技术领域
本发明涉及一种三维视频技术,尤其是涉及一种虚拟视点彩色图像绘制方法。
背景技术
三维视频(Three-Dimensional Video,3DV)是一种先进的视觉模式,它使人们在屏幕上观看图像时富有立体感和沉浸感,可以满足人们从不同角度观看三维(3D)场景的需求。通常,三维视频系统如图1所示,主要包括视频捕获、视频编码、传输解码、虚拟视点绘制和交互显示等模块。
多视点视频加深度(multi-view video plus depth,MVD)是目前ISO/MPEG推荐采用的3D场景信息表示方式。MVD数据在多视点彩色图像基础上增加了对应视点的深度信息,深度信息的获取目前主要有两种基本途径:1)通过深度相机获取;2)通过算法从普通的二维(2D)视频中生成深度信息。基于深度图像的绘制(Depth Image BasedRendering,DIBR)是一种利用参考视点的彩色图像所对应的深度图像绘制生成虚拟视点图像的方法,其通过利用参考视点的彩色图像及该参考视点的彩色图像中的每个像素对应的深度信息来合成三维场景的虚拟视点图像。由于DIBR将场景的深度信息引入到虚拟视点图像绘制中,从而大大减少了虚拟视点图像绘制所需的参考视点的数目。
目前的DIBR方法着重于对算法进行优化(如:如何精确地填充空洞像素点,如何降低三维图像变换的时间等)来提升绘制的精度和速度,但对于载体图像(彩色图像和深度图像)对绘制质量的影响却缺乏相关的研究。通过对彩色图像和深度图像的特征分析,一方面,由于深度是用来表征场景几何的负载信息,深度信息的质量会对后期虚拟视点绘制产生影响,由于深度图像的编码失真,绘制的虚拟视点图像与真实图像之间会存在几何失真(也称为结构位置失真),会在绘制的虚拟视点图像中产生新的空洞,并且深度图像的编码失真与几何失真不是简单的线性映射关系;另一方面,由于多视点成像会导致采集的多视点彩色图像的颜色不一致,使得DIBR方法图像融合过程中会出现颜色失真现象,严重影响绘制图像的主观质量。因此,如何消除深度图像的编码失真和彩色图像的颜色不一致对绘制的影响,是目前虚拟视点图像需要解决的问题。
发明内容
本发明所要解决的技术问题是提供一种能够有效地提高虚拟视点彩色图像质量的绘制方法。
本发明解决上述技术问题所采用的技术方案为:一种虚拟视点彩色图像绘制方法,其包括以下步骤:
①获取t时刻的K个参考视点的K幅颜色空间为YUV的彩色图像及其对应的K幅深度图像,然后在编码端根据设定的编码预测结构分别对t时刻的K个参考视点的K幅颜色空间为YUV的彩色图像及其对应的K幅深度图像进行编码,再将编码后的K幅彩色图像及其对应的K幅深度图像经网络传输给解码端;在解码端对编码后的K幅彩色图像及其对应的K幅深度图像进行解码,获得解码后的t时刻的K个参考视点的K幅彩色图像及其对应的K幅深度图像;
②将t时刻的第k个参考视点的彩色图像记为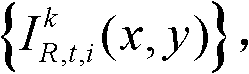 将t时刻的第k个参考视点的深度图像记为
将t时刻的第k个参考视点的深度图像记为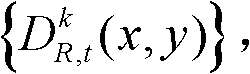 其中,i=1,2,3分别表示YUV颜色空间的三个分量,YUV颜色空间的第1个分量为亮度分量并记为Y、第2个分量为第一色度分量并记为U及第3个分量为第二色度分量并记为V,(x,y)表示彩色图像或深度图像中像素点的坐标位置,1≤k≤K,k的初始值为1,
其中,i=1,2,3分别表示YUV颜色空间的三个分量,YUV颜色空间的第1个分量为亮度分量并记为Y、第2个分量为第一色度分量并记为U及第3个分量为第二色度分量并记为V,(x,y)表示彩色图像或深度图像中像素点的坐标位置,1≤k≤K,k的初始值为1,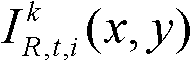 表示t时刻的第k个参考视点的彩色图像
表示t时刻的第k个参考视点的彩色图像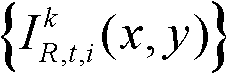 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,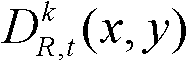 表示t时刻的第k个参考视点的深度图像
表示t时刻的第k个参考视点的深度图像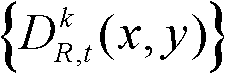 中坐标位置为(x,y)的像素点的深度值;
中坐标位置为(x,y)的像素点的深度值;
③将t时刻的第k个参考视点的深度图像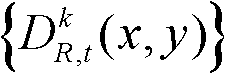 从二维图像平面投影到三维场景平面,得到t时刻的第k个参考视点的深度图像
从二维图像平面投影到三维场景平面,得到t时刻的第k个参考视点的深度图像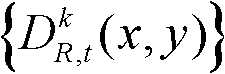 对应的场景深度集合,记为
对应的场景深度集合,记为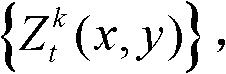
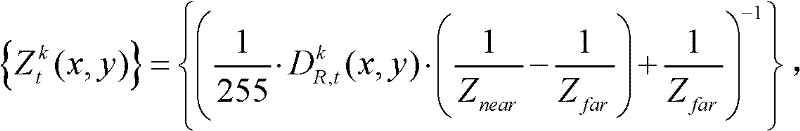 其中,
其中,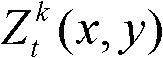 表示t时刻的第k个参考视点的深度图像
表示t时刻的第k个参考视点的深度图像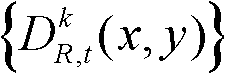 对应的场景深度集合
对应的场景深度集合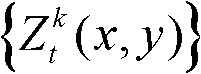 中坐标位置为(x,y)的像素点的场景深度值,Znear表示最小的场景深度值,Zfar表示最大的场景深度值;
中坐标位置为(x,y)的像素点的场景深度值,Znear表示最小的场景深度值,Zfar表示最大的场景深度值;
④采用边缘检测算法对t时刻的第k个参考视点的深度图像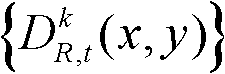 进行边缘检测,获得边缘分割图像,记为
进行边缘检测,获得边缘分割图像,记为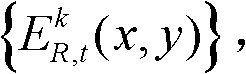 其中,边缘分割图像
其中,边缘分割图像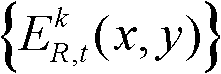 包括边缘区域;对t时刻的第k个参考视点的深度图像
包括边缘区域;对t时刻的第k个参考视点的深度图像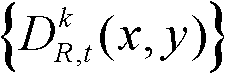 进行前景和背景的分离处理,得到前背景分离图像,记为
进行前景和背景的分离处理,得到前背景分离图像,记为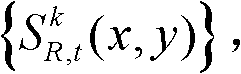 其中,前背景分离图像
其中,前背景分离图像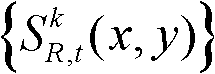 包括前景区域和背景区域;
包括前景区域和背景区域;
⑤根据边缘分割图像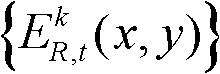 和前背景分离图像
和前背景分离图像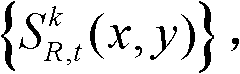 将t时刻的第k个参考视点的深度图像
将t时刻的第k个参考视点的深度图像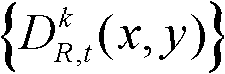 分割成核心内容区域和非核心内容区域;
分割成核心内容区域和非核心内容区域;
⑥利用两组不同滤波强度的双向滤波器分别对场景深度集合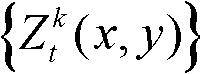 中与t时刻的第k个参考视点的深度图像
中与t时刻的第k个参考视点的深度图像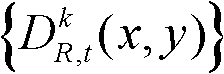 的核心内容区域和非核心内容区域中的各个像素点对应的场景深度值进行滤波处理,得到滤波后的场景深度集合,记为
的核心内容区域和非核心内容区域中的各个像素点对应的场景深度值进行滤波处理,得到滤波后的场景深度集合,记为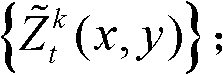
⑦将滤波后的场景深度集合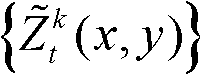 从三维场景平面重新投影到二维图像平面,得到t时刻的第k个参考视点的深度滤波图像,记为
从三维场景平面重新投影到二维图像平面,得到t时刻的第k个参考视点的深度滤波图像,记为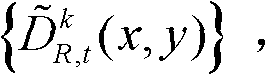
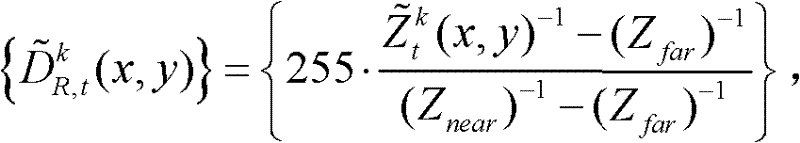 其中,
其中,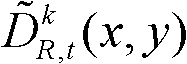 表示t时刻的第k个参考视点的深度滤波图像
表示t时刻的第k个参考视点的深度滤波图像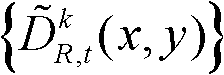 中坐标位置为(x,y)的像素点的深度值,
中坐标位置为(x,y)的像素点的深度值,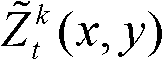 表示滤波后的场景深度集合
