
⑥-2、将t时刻的原始左视点深度图像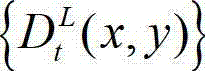 及t时刻的原始左视点深度图像
及t时刻的原始左视点深度图像 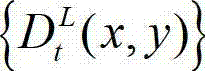 的最大可容忍失真分布图像
的最大可容忍失真分布图像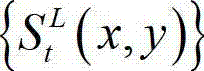 分别分割成
分别分割成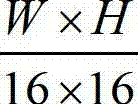 个互不重叠的尺寸大小为16×16的子块,将
个互不重叠的尺寸大小为16×16的子块,将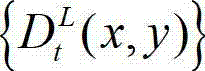 中当前正在处理的第k个子块定义为当前第一子块,记为{ftD(i',j')},将
中当前正在处理的第k个子块定义为当前第一子块,记为{ftD(i',j')},将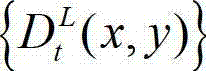 的最大可容忍失真分布图像
的最大可容忍失真分布图像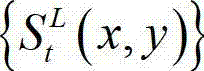 中当前正在处理的第k个子块定义为当前第二子块,记为{ftS(i',j')},其中,
中当前正在处理的第k个子块定义为当前第二子块,记为{ftS(i',j')},其中,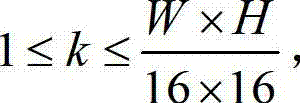 (i′,j')表示当前第一子块{ftD(i',j')}与当前第二子块{ftS(i',j')}中的像素点的坐标位置,1≤i'≤16,1≤j'≤16,ftD(i',j')表示当前第一子块{ftD(i',j')}中坐标位置为(i',j')的像素点的深度值,ftS(i',j')表示当前第二子块{ftS(i',j')}中坐标位置为(i',j')的像素点的最大可容忍失真值。
(i′,j')表示当前第一子块{ftD(i',j')}与当前第二子块{ftS(i',j')}中的像素点的坐标位置,1≤i'≤16,1≤j'≤16,ftD(i',j')表示当前第一子块{ftD(i',j')}中坐标位置为(i',j')的像素点的深度值,ftS(i',j')表示当前第二子块{ftS(i',j')}中坐标位置为(i',j')的像素点的最大可容忍失真值。
⑥-3、计算当前第二子块{ftS(i',j')}的均值和标准差,分别记为μ1和σ1,然后判断μ1>T1′且σ1<T2'是否成立,如果成立,则根据QP1并采用设定的编码预测结构,利用编码量化参数QP1+ΔQP1对当前第一子块{ftD(i',j')}进行编码,其中,ΔQP1∈[0,10],再执行步骤⑥-7,否则,执行步骤⑥-4。
⑥-4、判断μ1>T1′且σ1>T2'是否成立,如果成立,则根据QP1并采用设定的编码预测结构,利用编码量化参数QP1+ΔQP2对当前第一子块{ftD(i',j')}进行编码,ΔQP2∈[0,10],然后执行步骤⑥-7,否则,执行步骤⑥-5。
⑥-5、判断μ1<T1′且σ1<T2'是否成立,如果成立,则根据QP1并采用设定的编码预测结构,利用编码量化参数QP1+ΔQP3对当前第一子块{ftD(i',j′)}进行编码,ΔQP3∈[0,10],然后执行步骤⑥-7,否则,执行步骤⑥-6。
⑥-6、根据QP1并采用设定的编码预测结构,利用编码量化参数QP1对当前第一子块{ftD(i',j')}进行编码。
⑥-7、令k″=k+1,k=k″,将t时刻的原始左视点深度图像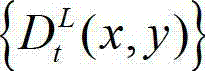 中的下一个 待处理的子块作为当前第一子块,将t时刻的原始左视点深度图像
中的下一个 待处理的子块作为当前第一子块,将t时刻的原始左视点深度图像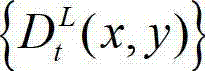 的最大可容忍失真分布图像