表示滤波后的场景深度集合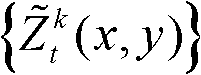 中坐标位置为(x,y)的像素点的场景深度值,Znear表示最小的场景深度值,Zfar表示最大的场景深度值;
中坐标位置为(x,y)的像素点的场景深度值,Znear表示最小的场景深度值,Zfar表示最大的场景深度值;
⑧令k′=k+1,k=k′,重复执行步骤②至⑧直至得到t时刻的K个参考视点的K幅深度滤波图像,K幅深度滤波图像用集合表示为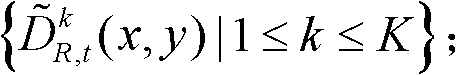
⑨假定当前需绘制的是第k′个虚拟视点,从t时刻的K个参考视点中选择两个与第k′个虚拟视点最相邻的参考视点,假定这两个参考视点分别为第k个参考视点和第k+1个参考视点,将由第k个参考视点绘制得到的第k′个虚拟视点的虚拟视点图像记为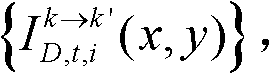 将由第k+1个参考视点绘制得到的第k′个虚拟视点的虚拟视点图像记为
将由第k+1个参考视点绘制得到的第k′个虚拟视点的虚拟视点图像记为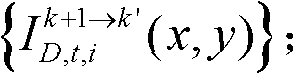 首先利用t时刻的第k个参考视点的深度图像
首先利用t时刻的第k个参考视点的深度图像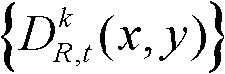 所提供的深度信息,然后采用三维图像变换方法逐像素点计算t时刻的第k个参考视点的彩色图像
所提供的深度信息,然后采用三维图像变换方法逐像素点计算t时刻的第k个参考视点的彩色图像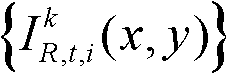 中的各个像素点在当前需绘制的第k′个虚拟视点的虚拟视点图像
中的各个像素点在当前需绘制的第k′个虚拟视点的虚拟视点图像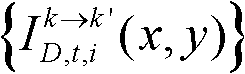 中的坐标位置,得到t时刻的第k个参考视点的彩色图像
中的坐标位置,得到t时刻的第k个参考视点的彩色图像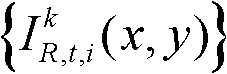 中的各个像素点映射到当前需绘制的第k′个虚拟视点的虚拟视点图像
中的各个像素点映射到当前需绘制的第k′个虚拟视点的虚拟视点图像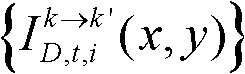 的坐标映射关系,再利用该坐标映射关系将t时刻的第k个参考视点的彩色图像
的坐标映射关系,再利用该坐标映射关系将t时刻的第k个参考视点的彩色图像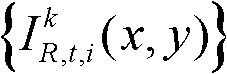 中的各个像素点映射到当前需绘制的第k′个虚拟视点的虚拟视点图像
中的各个像素点映射到当前需绘制的第k′个虚拟视点的虚拟视点图像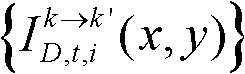 中;
中;
采用与由第k个参考视点绘制得到的虚拟视点图像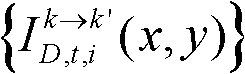 相同的方法,将第k+1个参考视点的彩色图像
相同的方法,将第k+1个参考视点的彩色图像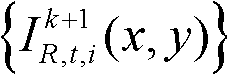 中的各个像素点映射到需绘制的第k′个虚拟视点的虚拟视点图像
中的各个像素点映射到需绘制的第k′个虚拟视点的虚拟视点图像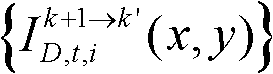 中;
中;
⑩分别对由第k个参考视点绘制得到的虚拟视点图像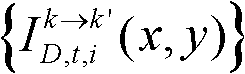 和由第k+1个参考视点绘制得到的虚拟视点图像
和由第k+1个参考视点绘制得到的虚拟视点图像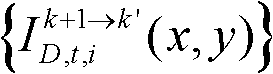 进行颜色传递操作,得到颜色校正后的由第k个参考视点绘制得到的虚拟视点图像和由第k+1个参考视点绘制得到的虚拟视点图像,分别记为
进行颜色传递操作,得到颜色校正后的由第k个参考视点绘制得到的虚拟视点图像和由第k+1个参考视点绘制得到的虚拟视点图像,分别记为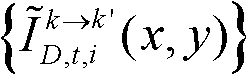 和
和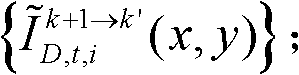
 采用图像融合方法融合颜色校正后的由第k个参考视点绘制得到的虚拟视点图像
采用图像融合方法融合颜色校正后的由第k个参考视点绘制得到的虚拟视点图像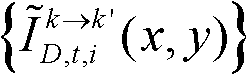 和颜色校正后的由第k+1个参考视点绘制得到的虚拟视点图像
和颜色校正后的由第k+1个参考视点绘制得到的虚拟视点图像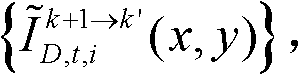 得到融合后的虚拟视点图像,记为
得到融合后的虚拟视点图像,记为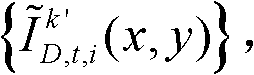 并对融合后的虚拟视点图像
并对融合后的虚拟视点图像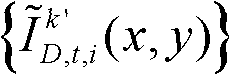 中的空洞像素点进行填补,得到最终的虚拟视点图像,记为{ID,t,i(x,y)};
中的空洞像素点进行填补,得到最终的虚拟视点图像,记为{ID,t,i(x,y)}; 重复执行步骤⑨至
重复执行步骤⑨至 直至得到K个虚拟视点的K幅虚拟视点图像。
直至得到K个虚拟视点的K幅虚拟视点图像。
所述的步骤①中设定的编码预测结构为HBP编码预测结构。
所述的步骤④中对t时刻的第k个参考视点的深度图像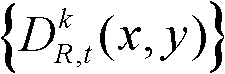 进行前景和背景的分离处理的具体过程为:
进行前景和背景的分离处理的具体过程为:
④-1、采用k-mean算法对t时刻的第k个参考视点的深度图像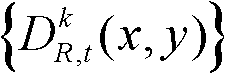 进行聚类操作,得到初始的聚类中心;
进行聚类操作,得到初始的聚类中心;
④-2、根据初始的聚类中心,采用期望最大算法估计t时刻的第k个参考视点的深度图像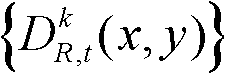 的高斯混合模型,记为Θ,
的高斯混合模型,记为Θ,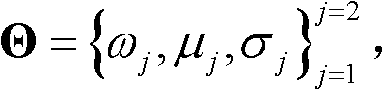 其中,j表示高斯混合模型Θ中的第j个高斯分量,j=1代表前景,j=2代表背景,ωj表示第j个高斯分量的加权系数,μj表示第j个高斯分量的均值,σj表示第j个高斯分量的标准差;
其中,j表示高斯混合模型Θ中的第j个高斯分量,j=1代表前景,j=2代表背景,ωj表示第j个高斯分量的加权系数,μj表示第j个高斯分量的均值,σj表示第j个高斯分量的标准差;
④-3、采用最大化概率密度函数分别获取t时刻的第k个参考视点的深度图像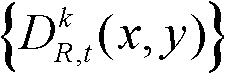 中的各个像素点属于高斯混合模型Θ中的第j个高斯分量的分类标记,记为γ(x,y),
中的各个像素点属于高斯混合模型Θ中的第j个高斯分量的分类标记,记为γ(x,y),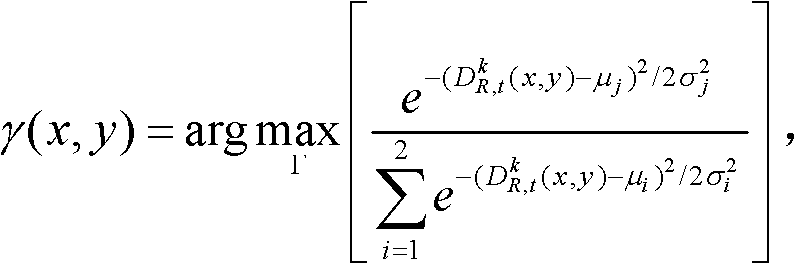 其中,1≤j≤2,γ(x,y)∈[1,2],Γ表示高斯混合模型Θ中的所有高斯分量的集合,Γ={j|1≤j≤2},
其中,1≤j≤2,γ(x,y)∈[1,2],Γ表示高斯混合模型Θ中的所有高斯分量的集合,Γ={j|1≤j≤2},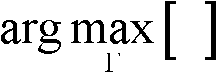 表示最大化概率密度函数,μi表示第i个高斯分量的均值,σi表示第i个高斯分量的标准差;
表示最大化概率密度函数,μi表示第i个高斯分量的均值,σi表示第i个高斯分量的标准差;
④-4、将t时刻的第k个参考视点的深度图像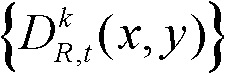 中分类标记的值为1的所有像素点构成的区域作为t时刻的第k个参考视点的深度图像
中分类标记的值为1的所有像素点构成的区域作为t时刻的第k个参考视点的深度图像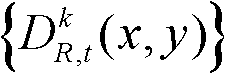 的前景区域,将t时刻的第k个参考视点的深度图像
的前景区域,将t时刻的第k个参考视点的深度图像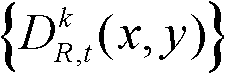 中分类标记的值为2的所有像素点构成的区域作为t时刻的第k个参考视点的深度图像
中分类标记的值为2的所有像素点构成的区域作为t时刻的第k个参考视点的深度图像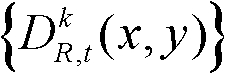 的背景区域,得到前背景分离图像
的背景区域,得到前背景分离图像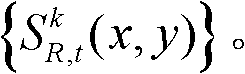
所述的步骤⑤中核心内容区域和非核心内容区域的分割过程为:
⑤-1、定义t时刻的第k个参考视点的深度图像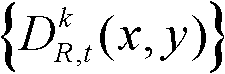 中当前正在处理的像素点为当前像素点;
中当前正在处理的像素点为当前像素点;
⑤-2、判断当前像素点是否属于前背景分离图像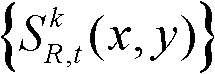 的前景区域或边缘分割图像