的最大可容忍失真分布图像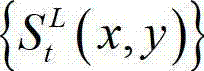 中的下一个待处理的子块作为当前第二子块,然后返回步骤⑥-3继续执行,直至t时刻的原始左视点深度图像
中的下一个待处理的子块作为当前第二子块,然后返回步骤⑥-3继续执行,直至t时刻的原始左视点深度图像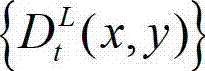 及t时刻的原始左视点深度图像
及t时刻的原始左视点深度图像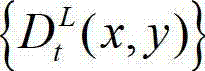 的最大可容忍失真分布图像
的最大可容忍失真分布图像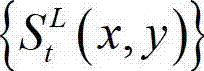 中的所有子块均处理完毕,完成t时刻的原始左视点深度图像
中的所有子块均处理完毕,完成t时刻的原始左视点深度图像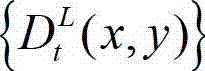 的编码,其中,k″的初始值为0,k″=k+1和k=k″中的“=”为赋值符号。
的编码,其中,k″的初始值为0,k″=k+1和k=k″中的“=”为赋值符号。
在本实施例中,设定的编码预测结构采用公知的HBP编码预测结构。
在本实施例中,取T1'=13,取T2'=768。
在本实施例中,通过统计实验对不同的三维立体视频测试序列采用相同的ΔQP1、ΔQP2和ΔQP3进行编码,ΔQP1、ΔQP2和ΔQP3分别取值为8、5和2。
⑦根据设定的编码预测结构即公知的HBP编码预测结构对t时刻的原始右视点深度图像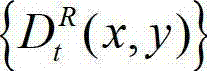 与t时刻的原始右视点深度图像的绘制图像
与t时刻的原始右视点深度图像的绘制图像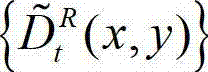 的残差图像
的残差图像 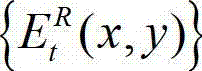 进行编码,再将编码后的t时刻的残差图像经网络传输给解码端;在解码端对编码后的t时刻的残差图像进行解码,获得解码后的t时刻的残差图像,记为
进行编码,再将编码后的t时刻的残差图像经网络传输给解码端;在解码端对编码后的t时刻的残差图像进行解码,获得解码后的t时刻的残差图像,记为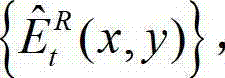 其中,
其中,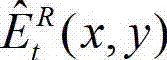 表示解码后的t时刻的残差图像
表示解码后的t时刻的残差图像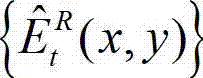 中坐标位置为(x,y)的像素点的像素值。
中坐标位置为(x,y)的像素点的像素值。
⑧采用与步骤④相同的操作,将解码后的t时刻的左视点深度图像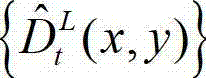 从左视点投影到右视点,得到解码后的t时刻的右视点深度图像的绘制图像,记为
从左视点投影到右视点,得到解码后的t时刻的右视点深度图像的绘制图像,记为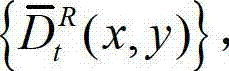 其中,
其中, 表示解码后的t时刻的右视点深度图像的绘制图像
表示解码后的t时刻的右视点深度图像的绘制图像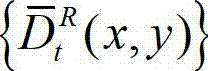 中坐标位置为(x,y)的像素点的深度值。具体过程如下:⑧-1、定义解码后的t时刻的左视点深度图像
中坐标位置为(x,y)的像素点的深度值。具体过程如下:⑧-1、定义解码后的t时刻的左视点深度图像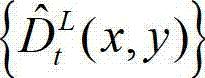 中当前正在处理的像素点为当前像素点;⑧-2、将当前像素点的坐标位置记为(x1,y1),将当前像素点的坐标位置(x1,y1)从二维图像平面投影到三维场景平面,得到当前像素点的坐标位置(x1,y1)的投影坐标位置,记为(u',v',w'), 其中,x1∈[1,W],y1∈[1,H],(u',v',w′)T为(u',v',w')的转置矩阵,R1为左视点相机的旋转矩阵,A1为左视点相机的内参矩阵,A1-1为A1的逆矩阵,(x1,y1,1)T为(x1,y1,1)的转置矩阵,
中当前正在处理的像素点为当前像素点;⑧-2、将当前像素点的坐标位置记为(x1,y1),将当前像素点的坐标位置(x1,y1)从二维图像平面投影到三维场景平面,得到当前像素点的坐标位置(x1,y1)的投影坐标位置,记为(u',v',w'), 其中,x1∈[1,W],y1∈[1,H],(u',v',w′)T为(u',v',w')的转置矩阵,R1为左视点相机的旋转矩阵,A1为左视点相机的内参矩阵,A1-1为A1的逆矩阵,(x1,y1,1)T为(x1,y1,1)的转置矩阵,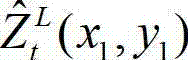 表示解码后的t时刻的左视点深度图像
表示解码后的t时刻的左视点深度图像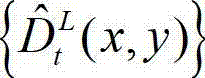 中坐标位置为(x1,y1)的像素点的场景深度,
中坐标位置为(x1,y1)的像素点的场景深度, 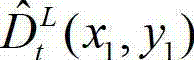 表示解码后的t时刻的左视点深度图像
表示解码后的t时刻的左视点深度图像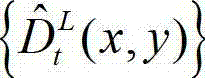 中坐标位置为(x1,y1)的像素点的深度值,Znear表示深度图像中最小的场景深度值,Zfar表示深度图像中最大的场景深度值,T1为左视点相机的平移矩阵;⑧-3、将当前像素点的坐标位置(x1,y1)的投影坐标位置(u',v',w')从三维场景平面投影到二维图像平面,得到当前像素点的坐标位置(x1,y1)的投影坐标位置(u',v',w′)在解码后的t时刻的右视点深度图像中的坐标位置,记为(x2',y2′),x2'=x'″/z',y2'=y'″/z',(x″,y″,z')T=A2R2-1(u',v',w')T-A2R2-1T2,其中,x2'∈[1,W],y2'∈[1,H],(x″,y″,z′)T为(x″,y″,z')的转置矩阵,A2为右视点相机的内参矩阵,R2为右视点相机的旋转矩阵,R2-1为R2的逆矩阵,T1为右视点相机的平移矩阵;⑧-4、利用当前像素点的坐标位置(x1,y1)与解码后的t时刻的右视点深度图像中的坐标位置(x2',y2')的映射关系,将解码后的t时刻的左视点深度图像
中坐标位置为(x1,y1)的像素点的深度值,Znear表示深度图像中最小的场景深度值,Zfar表示深度图像中最大的场景深度值,T1为左视点相机的平移矩阵;⑧-3、将当前像素点的坐标位置(x1,y1)的投影坐标位置(u',v',w')从三维场景平面投影到二维图像平面,得到当前像素点的坐标位置(x1,y1)的投影坐标位置(u',v',w′)在解码后的t时刻的右视点深度图像中的坐标位置,记为(x2',y2′),x2'=x'″/z',y2'=y'″/z',(x″,y″,z')T=A2R2-1(u',v',w')T-A2R2-1T2,其中,x2'∈[1,W],y2'∈[1,H],(x″,y″,z′)T为(x″,y″,z')的转置矩阵,A2为右视点相机的内参矩阵,R2为右视点相机的旋转矩阵,R2-1为R2的逆矩阵,T1为右视点相机的平移矩阵;⑧-4、利用当前像素点的坐标位置(x1,y1)与解码后的t时刻的右视点深度图像中的坐标位置(x2',y2')的映射关系,将解码后的t时刻的左视点深度图像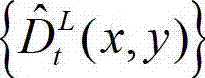 中坐标位置为(x1,y1)的像素点的深度值映射到解码后的t时刻的右视点深度图像中,对应作为解码后的t时刻的右视点深度图像的绘制图像中坐标位置为(x2',y2')的像素点的深度值,将解码后的t时刻的右视点深度图像的绘制图像中坐标位置为(x2',y2')的像素点的深度值记为