的前景区域或边缘分割图像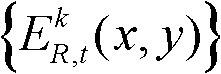 的边缘区域,如果是,则确定当前像素点为核心内容,否则,确定当前像素点为非核心内容;
的边缘区域,如果是,则确定当前像素点为核心内容,否则,确定当前像素点为非核心内容;
⑤-3、将t时刻的第k个参考视点的深度图像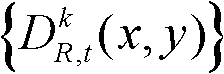 中下一个待处理的像素点作为当前像素点,然后执行步骤⑤-2和⑤-3,直至t时刻的第k个参考视点的深度图像
中下一个待处理的像素点作为当前像素点,然后执行步骤⑤-2和⑤-3,直至t时刻的第k个参考视点的深度图像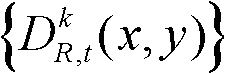 中所有像素点处理完毕,将所有核心内容构成的区域作为核心内容区域,将所有非核心内容构成的区域作为非核心内容区域。
中所有像素点处理完毕,将所有核心内容构成的区域作为核心内容区域,将所有非核心内容构成的区域作为非核心内容区域。
所述的步骤⑥的具体过程为:
⑥-1、定义t时刻的第k个参考视点的深度图像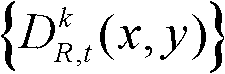 中当前正在处理的像素点为当前像素点,将当前像素点的坐标位置记为p,将当前像素点的邻域像素点的坐标位置记为q,定义双向滤波器为
中当前正在处理的像素点为当前像素点,将当前像素点的坐标位置记为p,将当前像素点的邻域像素点的坐标位置记为q,定义双向滤波器为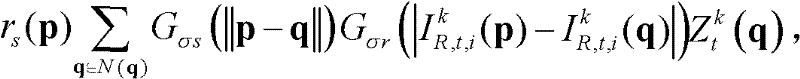 其中,
其中,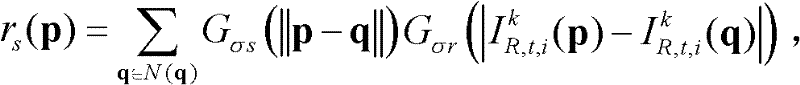 Gσs(||p-q||)表示标准差为σs的高斯函数,
Gσs(||p-q||)表示标准差为σs的高斯函数,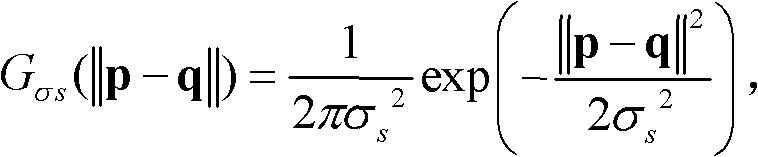
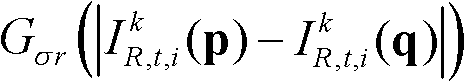 表示标准差为σr的高斯函数,
表示标准差为σr的高斯函数,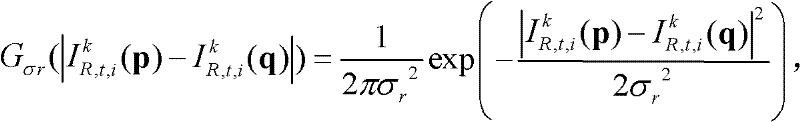 ||p-q||表示坐标位置p和坐标位置q之间的欧拉距离,
||p-q||表示坐标位置p和坐标位置q之间的欧拉距离,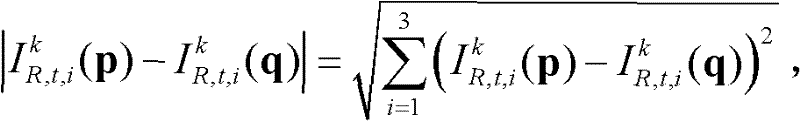
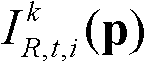 表示t时刻的第k个参考视点的彩色图像
表示t时刻的第k个参考视点的彩色图像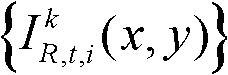 中坐标位置为p的像素点的第i个分量的值,
中坐标位置为p的像素点的第i个分量的值,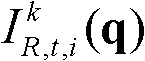 表示t时刻的第k个参考视点的彩色图像
表示t时刻的第k个参考视点的彩色图像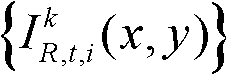 中坐标位置为q的像素点的第i个分量的值,
中坐标位置为q的像素点的第i个分量的值,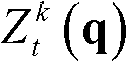 表示场景深度集合
表示场景深度集合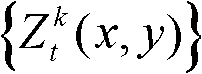 中坐标位置为q的像素点的场景深度值,N(q)表示以坐标位置为q的像素点为中心的3×3邻域窗口;
中坐标位置为q的像素点的场景深度值,N(q)表示以坐标位置为q的像素点为中心的3×3邻域窗口;
⑥-2、判断当前像素点是否属于t时刻的第k个参考视点的深度图像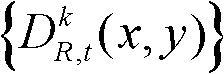 的核心内容区域,如果是,则执行步骤⑥-3,否则,执行步骤⑥-4;
的核心内容区域,如果是,则执行步骤⑥-3,否则,执行步骤⑥-4;
⑥-3、采用标准差为(σs1,σr1)的双向滤波器对当前像素点的坐标位置为q的邻域像素点的场景深度值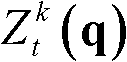 进行滤波操作,得到当前像素点滤波后的场景深度值
进行滤波操作,得到当前像素点滤波后的场景深度值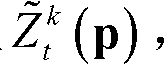
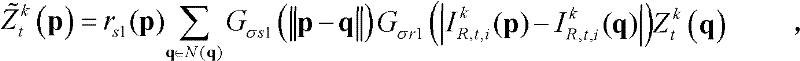 其中,
其中,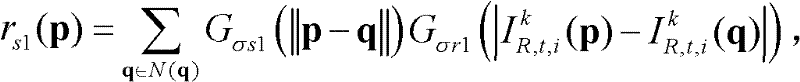 Gσs1(||p-q||)表示标准差为σs1的高斯函数,
Gσs1(||p-q||)表示标准差为σs1的高斯函数,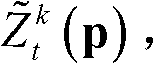 表示标准差为σr1的高斯函数,
表示标准差为σr1的高斯函数,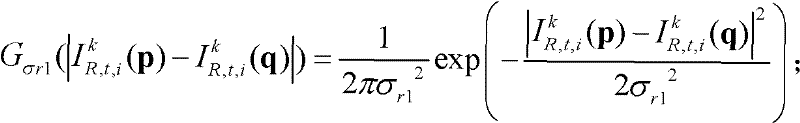
⑥-4、采用标准差为(σs2,σr2)的双向滤波器对当前像素点的坐标位置为q的邻域像素点的场景深度值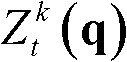 进行滤波操作,得到当前像素点滤波后的场景深度值
进行滤波操作,得到当前像素点滤波后的场景深度值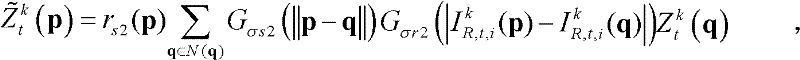 其中,
其中,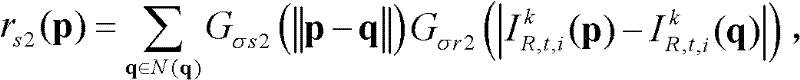 Gσs2(||p-q||)表示标准差为σs2的高斯函数,
Gσs2(||p-q||)表示标准差为σs2的高斯函数,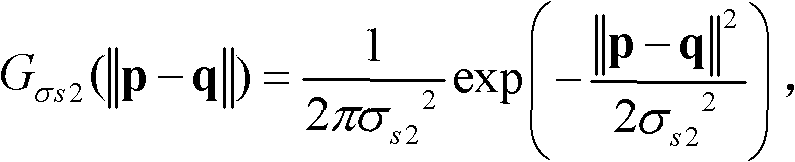
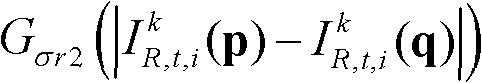 表示标准差为σr2的高斯函数,
表示标准差为σr2的高斯函数,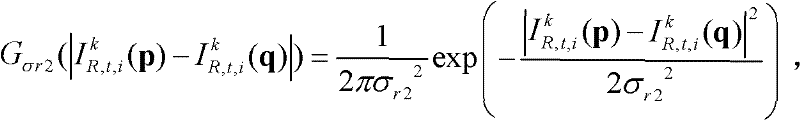 在此标准差(σs2,σr2)的滤波强度大于标准差(σs1,σr1)的滤波强度;
在此标准差(σs2,σr2)的滤波强度大于标准差(σs1,σr1)的滤波强度;
⑥-5、将滤波后的所有场景深度值构成的集合作为滤波后的场景深度集合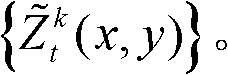
所述的(σs1,σr1)的大小为(1,5),所述的(σs2,σr2)的大小为(10,15)。
所述的步骤⑩的具体过程为:
⑩-1、统计由第k个参考视点绘制得到的虚拟视点图像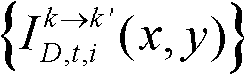 中排除空洞像素点外的正确映射的像素点的总个数,记为num1,分别获取虚拟视点图像
中排除空洞像素点外的正确映射的像素点的总个数,记为num1,分别获取虚拟视点图像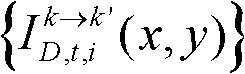 的num1个像素点的第i个分量的均值
的num1个像素点的第i个分量的均值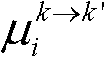 和标准差
和标准差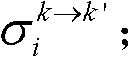
⑩-2、统计由第k+1个参考视点绘制得到的虚拟视点图像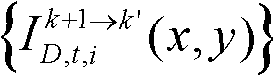 中排除空洞像素点外的正确映射的像素点的总个数,记为mum2,分别获取虚拟视点图像
中排除空洞像素点外的正确映射的像素点的总个数,记为mum2,分别获取虚拟视点图像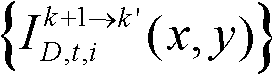 的num2个像素点的第i个分量的均值
的num2个像素点的第i个分量的均值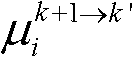 和标准差
和标准差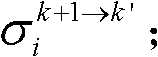
⑩-3、计算由第k个参考视点绘制得到的虚拟视点图像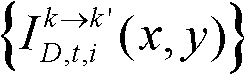 和由第k+1个参考视点绘制得到的虚拟视点图像
和由第k+1个参考视点绘制得到的虚拟视点图像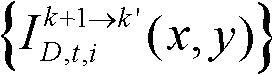 的第i个分量的目标均值和目标标准差,记目标均值为
的第i个分量的目标均值和目标标准差,记目标均值为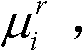 记目标标准差为
记目标标准差为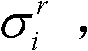
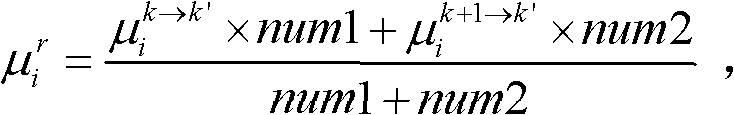
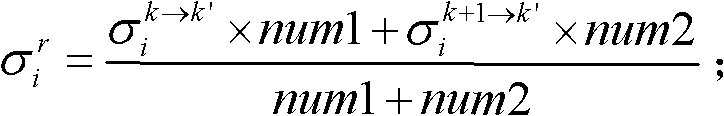
⑩-4、根据目标均值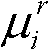 和目标标准差
和目标标准差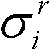 及由第k个参考视点绘制得到的虚拟视点图像
及由第k个参考视点绘制得到的虚拟视点图像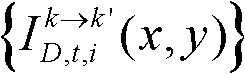 的第i个分量的均值
的第i个分量的均值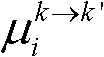 和标准差
和标准差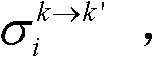 通过
通过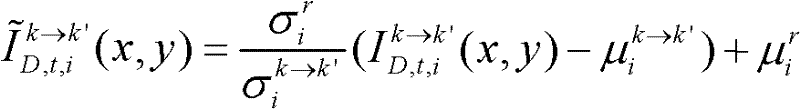 对由第k个参考视点绘制得到的虚拟视点图像
对由第k个参考视点绘制得到的虚拟视点图像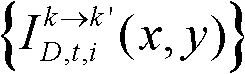 的各个分量进行颜色传递操作得到颜色校正后的虚拟视点图像
的各个分量进行颜色传递操作得到颜色校正后的虚拟视点图像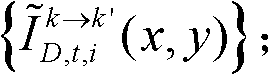
⑩-5、根据目标均值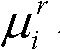 和目标标准差
和目标标准差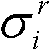 及由第k+1个参考视点绘制得到的虚拟视点图像
及由第k+1个参考视点绘制得到的虚拟视点图像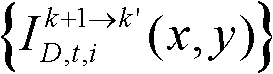 的第i个分量的均值
的第i个分量的均值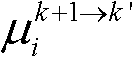 和标准差
和标准差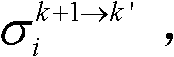 通过
通过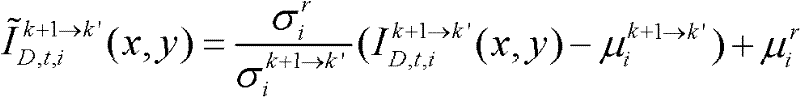 对由第k+1个参考视点绘制得到的虚拟视点图像
对由第k+1个参考视点绘制得到的虚拟视点图像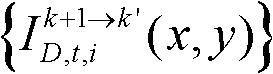 的各个分量进行颜色传递操作得到颜色校正后的虚拟视点图像
的各个分量进行颜色传递操作得到颜色校正后的虚拟视点图像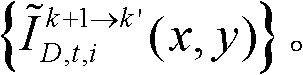
所述的步骤 中的图像融合方法的具体过程为:
中的图像融合方法的具体过程为:
 -1、判断颜色校正后的由第k个参考视点绘制得到的虚拟视点图像
-1、判断颜色校正后的由第k个参考视点绘制得到的虚拟视点图像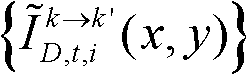 中坐标位置为(x,y)的像素点是否为空洞像素点,如果是,则继续执行,否则,
中坐标位置为(x,y)的像素点是否为空洞像素点,如果是,则继续执行,否则,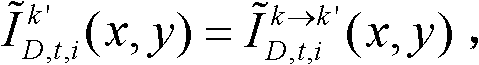 其中,
其中,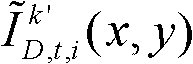 表示融合后的虚拟视点图像
表示融合后的虚拟视点图像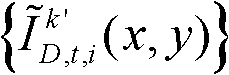 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,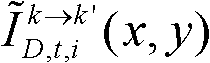 表示颜色校正后的由第k个参考视点绘制得到的虚拟视点图像
表示颜色校正后的由第k个参考视点绘制得到的虚拟视点图像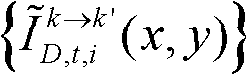 中坐标位置为(x,y)的像素点的第i个分量的值;
中坐标位置为(x,y)的像素点的第i个分量的值;
 -2、判断颜色校正后的由第k+1个参考视点绘制得到的虚拟视点图像
-2、判断颜色校正后的由第k+1个参考视点绘制得到的虚拟视点图像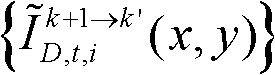 中坐标位置为(x,y)的像素点是否为空洞像素点,如果是,则确定融合后的虚拟视点图像
中坐标位置为(x,y)的像素点是否为空洞像素点,如果是,则确定融合后的虚拟视点图像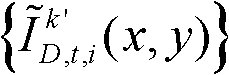 中坐标位置为(x,y)的像素点为空洞像素点,否则,
中坐标位置为(x,y)的像素点为空洞像素点,否则,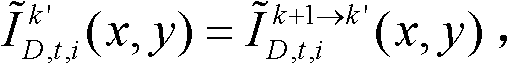 其中,
其中,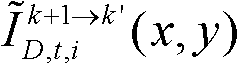 表示颜色校正后的由第k+1个参考视点绘制得到的虚拟视点图像
表示颜色校正后的由第k+1个参考视点绘制得到的虚拟视点图像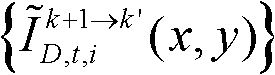 中坐标位置为(x,y)的像素点的第i个分量的值。
中坐标位置为(x,y)的像素点的第i个分量的值。
所述的步骤④中的边缘检测算法采用Susan边缘检测算法。
与现有技术相比,本发明的优点在于:
1)本发明方法根据不同区域的深度编码失真对虚拟视点图像绘制的影响,将深度图像分成核心内容区域和非核心内容区域,并设计两组不同滤波强度的双向滤波器分别对核心内容区域和非核心内容区域的各个像素点对应的场景深度值进行滤波处理,这样大大提高了绘制图像的主观质量。
2)本发明方法针对图像融合过程中出现的颜色失真问题,从虚拟视点彩色图像中提取出与空洞无关的参考颜色信息,并设计不同的颜色校正方法分别对两组虚拟视点彩色图像进行颜色校正,这样大大提高了绘制图像的主观质量。
附图说明
图1为典型的三维视频系统的基本组成框图;
图2为HBP编码预测结构的示意图;
图3a为“Ballet”三维视频测试集的第4个参考视点的一幅彩色图像;
图3b为“Ballet”三维视频测试集的第6个参考视点的一幅彩色图像;
图3c为图3a所示的彩色图像对应的深度图像;
图3d为图3b所示的彩色图像对应的深度图像;
图4a为“Breakdancers”三维视频测试集的第4个参考视点的一幅彩色图像;
图4b为“Breakdancers”三维视频测试集的第6个参考视点的一幅彩色图像;
图4c为图4a所示的彩色图像对应的深度图像;
图4d为图4c所示的彩色图像对应的深度图像;
图5a为“Ballet”三维视频测试集的第4个参考视点的深度图像的核心内容区域;
图5b为“Ballet”三维视频测试集的第6个参考视点的深度图像的核心内容区域;
图5c为“Breakdancers”三维视频测试集的第4个参考视点的深度图像的核心内容区域;
图5d为“Breakdancers”三维视频测试集的第6个参考视点的深度图像的核心内容区域;
图6a为“Ballet”三维视频测试集的第4个参考视点的深度图像;
图6b为“Ballet”三维视频测试集的第4个参考视点的滤波处理后的深度图像;
图6c为图6a与图6b的残差图像;
图7a为“Breakdancers”三维视频测试集的第4个参考视点的深度图像;
图7b为“Breakdancers”三维视频测试集的第4个参考视点的滤波处理后的深度图像;
图7c为图7a与图7b的残差图像;
图8a为“Ballet”三维视频测试集的第4个参考视点绘制得到的虚拟视点图像;
图8b为“Ballet”三维视频测试集的第6个参考视点绘制得到的虚拟视点图像;
图8c为“Breakdancers”三维视频测试集的第4个参考视点绘制得到的虚拟视点图像;
图8d为“Breakdancers”三维视频测试集的第6个参考视点绘制得到的虚拟视点图像;
图9a为“Ballet”三维视频测试集的第5个参考视点采用本发明方法得到的虚拟视点图像;
图9b为“Ballet”三维视频测试集的第5个参考视点不采用本发明方法得到的虚拟视点图像;
图9c为“Ballet”三维视频测试集的第5个参考视点采用本发明方法与不采用本发明方法得到的虚拟视点图像的局部细节放大图;
图10a为“Breakdancers”三维视频测试集的第5个参考视点采用本发明方法后得到的虚拟视点图像;
图10b为“Breakdancers”三维视频测试集的第5个参考视点不采用本发明方法得到的虚拟视点图像;
图10c为“Breakdancers”三维视频测试集的第5个参考视点采用本发明方法与不采用本发明方法得到的虚拟视点图像的局部细节放大图;
图11a为“Ballet”三维视频测试集的第5个参考视点不采用本发明颜色校正处理后得到的虚拟视点图像的局部细节放大图;
图11b为“Ballet”三维视频测试集的第5个参考视点采用本发明颜色校正处理后得到的虚拟视点图像的局部细节放大图;
图11c为“Breakdancers”三维视频测试集的第5个参考视点不采用本发明颜色校正处理后得到的虚拟视点图像的局部细节放大图;
图11d为“Breakdancers”三维视频测试集的第5个参考视点采用本发明颜色校正处理后得到的虚拟视点图像的局部细节放大图。
具体实施方式
以下结合附图实施例对本发明作进一步详细描述。
本发明提出的一种虚拟视点彩色图像绘制方法,其具体包括以下步骤:
①获取t时刻的K个参考视点的K幅颜色空间为YUV的彩色图像及其对应的K幅深度图像,然后在编码端根据设定的编码预测结构分别对t时刻的K个参考视点的K幅颜色空间为YUV的彩色图像及其对应的K幅深度图像进行编码,再将编码后的K幅彩色图像及其对应的K幅深度图像经网络传输给解码端。
在解码端对编码后的K幅彩色图像及其对应的K幅深度图像进行解码,获得解码后的t时刻的K个参考视点的K幅彩色图像及其对应的K幅深度图像。