中坐标位置为(x1,y1)的像素点的深度值映射到解码后的t时刻的右视点深度图像中,对应作为解码后的t时刻的右视点深度图像的绘制图像中坐标位置为(x2',y2')的像素点的深度值,将解码后的t时刻的右视点深度图像的绘制图像中坐标位置为(x2',y2')的像素点的深度值记为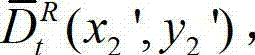
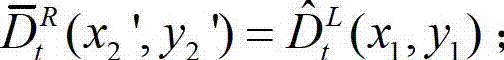 ⑧-5、将解码后的t时刻的左视点深度图像
⑧-5、将解码后的t时刻的左视点深度图像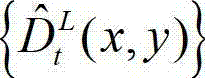 中下一个待处理的像素点作为当前像素点,然后返回步骤⑧-2继续执行,直至解码后的t时刻的左视点深度图像
中下一个待处理的像素点作为当前像素点,然后返回步骤⑧-2继续执行,直至解码后的t时刻的左视点深度图像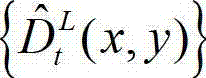 中的所有像素点处理完毕,得到解码后的t时刻的右视点深度图像的绘制图像,记为
中的所有像素点处理完毕,得到解码后的t时刻的右视点深度图像的绘制图像,记为
⑨根据解码后的t时刻的右视点深度图像的绘制图像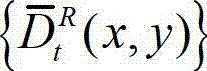 和解码后的t时刻的残差图像
和解码后的t时刻的残差图像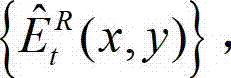 得到解码后的t时刻的右视点深度图像的重构图像,记为
得到解码后的t时刻的右视点深度图像的重构图像,记为 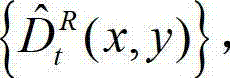 其中,
其中,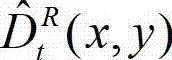 表示解码后的t时刻的右视点深度图像的重构图像
表示解码后的t时刻的右视点深度图像的重构图像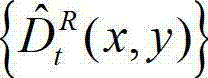 中坐标位置为(x,y)的像素点的深度值。
中坐标位置为(x,y)的像素点的深度值。
在此具体实施例中,步骤⑨的具体过程为:
⑨-1、根据解码后的t时刻右视点深度图像的绘制图像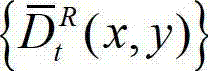 和解码后的t时刻的残差图像
和解码后的t时刻的残差图像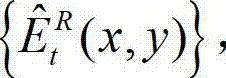 得到解码后的t时刻的右视点深度图像的初始重建图像,记为
得到解码后的t时刻的右视点深度图像的初始重建图像,记为 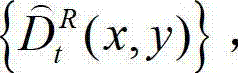 将
将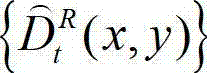 中坐标位置为(x,y)的像素点的深度值记为
中坐标位置为(x,y)的像素点的深度值记为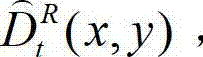
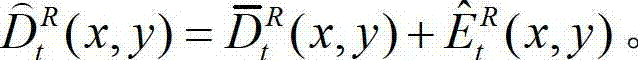
⑨-2、计算解码后的t时刻的右视点深度图像的初始重建图像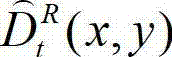 的空洞掩膜图像,记为
的空洞掩膜图像,记为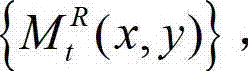 将
将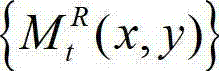 中坐标位置为(x,y)的像素点的像素值记为 如果
中坐标位置为(x,y)的像素点的像素值记为 如果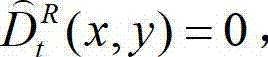 则否则
则否则
⑨-3、将解码后的t时刻的右视点深度图像的初始重建图像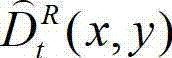 中当前正在处理的像素点定义为当前像素点。
中当前正在处理的像素点定义为当前像素点。
⑨-4、判断空洞掩膜图像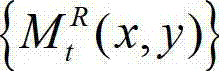 中与当前像素点的坐标位置对应的像素点的像素值是否为0,如果是,则执行步骤⑨-5,否则,执行步骤⑨-6。
中与当前像素点的坐标位置对应的像素点的像素值是否为0,如果是,则执行步骤⑨-5,否则,执行步骤⑨-6。
⑨-5、通过采用图像修复技术得到当前像素点的重建像素值,将当前像素点的重建像素值作为解码后的t时刻的右视点深度图像的重构图像中对应坐标位置的像素点的像素值。
⑨-6、将当前像素点的像素值作为解码后的t时刻的右视点深度图像的重构图像中对应坐标位置的像素点的像素值。
⑨-7、将解码后的t时刻的右视点深度图像的初始重建图像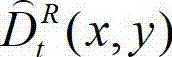 中下一个待处理的像素点作为当前像素点,然后返回步骤⑨-4继续执行,直至解码后的t时刻的右视点深度图像的初始重建图像
中下一个待处理的像素点作为当前像素点,然后返回步骤⑨-4继续执行,直至解码后的t时刻的右视点深度图像的初始重建图像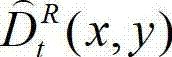 中的所有像素点均处理完毕,得到解码后的t时刻 的右视点深度图像的重构图像,记为
中的所有像素点均处理完毕,得到解码后的t时刻 的右视点深度图像的重构图像,记为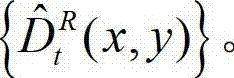
以下就利用本发明方法对“Alt Moabit”、“Book Arrival”、“Dog”和“Pantomime”三维立体视频测试序列进行立体视频编码的编码性能进行比较。
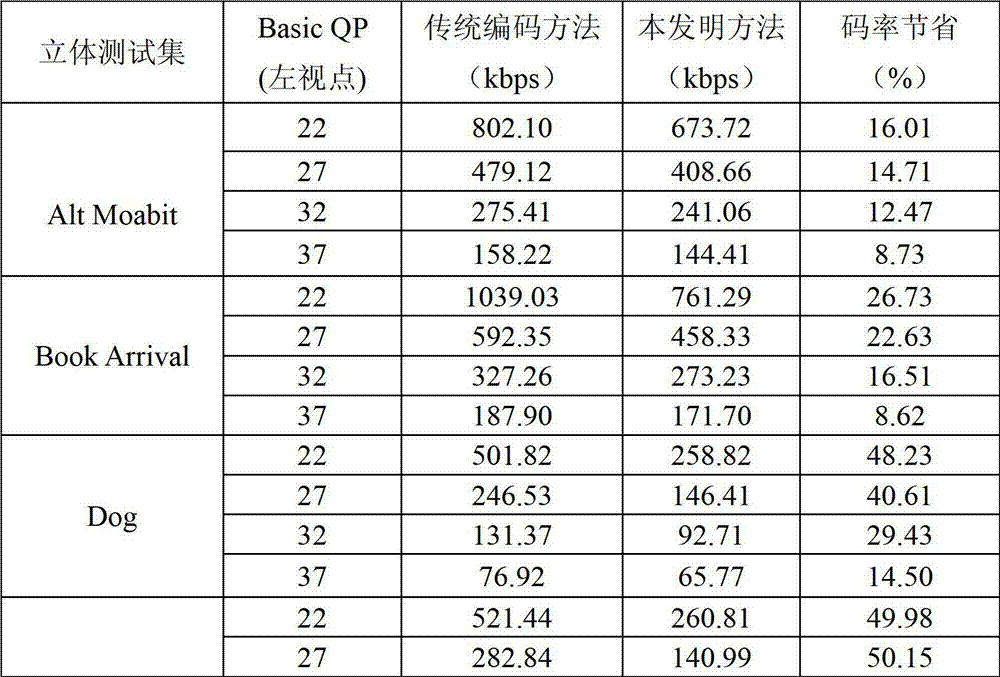
由于本发明方法只考虑深度图像的编码失真对绘制图像的影响,因此此处只对深度图像的编码性能进行比较。表1给出了利用本发明方法与传统编码方法的深度图像的编码性能比较,从表1中所列的数据可以看出,对于“Alt Moabit”、“Book Arrival”、“Dog”和“Pantomime”采用本发明方法处理后,深度图像的最低的码率节省也能达到8.73%左右,最高的码率节省能达到50.15%左右,足以说明本发明方法是有效可行的。
将采用本发明方法的视点绘制性能与采用原始编码方法的视点绘制性能进行比较,图6给出了“Alt Moabit”三维立体视频测试序列的原始深度图像采用本发明方法与原始编码方法的视点绘制率失真性能曲线比较示意图,图7给出了“BookArrival”三维立体视频测试序列的原始深度图像采用本发明方法与原始编码方法的视点绘制率失真性能曲线比较示意图,图8给出了“Dog”三维立体视频测试序列的原始深度图像采用本发明方法与原始编码方法的视点绘制率失真性能曲线比较示意图,图9给出了“Pantomime”三维立体视频测试序列的原始深度图像采用本发明方法与原始编码方法的视点绘制率失真性能曲线比较示意图,从图6至图9中可以看出,采用本发明方法处理后,大大提高了虚拟视点绘制的性能,足以说明本发明方法是有效可行的。
表1利用本发明方法与传统编码方法的深度图像的编码性能比较
 。
。

 手机二维码
手机二维码 京公网安备11011302007134
京公网安备11011302007134