在本实施中,设定的编码预测结构采用公知的HBP编码预测结构,如图2所示。
②将t时刻的第k个参考视点的彩色图像记为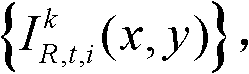 将t时刻的第k个参考视点的深度图像记为
将t时刻的第k个参考视点的深度图像记为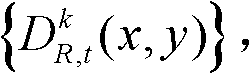 其中,i=1,2,3分别表示YUV颜色空间的三个分量,YUV颜色空间的第1个分量为亮度分量并记为Y、第2个分量为第一色度分量并记为U及第3个分量为第二色度分量并记为V,(x,y)表示彩色图像或深度图像中像素点的坐标位置,1≤k≤K,k的初始值为1,
其中,i=1,2,3分别表示YUV颜色空间的三个分量,YUV颜色空间的第1个分量为亮度分量并记为Y、第2个分量为第一色度分量并记为U及第3个分量为第二色度分量并记为V,(x,y)表示彩色图像或深度图像中像素点的坐标位置,1≤k≤K,k的初始值为1,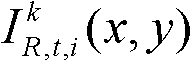 表示t时刻的第k个参考视点的彩色图像
表示t时刻的第k个参考视点的彩色图像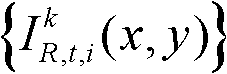 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,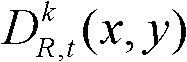 表示t时刻的第k个参考视点的深度图像
表示t时刻的第k个参考视点的深度图像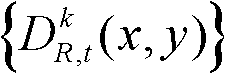 中坐标位置为(x,y)的像素点的深度值。
中坐标位置为(x,y)的像素点的深度值。
在此,采用美国微软公司提供的三维视频测试序列“Ballet”和“Breakdancers”,这两个三维视频测试序列均包括8个参考视点的8幅彩色图像和对应的8幅深度图像,各幅彩色图像和深度图像的分辨率都为1024×768,帧率为15帧每秒,即15fps,这两个三维视频测试序列是ISO/MPEG所推荐的标准测试序列。图3a和图3b分别给出了“Ballet”的第4个和第6个参考视点的彩色图像;图3c和图3d分别给出了“Ballet”的第4个和第6个参考视点的彩色图像所对应的深度图像;图4a和图4b分别给出了“Breakdancers”的第4个和第6个参考视点的彩色图像;图4c和图4d分别给出了“Breakdancers”的第4个和第6个参考视点的彩色图像所对应的深度图像。
③由于深度图像的深度值范围为[0,255],不同的场景深度由于被量化成整数型的深度值而产生一定的量化误差,为了避免这一量化误差对后期虚拟视点图像绘制的影响,将t时刻的第k个参考视点的深度图像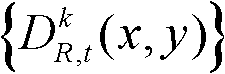 从二维图像平面投影到三维场景平面,得到t时刻的第k个参考视点的深度图像
从二维图像平面投影到三维场景平面,得到t时刻的第k个参考视点的深度图像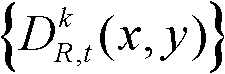 对应的场景深度集合,记为
对应的场景深度集合,记为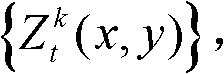
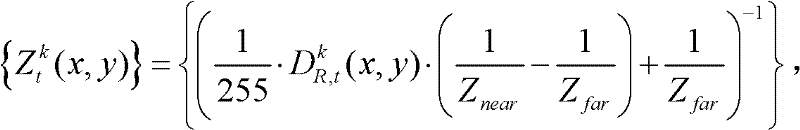 其中,
其中,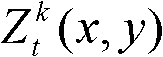 表示t时刻的第k个参考视点的深度图像
表示t时刻的第k个参考视点的深度图像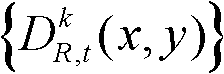 对应的场景深度集合
对应的场景深度集合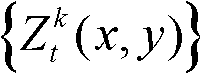 中坐标位置为(x,y)的像素点的场景深度值,Znear表示最小的场景深度值,Zfar表示最大的场景深度值。
中坐标位置为(x,y)的像素点的场景深度值,Znear表示最小的场景深度值,Zfar表示最大的场景深度值。
在本实施例中,“Ballet”三维视频测试集的Znear和Zfar分别为42和130,“Breakdancers”三维视频测试集的Znear和Zfar分别为44和120。
④根据深度图像的失真对绘制的影响分析结果,深度图像的边缘失真对后期虚拟视点图像绘制的影响最大,可知边缘是需要重点保护的区域,并且根据人眼对视觉注意力的敏感度分析,前景对象比背景对象更容易受到关注,人眼对前景的失真也较为敏感,前景也是需要重点保护的区域,因此本发明将深度图像的边缘区域和前景区域作为深度图像的核心内容区域。采用公知的Susan边缘检测算法对t时刻的第k个参考视点的深度图像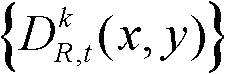 进行边缘检测,获得边缘分割图像,记为
进行边缘检测,获得边缘分割图像,记为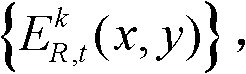 其中,边缘分割图像
其中,边缘分割图像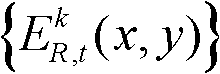 包括边缘区域;对t时刻的第k个参考视点的深度图像
包括边缘区域;对t时刻的第k个参考视点的深度图像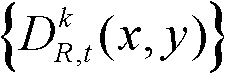 进行前景和背景的分离处理,得到前背景分离图像,记为
进行前景和背景的分离处理,得到前背景分离图像,记为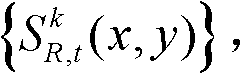 其中,前背景分离图像
其中,前背景分离图像 包括前景区域和背景区域。
包括前景区域和背景区域。
在此具体实施例中,对t时刻的第k个参考视点的深度图像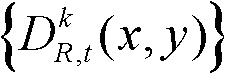 进行前景和背景的分离处理的具体过程为:
进行前景和背景的分离处理的具体过程为:
④-1、采用公知的k-mean算法对t时刻的第k个参考视点的深度图像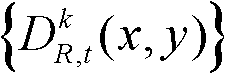 进行聚类操作,得到初始的聚类中心;
进行聚类操作,得到初始的聚类中心;
④-2、根据初始的聚类中心,采用期望最大(Expectation-Maximization)算法估计t时刻的第k个参考视点的深度图像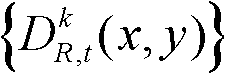 的高斯混合模型,记为Θ,
的高斯混合模型,记为Θ,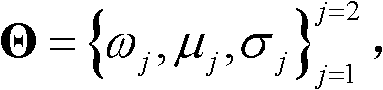 其中,j表示高斯混合模型Θ中的第j个高斯分量,j=1代表前景,j=2代表背景,ωj表示第j个高斯分量的加权系数,μj表示第j个高斯分量的均值,σj表示第j个高斯分量的标准差;
其中,j表示高斯混合模型Θ中的第j个高斯分量,j=1代表前景,j=2代表背景,ωj表示第j个高斯分量的加权系数,μj表示第j个高斯分量的均值,σj表示第j个高斯分量的标准差;
④-3、采用最大化概率密度函数分别获取t时刻的第k个参考视点的深度图像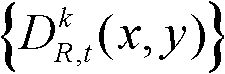 中的各个像素点属于高斯混合模型Θ中的第j个高斯分量的分类标记,记为γ(x,y),
中的各个像素点属于高斯混合模型Θ中的第j个高斯分量的分类标记,记为γ(x,y),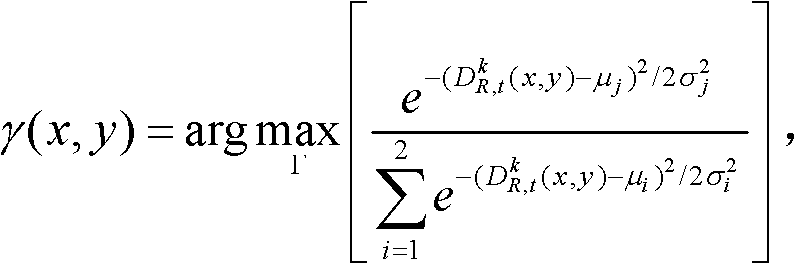 其中,1≤j≤2,γ(x,y)∈[1,2],Γ表示高斯混合模型Θ中的所有高斯分量的集合,Γ={j|1≤j≤2},
其中,1≤j≤2,γ(x,y)∈[1,2],Γ表示高斯混合模型Θ中的所有高斯分量的集合,Γ={j|1≤j≤2},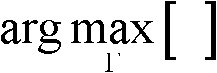 表示最大化概率密度函数,μi表示第i个高斯分量的均值,σi表示第i个高斯分量的标准差;
表示最大化概率密度函数,μi表示第i个高斯分量的均值,σi表示第i个高斯分量的标准差;
④-4、将t时刻的第k个参考视点的深度图像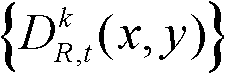 中分类标记的值为1的所有像素点构成的区域作为t时刻的第k个参考视点的深度图像
中分类标记的值为1的所有像素点构成的区域作为t时刻的第k个参考视点的深度图像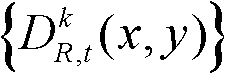 的前景区域,将t时刻的第k个参考视点的深度图像
的前景区域,将t时刻的第k个参考视点的深度图像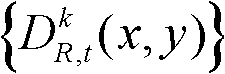 中分类标记的值为2的所有像素点构成的区域作为t时刻的第k个参考视点的深度图像
中分类标记的值为2的所有像素点构成的区域作为t时刻的第k个参考视点的深度图像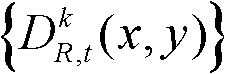 的背景区域,得到前背景分离图像
的背景区域,得到前背景分离图像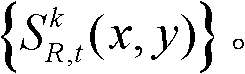
⑤根据边缘分割图像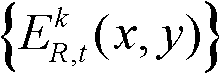 和前背景分离图像
和前背景分离图像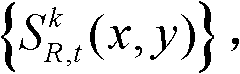 将t时刻的第k个参考视点的深度图像
将t时刻的第k个参考视点的深度图像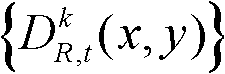 分割成核心内容区域和非核心内容区域。
分割成核心内容区域和非核心内容区域。
在此具体实施例中,核心内容区域和非核心内容区域的分割过程为:
⑤-1、定义t时刻的第k个参考视点的深度图像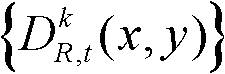 中当前正在处理的像素点为当前像素点;
中当前正在处理的像素点为当前像素点;
⑤-2、判断当前像素点是否属于前背景分离图像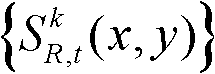 的前景区域或边缘分割图像
的前景区域或边缘分割图像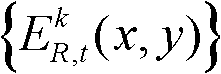 的边缘区域,如果是,则确定当前像素点为核心内容,否则,确定当前像素点为非核心内容;
的边缘区域,如果是,则确定当前像素点为核心内容,否则,确定当前像素点为非核心内容;
⑤-3、将t时刻的第k个参考视点的深度图像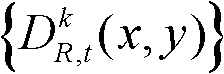 中下一个待处理的像素点作为当前像素点,然后执行步骤⑤-2和⑤-3,直至t时刻的第k个参考视点的深度图像
中下一个待处理的像素点作为当前像素点,然后执行步骤⑤-2和⑤-3,直至t时刻的第k个参考视点的深度图像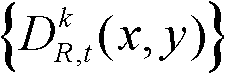 中所有像素点处理完毕,将所有核心内容构成的区域作为核心内容区域,将所有非核心内容构成的区域作为非核心内容区域。
中所有像素点处理完毕,将所有核心内容构成的区域作为核心内容区域,将所有非核心内容构成的区域作为非核心内容区域。
分别对“Ballet”和“Breakdancers”三维视频测试集的第4个参考视点和第6个参考视点的深度图像进行边缘检测及前景和背景分离处理实验,图5a和图5b分别给出了“Ballet”的第4个和第6个参考视点的深度图像的核心内容区域,图5c和图5d分别给出了“Breakdancers”的第4个和第6个参考视点的深度图像的核心内容区域,从图5a至图5d可以看出,采用本发明提取的核心内容区域基本符合人眼视觉的特性。
⑥利用两组不同滤波强度的双向滤波器分别对场景深度集合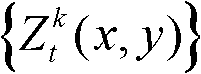 中与t时刻的第k个参考视点的深度图像
中与t时刻的第k个参考视点的深度图像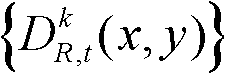 的核心内容区域和非核心内容区域中的各个像素点对应的场景深度值进行滤波处理,得到滤波后的场景深度集合,记为
的核心内容区域和非核心内容区域中的各个像素点对应的场景深度值进行滤波处理,得到滤波后的场景深度集合,记为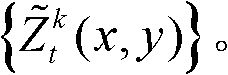
由于深度图像整体非常平滑,对深度图像进行滤波处理,要求在平滑深度信息的同时能很好地保留边缘轮廓信息,双向滤波器(bilateral filter)是一种非线性滤波器,能有效地将噪声平滑化且又可以把重要的边界保留,其主要原理是同时在空间域(spatialdomain)和强度域(intensity domain)做高斯平滑化(Gaussian smoothing)处理。由于深度图像与彩色图像之间存在较强的相关性,深度图像与彩色图像的运动对象及运动对象边界是一致的,但彩色图像包含更加丰富的纹理信息,以彩色图像作为强度域信息来辅助深度图像的滤波,有利于保留重要的运动对象边界信息。通过分析,本发明提出的滤波处理的具体过程为:
⑥-1、定义t时刻的第k个参考视点的深度图像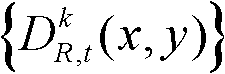 中当前正在处理的像素点为当前像素点,将当前像素点的坐标位置记为p,将当前像素点的邻域像素点的坐标位置记为q,定义双向滤波器为
中当前正在处理的像素点为当前像素点,将当前像素点的坐标位置记为p,将当前像素点的邻域像素点的坐标位置记为q,定义双向滤波器为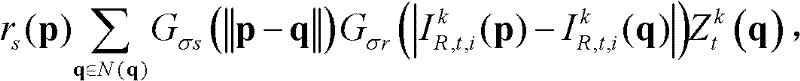 其中,
其中,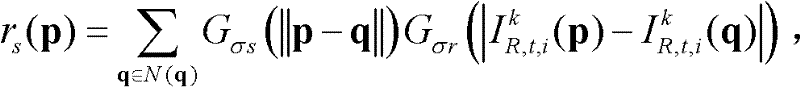 Gσs(||-q||)表示标准差为σs的高斯函数,
Gσs(||-q||)表示标准差为σs的高斯函数,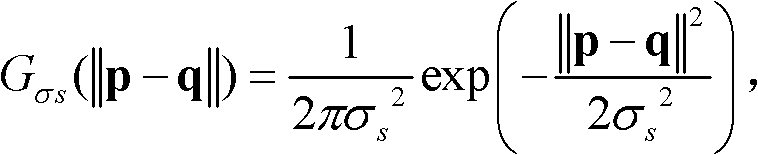
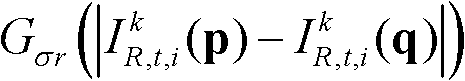 表示标准差为σr的高斯函数,
表示标准差为σr的高斯函数,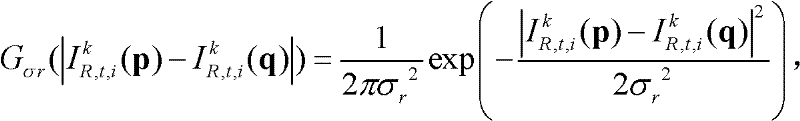 ||p-q||表示坐标位置p和坐标位置q之间的欧拉距离,
||p-q||表示坐标位置p和坐标位置q之间的欧拉距离,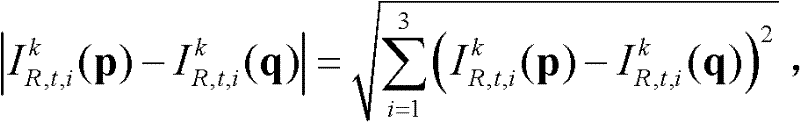
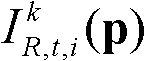 表示t时刻的第k个参考视点的彩色图像
表示t时刻的第k个参考视点的彩色图像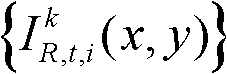 中坐标位置为p的像素点的第i个分量的值,
中坐标位置为p的像素点的第i个分量的值,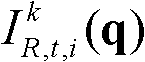 表示t时刻的第k个参考视点的彩色图像
表示t时刻的第k个参考视点的彩色图像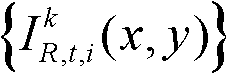 中坐标位置为q的像素点的第i个分量的值,
中坐标位置为q的像素点的第i个分量的值,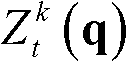 表示场景深度集合
表示场景深度集合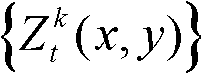 中坐标位置为q的像素点的场景深度值,N(q)表示以坐标位置为q的像素点为中心的3×3邻域窗口;
中坐标位置为q的像素点的场景深度值,N(q)表示以坐标位置为q的像素点为中心的3×3邻域窗口;
⑥-2、判断当前像素点是否属于t时刻的第k个参考视点的深度图像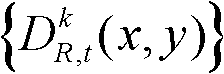 的核心内容区域,如果是,则执行步骤⑥-3,否则,执行步骤⑥-4;
的核心内容区域,如果是,则执行步骤⑥-3,否则,执行步骤⑥-4;
⑥-3、采用标准差为(σs1,σr1)的双向滤波器对当前像素点的坐标位置为q的邻域像素点的场景深度值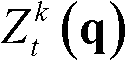 进行滤波操作,得到当前像素点p的滤波后的场景深度值
进行滤波操作,得到当前像素点p的滤波后的场景深度值
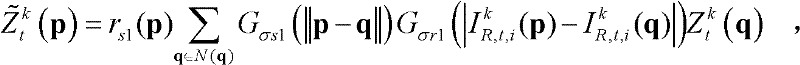 其中,
其中, Gσs1(||p-q||)表示标准差为σs1的高斯函数,
Gσs1(||p-q||)表示标准差为σs1的高斯函数,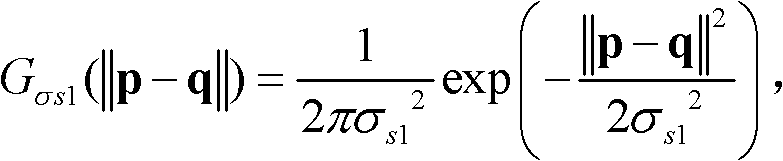
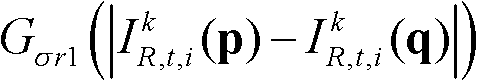 表示标准差为σr1的高斯函数,
表示标准差为σr1的高斯函数,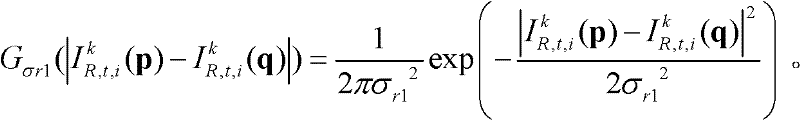 在此,标准差(σs1,σr1)采用一组滤波强度较小的标准差,如(σs1,σr1)的大小可为(1,5);
在此,标准差(σs1,σr1)采用一组滤波强度较小的标准差,如(σs1,σr1)的大小可为(1,5);
⑥-4、采用标准差为(σs2,σr2)的双向滤波器对当前像素点的坐标位置为q的邻域像素点的场景深度值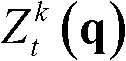 进行滤波操作,得到当前像素点p的滤波后的场景深度值
进行滤波操作,得到当前像素点p的滤波后的场景深度值
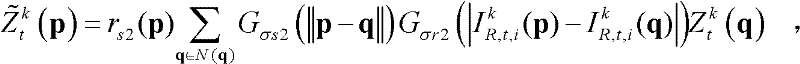 其中,
其中,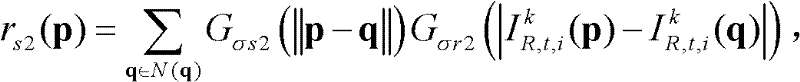 Gσs2(||p-q||)表示标准差为σs2的高斯函数,
Gσs2(||p-q||)表示标准差为σs2的高斯函数,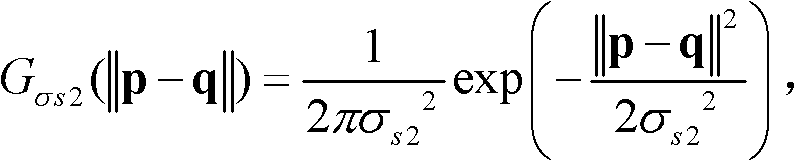
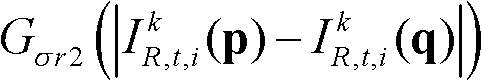 表示标准差为σr2的高斯函数,
表示标准差为σr2的高斯函数,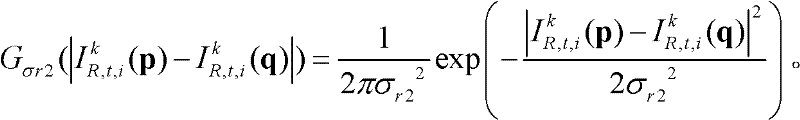 标准差(σs2,σr2)采用一组滤波强度较大的标准差,如(σs2,σr2)的大小可为(10,15);
标准差(σs2,σr2)采用一组滤波强度较大的标准差,如(σs2,σr2)的大小可为(10,15);
⑥-5、将滤波后的所有场景深度值构成的集合作为滤波后的场景深度集合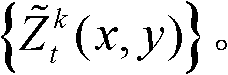
对“Ballet”和“Breakdancers”三维视频测试集的深度图像的核心内容区域和非核心内容区域中各个像素点对应的场景深度值进行滤波处理实验,图6a和图6b分别给出了“Ballet”的第4个参考视点的深度图像和滤波处理后的深度图像,图6c给出了图6a与图6b的残差图像;图7a和图7b分别给出了“Breakdancers”的第4个参考视点的深度图像和滤波处理后的深度图像,图7c给出了图7a与图7b的残差图像,从图6b和图7b可以看出,采用本发明得到滤波处理后的深度图像,保持了深度图像的重要的几何特征,产生了令人满意的锐利的边缘和平滑的轮廓。
⑦将滤波后的场景深度集合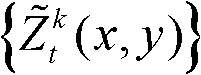 从三维场景平面重新投影到二维图像平面,得到t时刻的第k个参考视点的深度滤波图像,记为
从三维场景平面重新投影到二维图像平面,得到t时刻的第k个参考视点的深度滤波图像,记为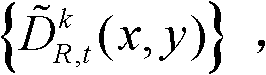
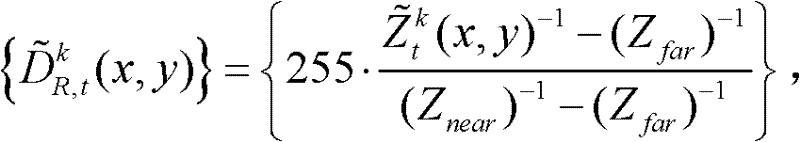 其中,
其中,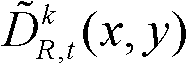 表示t时刻的第k个参考视点的深度滤波图像
表示t时刻的第k个参考视点的深度滤波图像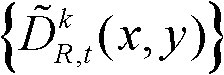 中坐标位置为(x,y)的像素点的深度值,
中坐标位置为(x,y)的像素点的深度值,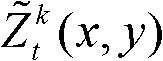 表示滤波后的场景深度集合
表示滤波后的场景深度集合 中坐标位置为(x,y)的像素点的场景深度值,Znear表示最小的场景深度值,Zfar表示最大的场景深度值。
中坐标位置为(x,y)的像素点的场景深度值,Znear表示最小的场景深度值,Zfar表示最大的场景深度值。
⑧令k′=k+1,k=k′,重复执行步骤②至⑧直至得到t时刻的K个参考视点的K幅深度滤波图像,K幅深度滤波图像用集合表示为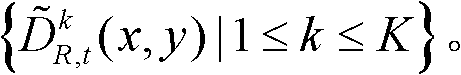
⑨假定当前需绘制的是第k′个虚拟视点,从t时刻的K个参考视点中选择两个与第k′个虚拟视点最相邻的参考视点,假定这两个参考视点分别为第k个参考视点和第k+1个参考视点,将由第k个参考视点绘制得到的第k′个虚拟视点的虚拟视点图像记为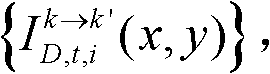 将由第k+1个参考视点绘制得到的第k′个虚拟视点的虚拟视点图像记为
将由第k+1个参考视点绘制得到的第k′个虚拟视点的虚拟视点图像记为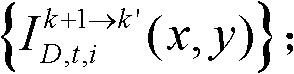 首先利用t时刻的第k个参考视点的深度图像
首先利用t时刻的第k个参考视点的深度图像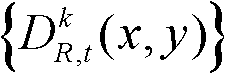 所提供的深度信息,然后采用公知的三维图像变换方法逐像素点计算t时刻的第k个参考视点的彩色图像
所提供的深度信息,然后采用公知的三维图像变换方法逐像素点计算t时刻的第k个参考视点的彩色图像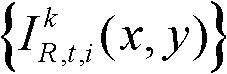 中的各个像素点在当前需绘制的第k′个虚拟视点的虚拟视点图像
中的各个像素点在当前需绘制的第k′个虚拟视点的虚拟视点图像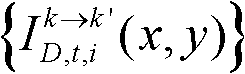 中的坐标位置,得到t时刻的第k个参考视点的彩色图像
中的坐标位置,得到t时刻的第k个参考视点的彩色图像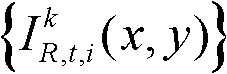 中的各个像素点映射到当前需绘制的第k′个虚拟视点的虚拟视点图像
中的各个像素点映射到当前需绘制的第k′个虚拟视点的虚拟视点图像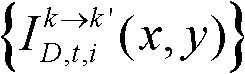 的坐标映射关系,再利用该坐标映射关系将t时刻的第k个参考视点的彩色图像
的坐标映射关系,再利用该坐标映射关系将t时刻的第k个参考视点的彩色图像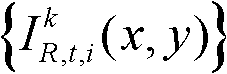 中的各个像素点映射到当前需绘制的第k′个虚拟视点的虚拟视点图像
中的各个像素点映射到当前需绘制的第k′个虚拟视点的虚拟视点图像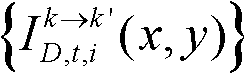 中。采用与由第k个参考视点绘制得到的虚拟视点图像
中。采用与由第k个参考视点绘制得到的虚拟视点图像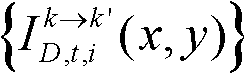 相同的方法,将第k+1个参考视点的彩色图像
相同的方法,将第k+1个参考视点的彩色图像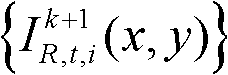 中的各个像素点映射到需绘制的第k′个虚拟视点的虚拟视点图像
中的各个像素点映射到需绘制的第k′个虚拟视点的虚拟视点图像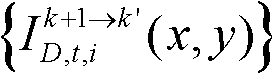 中。
中。
在本实施例中,设定当前需绘制的虚拟视点为第5个虚拟视点,图8a给出了“Ballet”的第4个参考视点绘制得到的虚拟视点图像,图8b给出了“Ballet”的第6个参考视点绘制得到的虚拟视点图像,图8c给出了“Breakdancers”的第4个参考视点绘制得到的虚拟视点图像,图8d给出了“Breakdancers”的第6个参考视点绘制得到的虚拟视点图像,从图8a至图8d可以看出,采用基于深度图像的绘制(Depth Image Based Rendering,DIBR)方法绘制得到的虚拟视点图像会有较多的空洞像素点,需要采用图像融合和空洞填补方法进行进一步的处理。
⑩分别对由第k个参考视点绘制得到的虚拟视点图像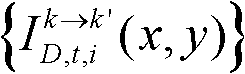 和由第k+1个参考视点绘制得到的虚拟视点图像
和由第k+1个参考视点绘制得到的虚拟视点图像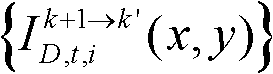 进行颜色传递操作,得到颜色校正后的由第k个参考视点绘制得到的虚拟视点图像和由第k+1个参考视点绘制得到的虚拟视点图像,分别记为
进行颜色传递操作,得到颜色校正后的由第k个参考视点绘制得到的虚拟视点图像和由第k+1个参考视点绘制得到的虚拟视点图像,分别记为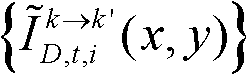 和
和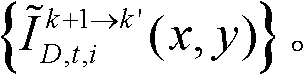
根据多视点成像的特点,同一像素点在不同的虚拟视点图像的颜色会完全不一致,导致在图像融合过程会出现颜色失真现象。由于虚拟视点图像包含较多的空洞像素点,对虚拟视点图像进行颜色校正的关键是提取与空洞无关的参考颜色信息。通过分析,本发明提出的对虚拟视点图像进行颜色校正的具体过程为:
⑩-1、统计由第k个参考视点绘制得到的虚拟视点图像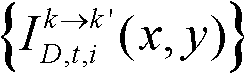 中排除空洞像素点外的正确映射的像素点的总个数,记为num1,分别获取虚拟视点图像
中排除空洞像素点外的正确映射的像素点的总个数,记为num1,分别获取虚拟视点图像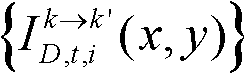 的num1个像素点的第i个分量的均值
的num1个像素点的第i个分量的均值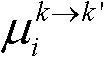 和标准差
和标准差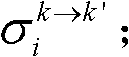
⑩-2、统计由第k+1个参考视点绘制得到的虚拟视点图像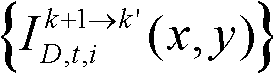 中排除空洞像素点外的正确映射的像素点的总个数,记为num2,分别获取虚拟视点图像
中排除空洞像素点外的正确映射的像素点的总个数,记为num2,分别获取虚拟视点图像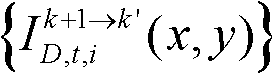 的num2个像素点的第i个分量的均值
的num2个像素点的第i个分量的均值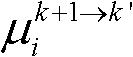 和标准差
和标准差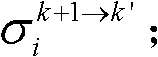
⑩-3、计算由第k个参考视点绘制得到的虚拟视点图像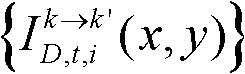 和由第k+1个参考视点绘制得到的虚拟视点图像
和由第k+1个参考视点绘制得到的虚拟视点图像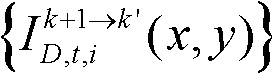 的第i个分量的目标均值和目标标准差,记目标均值为
的第i个分量的目标均值和目标标准差,记目标均值为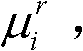 记目标标准差为
记目标标准差为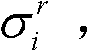
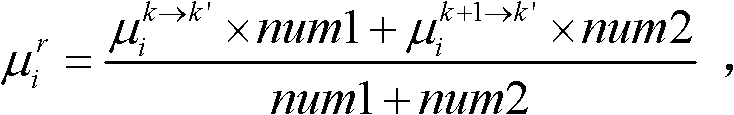
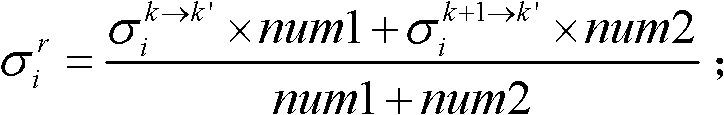
⑩-4、根据目标均值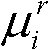 和目标标准差
和目标标准差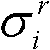 及由第k个参考视点绘制得到的虚拟视点图像
及由第k个参考视点绘制得到的虚拟视点图像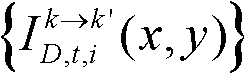 的第i个分量的均值
的第i个分量的均值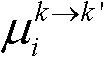 和标准差
和标准差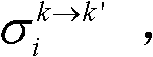 通过
通过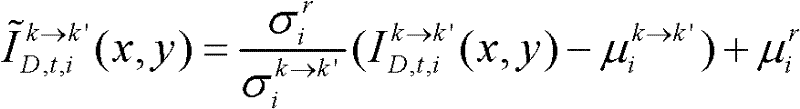 对由第k个参考视点绘制得到的虚拟视点图像
对由第k个参考视点绘制得到的虚拟视点图像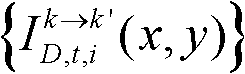 的各个分量进行颜色传递操作得到颜色校正后的虚拟视点图像
的各个分量进行颜色传递操作得到颜色校正后的虚拟视点图像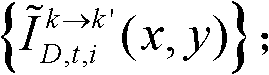
⑩-5、根据目标均值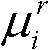 和目标标准差
和目标标准差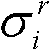 及由第k+1个参考视点绘制得到的虚拟视点图像
及由第k+1个参考视点绘制得到的虚拟视点图像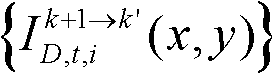 的第i个分量的均值
的第i个分量的均值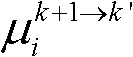 和标准差
和标准差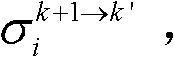 通过
通过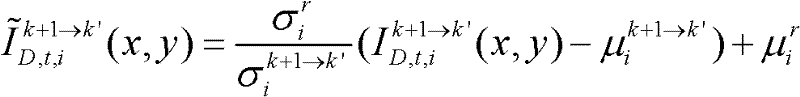 对由第k+1个参考视点绘制得到的虚拟视点图像
对由第k+1个参考视点绘制得到的虚拟视点图像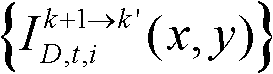 的各个分量进行颜色传递操作得到颜色校正后的虚拟视点图像
的各个分量进行颜色传递操作得到颜色校正后的虚拟视点图像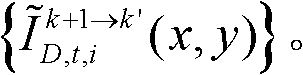
 采用图像融合方法融合颜色校正后的由第k个参考视点绘制得到的虚拟视点图像
采用图像融合方法融合颜色校正后的由第k个参考视点绘制得到的虚拟视点图像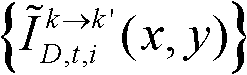 和颜色校正后的由第k+1个参考视点绘制得到的虚拟视点图像
和颜色校正后的由第k+1个参考视点绘制得到的虚拟视点图像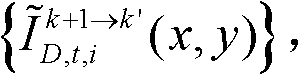 得到融合后的虚拟视点图像,记为
得到融合后的虚拟视点图像,记为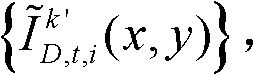 并对融合后的虚拟视点图像
并对融合后的虚拟视点图像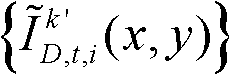 中的空洞像素点进行填补,得到最终的虚拟视点图像,记为{ID,t,i(x,y)}。
中的空洞像素点进行填补,得到最终的虚拟视点图像,记为{ID,t,i(x,y)}。
在此具体实施例中,图像融合方法的具体过程为:
 -1、判断颜色校正后的由第k个参考视点绘制得到的虚拟视点图像
-1、判断颜色校正后的由第k个参考视点绘制得到的虚拟视点图像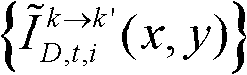 中坐标位置为(x,y)的像素点是否为空洞像素点,如果是,则继续执行,否则,
中坐标位置为(x,y)的像素点是否为空洞像素点,如果是,则继续执行,否则,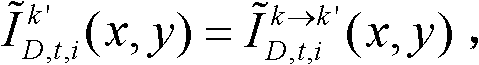 其中,
其中,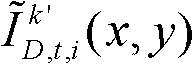 表示融合后的虚拟视点图像
表示融合后的虚拟视点图像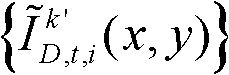 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,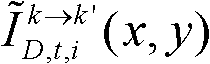 表示颜色校正后的由第k个参考视点绘制得到的虚拟视点图像
表示颜色校正后的由第k个参考视点绘制得到的虚拟视点图像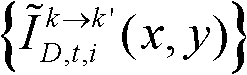 中坐标位置为(x,y)的像素点的第i个分量的值;
中坐标位置为(x,y)的像素点的第i个分量的值;
 -2、判断颜色校正后的由第k+1个参考视点绘制得到的虚拟视点图像
-2、判断颜色校正后的由第k+1个参考视点绘制得到的虚拟视点图像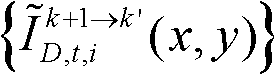 中坐标位置为(x,y)的像素点是否为空洞像素点,如果是,则确定融合后的虚拟视点图像
中坐标位置为(x,y)的像素点是否为空洞像素点,如果是,则确定融合后的虚拟视点图像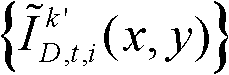 中坐标位置为(x,y)的像素点为空洞像素点,否则,
中坐标位置为(x,y)的像素点为空洞像素点,否则,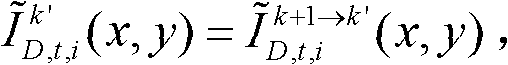 其中,
其中,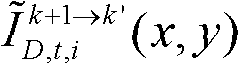 表示颜色校正后的由第k+1个参考视点绘制得到的虚拟视点图像
表示颜色校正后的由第k+1个参考视点绘制得到的虚拟视点图像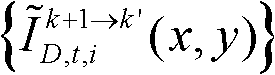 中坐标位置为(x,y)的像素点的第i个分量的值。
中坐标位置为(x,y)的像素点的第i个分量的值。
 重复执行步骤⑨至
重复执行步骤⑨至 直至得到K个虚拟视点的K幅虚拟视点图像。
直至得到K个虚拟视点的K幅虚拟视点图像。
以下就利用本发明方法对“Ballet”、“Breakdancers”三维视频测试集进行虚拟视点图像绘制的主观和客观性能进行比较。
将采用本发明方法得到的虚拟视点图像,与不采用本发明方法得到的虚拟视点图像进行比较。图9a和图9b分别给出了“Ballet”三维视频测试集的第5个参考视点采用本发明得到的虚拟视点图像和不采用本发明方法得到的虚拟视点图像,图9c为图9a和图9b的局部细节放大图;图10a和图10b分别给出了“Breakdancers”三维视频测试集的第5个参考视点采用本发明方法得到的虚拟视点图像和不采用本发明方法得到的虚拟视点图像,图10c为图10a和图10b的局部细节放大图。从图9a至图10c可以看出,采用本发明方法得到的虚拟视点图像能够保持更好的对象轮廓信息,从而降低了由于深度图像的失真引起的映射过程中产生的背景对前景的覆盖,并且对背景区域进行强度较大的滤波平滑处理,能够有效地消除绘制的虚拟视点图像中的条纹噪声。
将采用本发明颜色校正处理与不采用本发明颜色校正处理后得到的虚拟视点图像进行比较。图11a给出了“Ballet”三维视频测试集的第5个参考视点不采用本发明颜色校正处理后得到的虚拟视点彩色图像的局部细节放大图,图11b给出了“Ballet”三维视频测试集的第5个参考视点采用本发明颜色校正处理后得到的虚拟视点彩色图像的局部细节放大图,图11c给出了“Breakdancers”三维视频测试集的第5个参考视点不采用本发明颜色校正处理后得到的虚拟视点彩色图像的局部细节放大图,图11d给出了“Breakdancers”三维视频测试集的第5个参考视点采用本发明颜色校正处理后得到的虚拟视点彩色图像的局部细节放大图,从图11a和图11c可以看出,图像融合过程中出现的颜色失真主要出现在虚拟视点图像的空洞像素点位置,采用本发明的颜色校正处理后得到的虚拟视点图像能够有效地消除颜色失真问题,如图11b和图11d所示,使得最终的虚拟视点图像质量更加自然。
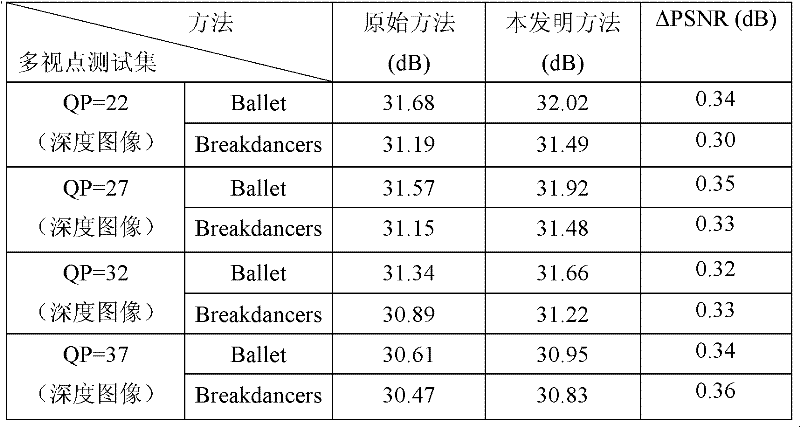
使用本发明方法对不同编码质量的深度图像进行处理,与不采用本发明方法的绘制性能进行比较,比较结果如表1所示,深度图像的量化步长baseQP=22、27、32、37,求得的虚拟视点图像与原始未压缩的彩色图像的峰值信噪比(Peak Signal to Noise Ratio,PSNR)。从表1中可以看出,对“Ballet”三维视频测试序列采用本发明方法后,平均PSNR能够提高0.30dB以上,对“Breakdancers”三维视频测试序列采用本发明方法后,平均PSNR也能提高0.30dB以上,足以说明本发明方法是有效可行的。
表1采用本发明后处理与不采用本发明后处理的绘制性能比较

 手机二维码
手机二维码 京公网安备11011302007134
京公网安备11011302007134